📚 오토인코더 (Autoencoder)

오토인코더는 비지도학습 모델로, 입력 데이터의 패턴을 학습해서 최대한 유사한 데이터를 새롭게 생성한다. 데이터가 입력되면 encoder를 통해서 저차원의 벡터로 변환되고, 이를 decoder가 받아서 결과물을 출력한다.
encoder 부분은 입력 받은 정보에서 불필요한 정보를 제외하고 차원을 축소하는 역할을 한다. decoder 부분은 주로 데이터의 차원을 축소해서 feature extraction 목적으로 많이 사용된다.
generative model에도 사용되는데 최근에는 보다 성능이 좋은 GAN이 많이 사용된다.

오토인코더에서는 입력된 값을 그대로 예측해서 출력하는 것을 목적으로 한다. 즉, 정답 = 입력값 이므로 정답에 대한 레이블링이 필요없다. 이러한 지도학습 방식을 self-supervised learning 이라고 한다.
오토 인코더는 다음과 같은 목적으로 사용될 수 있다.
• 차원 축소
• Denoising
• Anomaly & Outlier Detection
• 추천시스템
📚 합성곱 오토인코더

기본적인 오토인코더와 구조는 동일하지만, CNN처럼 합성곱 필터를 이용해서 인코딩과 디코딩을 진행한다. 인코더 부분에서는 convolution 연산을 수행하고, 디코더 부분에서는 transposed convolution 연산을 수행한다.
✅ Encoder 부분
합성곱 오토인코더의 인코더 부분에서는 convolutional layer가 사용된다. 일반적인 합성곱 연산은 아래와 같이 진행된다. 일반적인 convolution layer에서 input,kernel,padding,stride를 i, k, p, s라고 할 때, output 한변의 길이 o는 아래와 같이 정해진다.

