📚 seq2seq (sequence to sequence) 방식의 한계점
트랜스포머 등장 전에는 순환신경망을 기반으로 한 인코더/디코더 모형인 seq2seq이 많이 사용되었다. seq2seq은 하나의 시퀀스 데이터에서(인코더) 또 다른 시퀀스 데이터(디코더)를 생성하는 모델이다. (ex. 한국어 -> 영어로 번역)

Encoder : 입력된 텍스트 데이터를 숫자 혹은 벡터 형태로 변환한다. 최종적으로 가장 마지막에 출력되는 h4를 디코더 부분으로 전달하는데, h4에는 h1~h3까지의 정보가 순차적으로 포함되어 있으므로 순서를 반영할 수 있다고 본다.
Decoder : 인코더에 의해 숫자로 변경된 정보를 다른 형태의 텍스트 데이터로 변환한다.
예를 들어, '오늘은 금요일 입니다' 라는 시퀀스 데이터를 'Today is Friday'로 번역한다고 하면 아래와 같이 표현할 수 있다.

위의 RNN 신경망 전체를 하나의 인코더로 볼 수 있다. 최종적으로 출력하는 h2 값이 디코더로 전달된다.

디코더는 벡터정보를 입력받고 영어로 변환하는 언어모델(language model)의 역할을 한다. 입력받은 단어 정보에서 새로운 도메인에서 나올 값을 예측한다.
디코더 RNN의 첫 번째 층에는 두 가지 정보가 입력된다.
1. 한글 텍스트를 인코딩한 정보 (h2)
2. 문장의 시작을 알리는 역할을 하는 토큰 (=문장 시작 기호 = SOS(Start of Sequence))
y0은 첫 번째 출력층인데 n 개의 단어 중에서 각 단어가 나타날 확률이 노드별로 출력된다. 이를 바탕으로 'Today'를 예측한다.
✔ 순환신경망 방식의 문제점
인코더에서 디코더로 넘어가는 h2 벡터는 해당 단계에서 입력된 '입니다' 단어에 대한 정보를 가장 많이 가지고 있다. 즉, 앞에서 입력된 '오늘은', '금요일'에 대한 정보는 적게 포함되어 있다. 따라서 h2를 디코더로 넘길 경우에 앞선 단어에 대한 정보가 올바르게 포함되지 않는다. 따라서 이러한 문제를 해결하기 위해서는 h0, h1 벡터의 정보를 모두 디코더로 넘길 필요가 있다.
즉, 하나의 고정된 벡터 v에 입력된 문장의 정보가 모두 입력되어야 하므로 성능이 저하된다.
📚 Attention 개념

위 문제를 해결하기 위해서 인코더의 각 층에서 생성되는 단어에 대한 hidden state vector의 정보를 모두 디코더로 전달한다. 하지만 모든 히든 벡터를 정보를 똑같은 비중으로 전달하는 게 아니라, 예측하고자 하는 단어와의 관련이 높은 히든 벡터의 정보를 더 중요하게 전달해야 한다. 예를 들어, 'Today'를 번역하는 과정에서 '오늘은'에서 전달된 h0에 더 많은 주의(attention)를 기울인다. attention은 '인코더의 각 단어 벡터에 신경을 쓰는 정도'로 정의할 수 있고, 0~1 사이의 가중치로 표현한다.

attention이 포함된 디코더의 구조는 위와 같다.
✅ Encoder-Decoder Attention 이란
예시)
'오늘은 금요일 입니다' --> 'Today is Friday' 로 번역하는 경우
<encoder 부분>
인코더에는 '오늘은', '금요일', '입니다' 에 대한 단어 임베딩 벡터의 정보가 입력되고, 그 결과로 각 단어의 hidden state정보인 h0, h1, h2가 출력된다.

<decoder 부분>

인코더에서 넘어온 hidden state가 각 attention 에 입력된다. 그리고 hs의 각 원소에 대해서 가중치를 부여한다.

번역과정에서 'Today'를 예측한다고 할 때, 한국어 '오늘은'의 hidden state 는 h0이다. 벡터의 원소 값은 임의로 설정했다. 'Today'를 예측하는 경우에는 '오늘은' 에 대한 가중치가 높게 설정되야 한다.

h0에 더 많은 가중치친 0.8을 부여해서 원소마다 곱한다. 동일한 작업을 h1, h2의 각 가중치에 대해서도 실시한다.

attention이 출력하는 값은 가중치가 계산된 벡터들을 모두 더한 값이다. 이 벡터는 '오늘은' 에 대한 정보가 1.8로 가장 많이 포함되어 있다.
✅ Attention이 가중치를 계산하는 방법
단어간의 유사도는 각 벡터의 내적 연산을 통해서 계산한다. 즉 유사도가 클수록 내적 값이 크게 나타난다.
→ (decoder가 예측하려는 단어의 hidden state) x (encoder에서 전달받은 단어들의 hidden state)
예를 들어, 'Today'에 대한 hidden state인 h_d,0 이 다음과 같이 표현될 때

인코더에서 넘어오는 값인 h0, h1, h2와의 내적 연산을 수행하면 다음과 같다.

이 값을 Attention Score라고 부른며, 값이 클수록 예측하고자 하는 'Today'와 관련도가 높다고 볼 수 있다.
그리고 가중치를 확률 값으로 표현하기 위해서 attention score에 softmax 함수를 적용한다.

attention score=5인 경우의 가중치는 0.8로 계산된다. (위의 예시에서 곱한 가중치 값과 동일함)

attention score=3 인 경우의 가중치는 0.1로 훨씬 작게 계산된다.

그리고 최종적으로 Attention 에서 출력하는 값과, RNN층에서 출력하는 값(hd,0)을 concat 해서 전달한다.
📚 트랜스포머의 Self-Attention
✅ Encoder-decoder attention과의 차이
encoder-decoder attention에서는 인코더에서 디코더로 넘어오는 정보에 가중치를 부여하는 방식으로 작동하면서 hidden state를 사용한다. 반면, self attention은 입력되는 텍스트 데이터 내의 단어들끼리 서로의 간의 관계를 파악하기 위해서 입력되는 단어의 임베딩 벡터를 사용한다.
예시)
입력 시퀀스 ='Today is Monday'
각 단어의 임베딩 벡터가 아래와 같이 5차원 형태라고 가정
이 상태에서 'Monday'에 대한 self-attention 결과를 얻고자 하는 경우

✅ 계산 순서
1. Attention score 계산 : 'Monday'에 대한 임베딩 벡터와 다른 단어들의 벡터 간의 내적 연산 수행
2. 가중치 계산 : attention score를 가중치로 변환하기 위해서 softmax() 함수 사용

Attention score를 계산하기 위해서 Monday에 대한 임베딩 벡터와 다른 단어들 간의 내적 연산을 수행함. 위 결과는 'Monday'에 대한 attention score이다. 당연하게 자기 자신과의 유사도가 가장 높게 나타난다.

그리고 softmax 함수를 거쳐서 가중치 계산한다. 그리고 이 값을 각 단어의 임베딩 벡터에 곱하고나서 모두 더한다. 이것이 self-attention에서 출력하는 최종 값이다.
📚 Query, Key, Value 벡터
트랜스포머는 임베딩 벡터 의 단어들 간의 관계를 self-attention으로 계산한다. 이 과정에서Query, Key, Value 형태의 서로 다른 3개의 벡터를 생성해서 사용한다.
· Query 벡터 : 물어보는 주체. 유사한 다른 단어를 찾을 때 사용되는 (질의) 벡터
· Key : 쿼리와의 관계를 계산할 단어들. key는 단어의 id 역할?
· Value 벡터 : 딕셔너리 형태로 저장된다. value는 해당 단어에 대한 구체적 정보를 저장하는 역할
"I am a teacher" 라는 문장에서 I 가 다른 단어와 어떤 연관이 있는지 알아보기 위한 self attention을 수행할 때 :
Query : I 에 대한 벡터
Key : am a teacher 각각의 단어
✅ 트랜스포머에서 Self-attention 작동 순서
① 입력된 단어들에 대해서 query, key, value 벡터를 각각 계산한다. 이 과정에서 가중치 행렬이라는 개념이 사용된다.
② query를 이용해서 각 key와 유사한 정도를 내적으로 계산해서 attention score를 계산한다.
③ attention score를 softmax 함수에 통과시켜서 가중치를 계산한다.
④ 구한 가중치를 value 벡터에 곱한다.
⑤ 가중치가 곱해진 value 벡터의 원소들을 더해서 최종 결과물을 출력한다.
① Query, Key , Value 벡터 구하기

세 가지 벡터를 계산하는 과정에서 가중치 행렬을 사용한다. 이 행렬의 원소 값들은 개별 파라미터이고 학습을 통해서 업데이트된다. 각 가중치 행렬은 WQ, WK, WV 로 표현한다.
ex )
임베딩 벡터 차원=5
Q, K, V vector size=3으로 고정되어 있는 경우
각 가중치 행렬의 크기는?

Q, K, V 벡터의 크기를 맞추기 위해서는 가중치 행렬이 5x3 형태가 되어야 한다.
예시)

문장 = 'Today is Monday'가 있고, 각 단아의 임베딩 벡터가 위와 같이 표현된다고 가정.

이 값을 트랜스포머의 self-attention 층에 입력하면, 각 단어마다 3개의 벡터가 별도로 계산된다.

Today에 대한 Attention 작업을 수행하는 경우, Query 가중치 행렬은 다음과 같다고 가정. (이 행렬의 크기 5x3은 앞에서 설명)
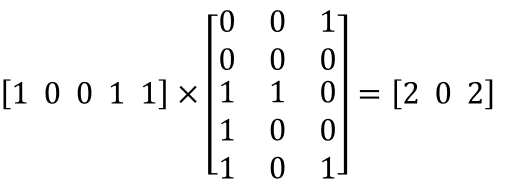
(해당 단어의 임베딩 벡터) X (query 가중치 행렬) = query 벡터 방식으로 행렬 내적 연산을 수행한다. [2,0,2] 는 Today라는 단어에 대한 query 벡터이다.


동일한 방식으로 Key 벡터를 구할 수 있다.
(해당 단어의 임베딩 벡터) X (key 가중치 행렬) = key 벡터
여기서 키 가중치 행렬의 값은 랜덤 하게 설정한 값이다.
② Attention Score 구하기
단어 1에 대한 query 벡터와, 단어 1, 2, 3에 대한 key 벡터 사이의 내적 연산을 수행해서 attention score를 계산한다.

Attention score는 단어들이 서로 얼마나 유사한지를 나타내는 값이다. 따라서 Today라는 단어는 Today, Monday와 관련도가 높다고 할 수 있다.
③ Softmax 함수를 통해서 가중치 계산

소프트 맥스 함수에 attention score를 통과시키면 각 단어의 가중치를 출력한다.
④ 가중치를 value 벡터에 곱하기

value 가중치 행렬이 위와 같다고 할 때,

(해당 단어의 임베딩 벡터) X (value 가중치 행렬) = value 벡터
각 단어의 임베딩 벡터와 곱해서 value 벡터를 구한다.

그리고 앞서 구한 단어의 가중치를 곱한다.

그리고 벡터의 값을 원소별로 더해서 최종 결과를 출력한다. 이 과정을 단어 2, 3에 대해서도 수행한다.

3개의 벡터를 이용해서 self-attention 에서 출력하는 값을 정리하면 위와 같다. output 들은 해당 단어가 다른 단어와 얼마나 관련이 있는지에 대한 정보를 포함하고 있다.
✅ 수식으로 표현하기

| Q : Query 벡터들에 대한 행렬 K : Key 벡터들에 대한 행렬 V : Value 벡터들에 대한 행렬 KT : K 행렬의 전치행렬 (Transpose) Q와 KT의 곱하기 : Query 벡터들과 Key 벡터들의 내적연산을 의미 |
위의 과정을 행렬 연산 수식으로 표현할 수 있다. QK^T 부분이 attention score를 의미한다.
📚 Transfomer
2017년 구글에서 제안한 attention 기반의 encoder-decoder 알고리즘이다. encoder는 입력된 raw 정보를 숫자 정보를 변환하는 역할을 한다. decoder는 인코딩한 숫자를 다른 데이터 형태(텍스트, 이미지, 비디오)로 변환한다. Attention의 작동 원리가 핵심이다.
✔ 주요 application
• BERT(Bidirectional Encoder Representations from Transformers)
트랜스포머의 인코더 부분만 사용. 가장 많이 사용된다.
• GPT(Generative Pre-trained Transfomer)
주로 새로운 데이터를 생성할 때 사용. 트랜스포머의 디코더 부분만 사용
• BART(Bidirectional and Auto-Regressive Transfomers)
주로 텍스트 요약에 사용된다. 트랜스포머의 인코더/디코더 둘 다 사용함. 1

Transfoemr 모델은 2017년 게재된 "Attention is all you need" 논문에서 처음 제시되었다. 트랜스포머 모델은 인코더 블록과 디코더 블록으로 구성되며 각 블록을 여러개 쌓을 수 있다. 위 논문에서는 6개씩 블록을 쌓았다. 주황색으로 표시된 부분들이 self-attention 층이다.
Vaswani et al. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).

transfomer에는 attention 구조가 여러 개 사용되는 multi-head attention 구조를 구축했다.
텐서플로우에서 multi-head attention :
이 논문에서는 내적 연산을 수행할 때 scaled dot product attention을 실시했다. 우측 그림에서 scale 부분이 표준화를 실시하는 과정이다.


이 부분이 스케일링을 하는 것인데, 루트 dk는 key vector의 크기와 동일하다. QK^T는 attention scroe를 의미함.

multi head attention 구조에서 여러 attention의 결과는 위와 같이 표시할 수 있다.
원래는 Attention(Q, K, V) 형태로 표현할 수 있지만, 여기서는 Q, K, V에 가중치를 한번 더 곱하는 linear projection을 실시했다.

그리고, 여러 개의 헤드 결과를 concat으로 통합하고 가중치를 곱해서 최종 attention을 계산한다. 한 헤드마다 64개의 결과가 출력되고 총8개의 헤드가 있기 때문에 8x64개의 벡터가 출력된다.

add&norm 레이어는 self-attention에 입력되는 값과 출력되는 값을 이어붙여서 전달한다. 이는 ResNet에서 사용한 skip connection 구조과 유사한 구조이다. 이 구조를 통해서 경사 소실 문제를 완화할 수 있다.

트랜스포머에서는 레이어 표준화 방법을 사용한다. 각 레이어에 입력되는 값들을 위와 같이 표준화하는 것.
Layer normalization: Add 연산 결과에 layer norm 적용, 이는 각 관측치에 대해 하나의 레이어에 존재하는 노드들의 입력값들의 정보를 이용해서 표준화하는 것을 의미

파란색은 position wise feed forward network 이고, 2개의 dense layer로 구성되어있다.
첫 번째 레이어에는 Relu 활성화함수가 사용된다.


또한 트랜스포머에서는 단어 임베딩 벡터를 입력할 때, 위치정보 임베딩을 실시한다. 이렇게 만들어진 최종 벡터는 각 단어마다 512차원으로 구성된다.
RNN 같은 순환신경망 기반 모델은 순서를 파악하기가 쉽지만, attention 기반의 트랜스포머는 단어 간의 관계는 파악하기 더 유리하지만 단어 간의 순서 정보는 파악하기가 어렵다. 따라서 위치 정보 임베딩을 통해서 순서 정보를 추가하는 것.
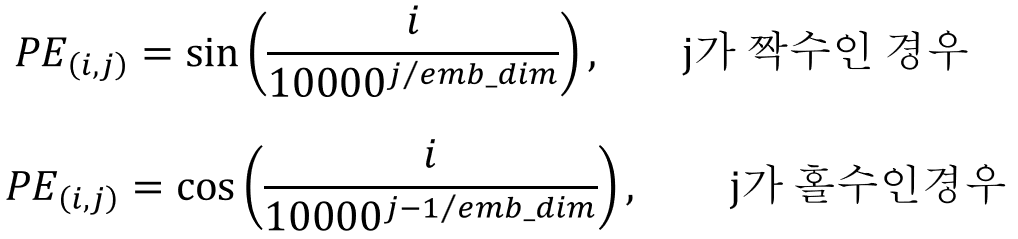
위치정보를 계산하는 식은 j 가 짝수/홀수인 경우에 따라서 달라진다. PE(i,j)는 단어 i의 positional embedding vector의 위치 j의 원소값을 의미한다.
예를 들어, ['Today', 'is', 'monday'] 라는 위치정보 임베딩 벡터를 512차원의 벡터로 나타내는 경우 아래와 같이 계산된다.
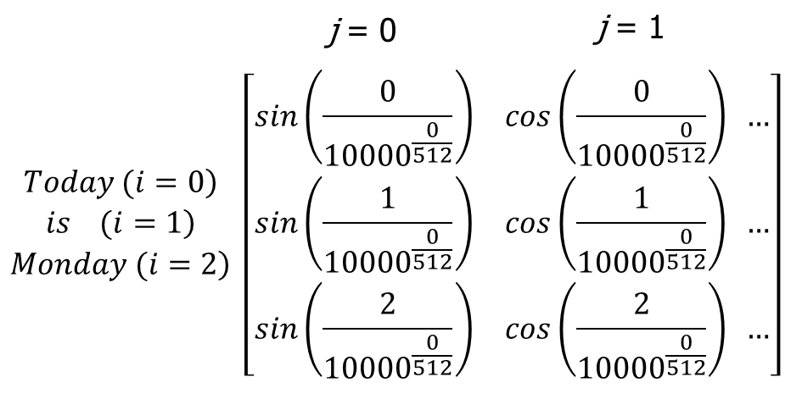
이 수치들은 학습되는 것이 아니라 주어진 공식에 따라서 미리 계산되는 값이다.
디코더 부분에서는 self attention이 아니라 인코더에서 넘어온 값을 이용한 encoder-decoder attention이 사용된다.
📚 추가 설명
이 부분은 고려대학교 산업경영공학부 DSBA 연구실의 세미나 영상을 참고하여 정리하였습니다.
상세 내용은 유튜브 영상을 참고하시길 바랍니다. https://www.youtube.com/watch?v=Yk1tV_cXMMU
✅ 트랜스포머의 구조

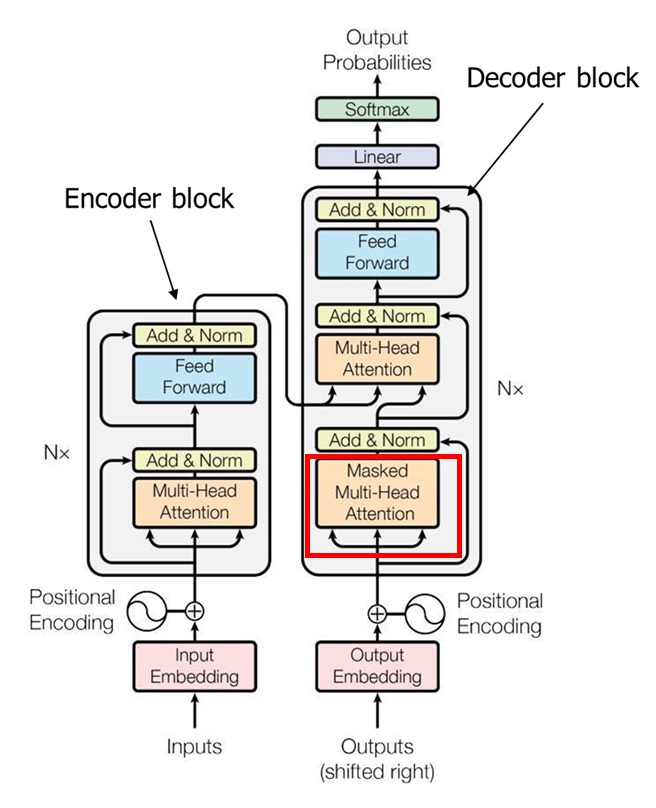
총 6개의 인코더 블록과 디코더 블록이 반복해서 사용되는데, 6개에 대한 논리적인 근거는 제시되어 있지 않다.

인코딩 블록은 2단계 구조로 되어있으며 모든 시퀀스를 그대로 입력하고 마스킹을 사용하지 않는다.
반면 디코딩 블록은 마스킹을 실시하는데 여기서는 orders에 대한 단어가 마스킹 처리되어 있다. 디코딩 블록은 3 단계로 구성되어 있다. 각 블록들은 모두 구조가 위와 같이 동일하지만 구조 내부의 가중치는 학습을 통해서 다르게 결정된다.

디코더 블록은 3단계이고 우선 자기 자신에 대해서 self-attention을 한 번 수행하고, 인코더에서 들어온 정보들과의 attention을 수행하고 마지막으로 FFN으로 전달된다.


노란색 부분이 인코더 블록, 초록색 부분이 디코더 블록에 해당한다. 실제로는 우측처럼 각 블록이 위로 6개 쌓이는 형태로 구성되어 있다.
✅ Positional Encoding

위 그림의 붉은색 부분에 해당한다.
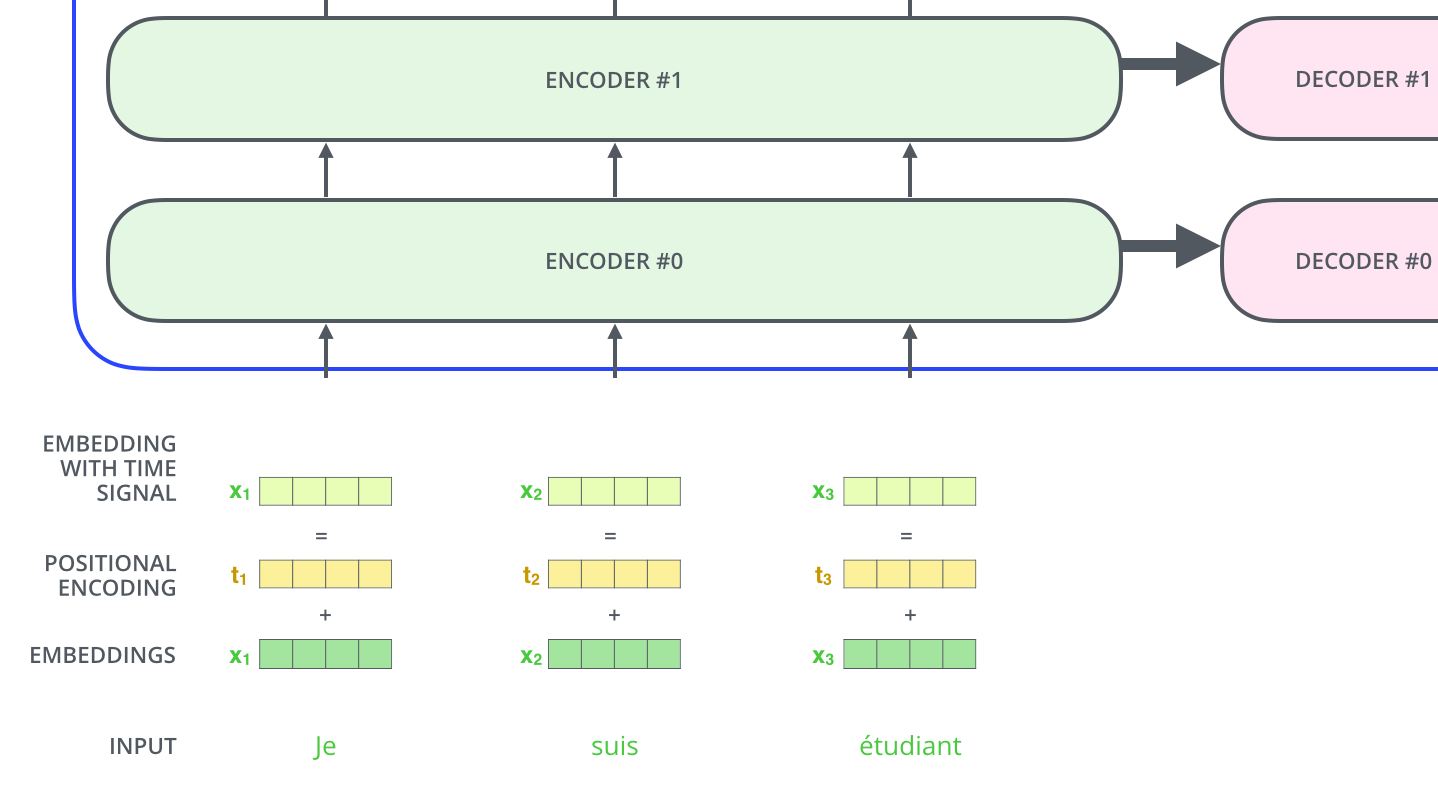
트랜스포머는 한 번에 모든 시퀀스를 입력받기 때문에, 단어의 위치 정보를 고려하지 못한다는 단점이 있다. 따라서 단어의 위치 정보를 반영하기 위해서 positional encoding을 사용한다.
트랜스포머는 512차원의 임베딩 벡터를 사용는데, Positional Encoding 벡터도 동일하게 512차원을 거친다. 첫 번쨰 인코딩 블록에는 임베딩 벡터와 포지셔널 벡터를 더해서(concat이 아니다) 동일하게 512차원으로 계산된 벡터가 입력된다.

만약 임베딩 벡터가 4차원인 경우에는 위와 같이 더해진다.


positional encoding vector를 계산하는 식은 위와 같다. 이 식을 바탕으로 X1~X10 으로 만들어진 포지셔널 벡터 사이의 거리를 살펴보면, 바깥 쪽으로 갈수록 값이 커지고 거리가 멀게 나타난다는 것을 알 수 있다. (여기서는 10차원 벡터 10개의 예시)

100개의 벡터로 확장해보면, 대각선은 거의 0에 가깝고 멀수록 멀어진다는 것을 알 수 있다. 하지만 일부 부분에서 거리 정보가 역전되는 상황이 발생하기도 한다. 하지만 전반적인 추세는 유지되므로 완벽하지는 않더라도 일정하게 거리 정보를 반영할 수 있다.
✅ 인코더 블록으로 입력

input vector를 받아서 attention을 수행하는 부분


시퀀스로 입력되는 각 단어에 대한 Input vector는 self-attention을 통해서 그대로 path를 통과하면서 포지션이 유지된다. 그리고 이것이 그대로 FFN으로 입력된다. self-attention 내에서는 각 벡터가 서로 dependency가 있어서 영향을 미치지만, FFN으로 입력된 이후로는 서로 간섭 없이 직선으로만 전달된다.

첫 번째 인코더 블록에서 FFN을 거쳐서 나온 r1, r2 벡터는 그대로 두 번째 인코더 블록으로 입력된다.
✅ Self-Attention

self-attention 에서는 주어진 input sequence의 단어들 간의 관계를 파악한다.

예를 들어, 5번째 self-attention 레이어에서 "it" 과 다른 단어들의 self attention scroe를 살펴보면 붉은색으로 표시된 부분의 값이 높게 나타나고, 이 단어들과 관계가 밀접하다는 것을 알 수 있다.
📌 STEP 1

트랜스포머에서는 Query, Key, Value 벡터를 사용하는데, 이는 input 임베딩으로부터 만들어진다.

1x4 형태의 인풋이 두개 있고, Q/K/V에 대한 가중치 매트릭스가 4x3 형태일 때, 이 두가지를 곱해서 각각 q1 / q2 / k1 / k2 / v1 / v2 를 생성한다. 일반적으로 Q,K,V 벡터는 64차원으로, 인풋 벡터 보다는 작게 생성해서 나중에 multi_head attention 에서 concat 하기 편한 형태로 사용한다.
📌 STEP 2

여러 개의 폴더 중에서 현재 내가 관심을 가지고 계산하고 있는 input의 토큰 "it" 이라는 단어와 유사한 폴더를 찾는다. 구체적으로 이를 찾는 계산과정은 다음과 같다.

현재 보고 있는 토큰의 쿼리 벡터 q1과 , 자신을 포함한 다른 토큰의 Key 벡터를 곱해서 값을 구한다. 여기서는 각각 112, 96이 계산되었다. 그리고 이 값을 루트(차원) 값으로 나눈다. 위에서 각 벡터의 차원이 64라고 설명했으므로 여기서는 8로 나누게 된다. 그리고 이 값을 softmax 함수를 통과시킨다. 소프트맥스 스코어는 '현재 내가 보고있는 인풋 토큰에서 해당 단어가 얼마나 중요한 역할을 하는가' 를 의미한다.
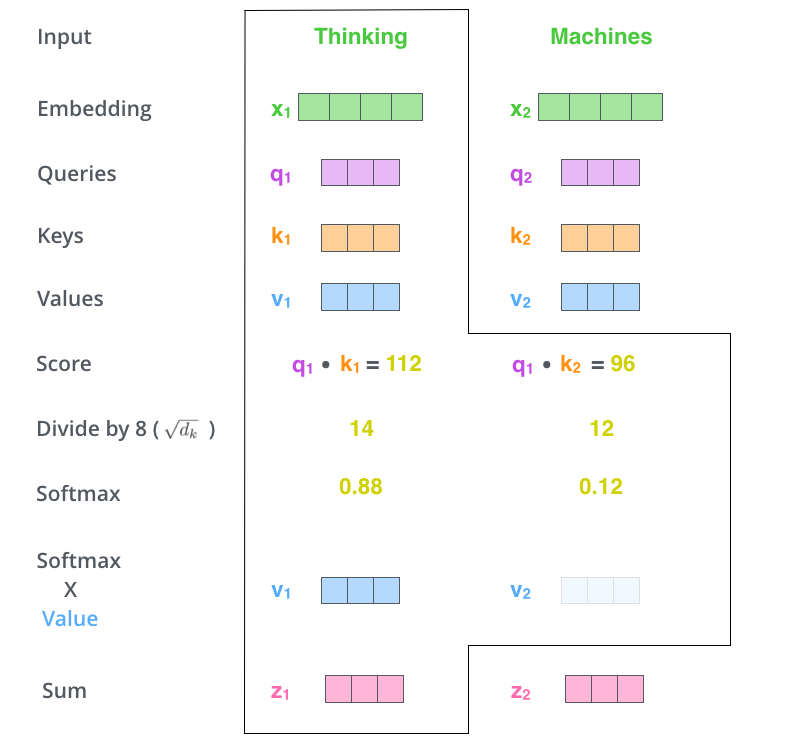
계산한 softmax 스코어에 Value 벡터의 값을 곱한다. 그리고 셀프 어텐션의 최종 출력 값인 z1을 계산하는데, 이는 소프트 맥스 스코어에 의해서 가중합된 값으로, v1과 v2를 더해서 계산한다. 보다 직관적으로 나타내면 아래 그림과 같다.
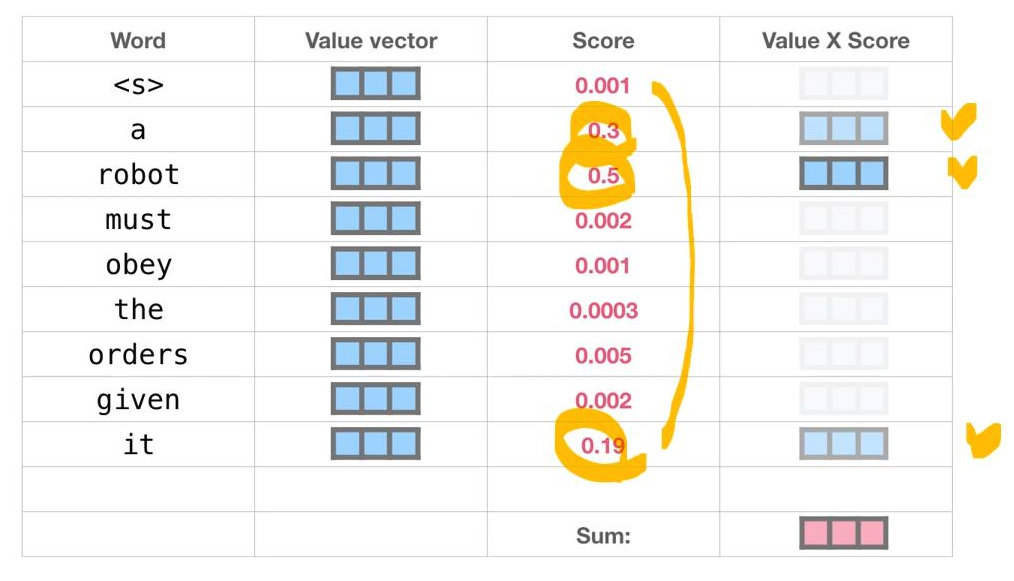
각 input token의 value 벡터는 softmax 스코어와 곱해지고, 그 결과 가중치가 높은 input token의 정보가 더 많이 남아있게 된다. self-attenion의 최종 output은 value x score의 값을 모두 더한 붉은색 벡터 이다.
🏷️ 연산과정 정리
이 전체 과정을 그림으로 정리하면 다음과 같다.


임베딩 벡터 X가 입력되면 Q/K/V 각각의 가중치 행렬(학습을 통해서 업데이트 되는 행렬)과 곱해져서 벡터를 생성한다. 그리고 각 벡터는 아래와 같은 연산 과정을 거쳐서, 최종적으로 셀프어텐션의 아웃풋인 z를 출력한다.
🏷️전체 구조 정리
https://jalammar.github.io/illustrated-gpt2/ 포스트를 참조하여 전체 구조를 다시 정리하면 다음과 같다.

네 개의 인풋 벡터가 있고 각각의 path가 표시되어 있다. 여기서 x1~x4는 서로 다른 단어를 나타낸다.

Q/K/V 가중치 행렬을 x1~x4랑 곱해서 별도의 Q/K/V 벡터를 계산한다.

첫 번째 Query 벡터 q1을 기준으로, 각 Key 벡터와의 연산을 시행하고 소프트맥스 함수를 통과시켜서 가중치를 계산한다.

그리고 이 가중치를 v1~v4로 표시된 Value 벡터에 곱한 뒤에 모두 더해서 z1을 계산한다.
위 과정을 x2, x3, x4 에 대해서 반복해서 z1~z4를 계산한다.
✅ Multi-head Attention

앞선 설명은 하나의 attention에 대한 것이다. 앞선 사례에서는 "it" 이라는 단어가 하나의 단어만 보는 경우를 계산한 것이지만, 실제 모델 성능을 위해서는 여러 단어를 볼 수 있게끔 해야 한다. 이를 위해서 single attention을 여러개 사용하고 여기서 output으로 나오는 여러개의 z1~z7 값을 사용하는 것이 multi-head attention 이다.

각 attention 에서 계산된 z1~z7 값을 concat하고, 이를 다시 새로운 가중치 행렬 W0와 곱한다. 여기서 가로 세로 크기를 행렬 연산을 위해서 동일하게 맞춰야 한다. 그리고 최종적으로 모든 어텐션의 결과를 합친 Z를 계산하여 출력한다. 이 Z는 single attention과 동일한 차원을 가진다.

multi head attention의 전체 구조는 위와 같다.


왼쪽은 attention을 2개 사용한 경우, 오른쪽은 8개 사용한 경우이다. single attention 과는 다르게
"it" 이 가리키는 단어에 대한 정보가 각기 다르게 출력되었다.
✅ Add & Normalization

Multi head attention을 통과한 값에 Residual Block을 더하는 과정과 정규화를 하는 과정이 진행된다. 여기서 Add 과정은 Residual connection과 동일한 의미이다.

🏷️Residual Bloack을 더하는 이유?
멀티 헤드 어텐션에서 출력된 값을 f(x) 로 표시할 때, residual connection을 실시하면 f(x) + x 로 표현이 가능하다. 경사하강법으로 업데이트를 할 때 x에 대해서 미분을 실시하면 f'(x) + 1 로 표현되는데, 여기서 f'(x) 값이 매우 작아지더라도 적어도 1 만큼의 값을 넘겨줄 수 있기 때문에 경사 소실 문제를 어느 정도 완화할 수 있어서학습에 유리하다.
정규화에는 Layer Normalization이 사용되고 이 과정을 거쳐서 FNN으로 전달된다. 이러한 Add&Normalize는 모델의 여러 부분에 반복적으로 사용되어 성능을 향상시킨다. 위 그림에서도 self attention에서 출력된 Z 값과 원래 X 값이 그대로 concat 된 이후에 정규화가 실시되는 것을 확인할 수 있다.
✅ Position-Wise Feed-Forward Network

FFN은 전달된 z1, z2에 대해서 별도로 계산을 수행한다.

FFN내부에서는 ReLu 활성화 함수가 사용된다. 0과 전달된 x 값중에 큰 것을 선택하고, 여기에 가중치를 곱하고 편향을 더한다.
여기서 같은 인코더 블록 내의 FFN은 동일하고, 서로 다른 인코더 블록 끼리는 구조가 다를 수 있다.

입력된 z1, z2 벡터는 512차원이지만 ReLu 함수를 거쳐서 2048 차원의 hidden vector로 표현된다. 그리고 이 차원을 다시 512차원으로 축소시켜서 출력한다. 위의 그림에서 좌, 우 네트워크는 같은 인코딩 블록 내부에 있기 때문에 파라미터와 구조가 동일하다. 여기서 차원이 확장,축소되는 과정은 커널사이즈=1 인 컨볼루션 연산으로 이해하면 된다.

z1, z2에 대해서 채널=2048, kernal size=1 인 경우로 보고 합성곱 연산을 수행할 수 있다. 위에서 수행한 2번의 연산을 총 2048번 수행하게 되면, 아래와 같이 총 2048개의 노란색 벡터를 만들 수 있다.

마찬가지로, 1x2048 크기로 컨볼루션 연산을 수행하는 과정을 총 512회 반복하게 되면 512차원의 분홍색 벡터를 계산할 수 있다. 최종적으로 512차원의 벡터가 출력된다.
✅ Decoder : Masked Multi-Head Attention

디코더에서는 반드시 자기 앞 쪽에 해당하는 토큰들에 대해서만 attention을 볼 수 있다. 이를 수식으로 반영하기 위해서 디코더에서는 해당 토큰 뒤에 나오는 값에는 모두 -무한대를 할당해서, softmax를 거치면 0이 되도록 설정한다.
따라서 우측에서는 Thinking 이라는 단어에 대해서 계산을 할 때, 오른쪽에 있는 Machine에 대해서는 예측을 하지 않고 앞 쪽의 단어만을 사용한다.

즉, x1~x4 로 4개의 단어 벡터가 입력되었을 때, x2 기준에서 보면 나중에 들어온 x3, x4의 key, value는 사용하지 않는다.

"robot must obey orders" 라는 시퀀스가 입력될 때 회색 부분은 마스킹 처리가 되야한다.

쿼리와 키 벡터가 곱해져서 다음과 같은 행렬을 계산하는데,

여기서 삼각형 부분을 마스킹 처리 하기위해서 -inf 값을 할당한다.

이를 softmax 함수에 통과시키면 0으로 출력된다.
🏷️ 전체 구조

인코더를 지나온 블록은 해당 쿼리와 키 값을 가지고 디코더에 영향을 미치고, 최종적으로 디코더에서 결과가 출력된다.

The following steps repeat the process until a special symbol is reached indicating the transformer decoder has completed its output. The output of each step is fed to the bottom decoder in the next time step, and the decoders bubble up their decoding results just like the encoders did. And just like we did with the encoder inputs, we embed and add positional encoding to those decoder inputs to indicate the position of each word.
✅ Encoder - Decoder Self-Attention
트랜스포머에서는 총 3개의 self attention이 존재한다.
(1) 인코더 내부의 self attention
(2) 디코더 내부의 self attention
(3) 인코더와 디코더 사이의 self attention
✅ Final Layer


디코더 블록에서는 최종적으로 숫자로 된 벡터가 전달된다. 따라서 이를 최종적으로 특정 단어로 반환할 필요가 있다.
마지막 레이어는 simple fully connected neural network 이고, 디코더의 벡터를 받아서 logits vector로 반환한다. 여기서 logits vector의 차원은 사전에 모델이 알고 있는 단어의 수와 동일하다. 즉 모델이 10,000개의 단어를 알고 있다면, 로짓 벡터는 10,000차원이 된다.
로짓 벡터는 다시 softmax 함수를 거치고 이를 통해서 각 단어일 확률이 계산된다. 여기서 가장 확률이 높은 단어가 최종적으로 선택되서 출력된다.
📚 Reference
• 연세대학교 디지털사회과학센터(CDSS) 파이썬을 활용한 딥러닝 기초 워크숍, 이상엽 교수님
• Vaswani et al. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
• 고려대학교 산업경영공학부 DSBA 연구실, 08_2. Transforemr 강의자료, https://www.youtube.com/watch?v=Yk1tV_cXMMU
• https://jalammar.github.io/illustrated-transformer/
• 유튜브 동빈나-[딥러닝 기계 번역[Transformer: Attention is All you Need]
https://www.youtube.com/watch?v=AA621UofTUA&t=2716s
'머신러닝, 딥러닝 > 딥러닝' 카테고리의 다른 글
| BERT 기본 개념 (0) | 2022.02.13 |
|---|---|
| 오토인코더(Autoencoder), 합성곱 오토인코더(Convolutional Autoencoder) (1) | 2022.01.21 |
| LSTM, Bidirectional LSTM (0) | 2022.01.19 |
| Stacked RNN (0) | 2022.01.19 |
| CNN을 이용한 텍스트 분류 (0) | 2022.01.18 |




댓글