📌 Convolution 연산 예시




📌 파이토치 코드

✅ Decoder 부분
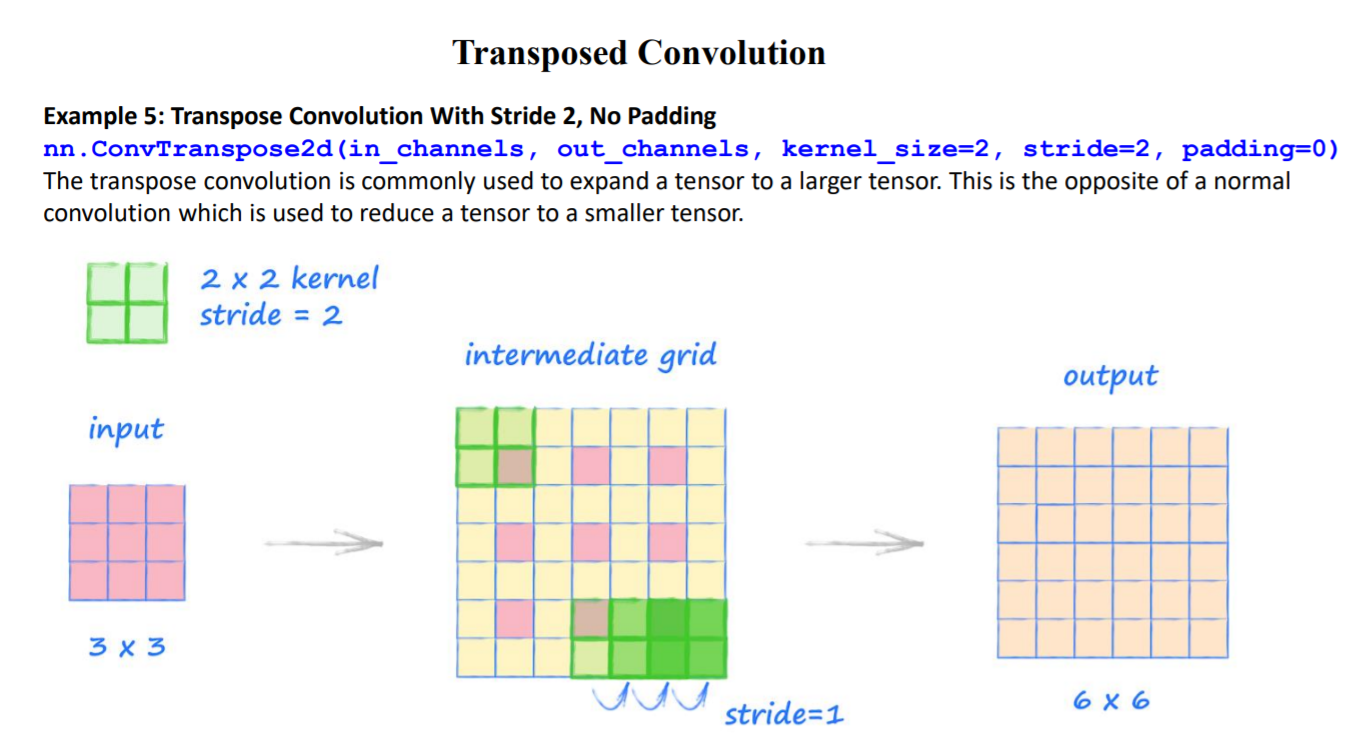
Transposed convolution 연산과 deconvolutionl 연산은 다르다. deconvolutionl은 convolution 역 연산이므로 input 데이터를 다시 출력한다. Transposed convolution은 input을 원래대로 되돌리는 역할을 하고, output의 차원의 크기도 동일하다는 점에서 deconvolution과 유사하지만 연산 수행 방식이 다르다.
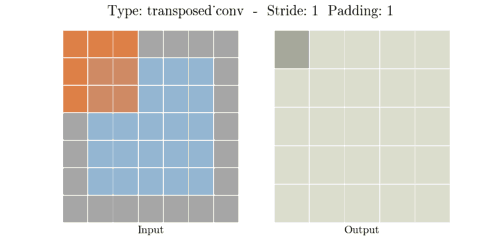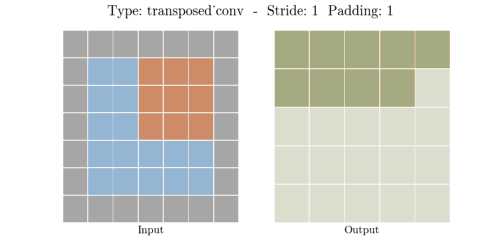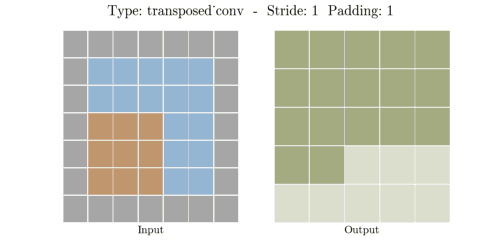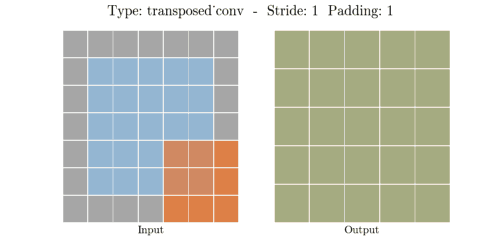
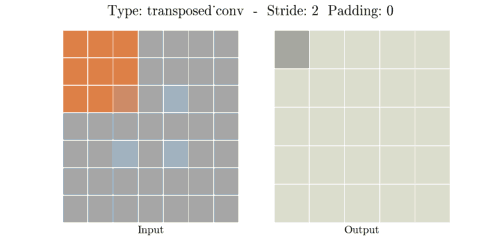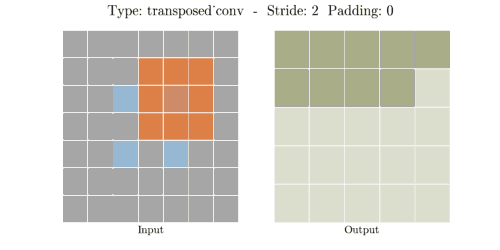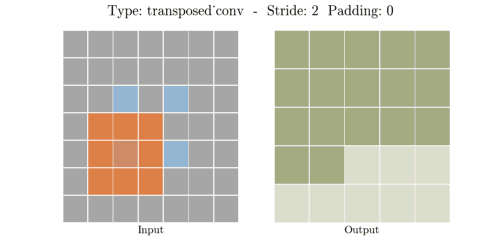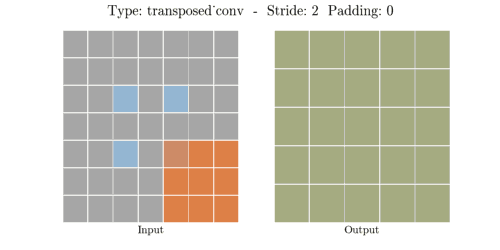
📌 Transposed Convolution 과정

① (stride - 1) 만큼 input 이미지의 열,행 사이에 zero padding을 실시해서 차원을 증가시킨다.
② (kernel size - padding - 1)만큼 테두리에 zero padding을 실시해서 차원을 증가시킨다.
③ 차원을 증가시킨 input 이미지에 일반 convolution 연산을 수행해서 output을 출력한다.
input, kernel, padding, stride 의 i, k, p, s가 주어졌을때 output 한변의 길이 o는 아래 공식으로 계산된다.

📌 Transposed Convolution 예시




📌 파이토치 코드

📚 예제 코드
✅ 오토인코더로 MNIST 손글씨 데이터 생성하기
✔ 🏷️📘
Autoencoder_example_MNIST (참고)
📌 라이브러리, 데이터 불러오기
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.datasets import mnist
from tensorflow.keras.regularizers import l1
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
#데이터 불러오기
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train1 = x_train.astype('float32') / 255.0
x_test1 = x_test.astype('float32') / 255.0
print('원본 train data :',x_train.shape)
print('원본 test data :',x_test.shape)
#데이터 reshape
x_train = x_train1.reshape((60000, 28*28))
x_test = x_test1.reshape((10000, 28*28))
print('reshape train data :',x_train.shape)
print('reshape test data :',x_test.shape)
MNIST 데이터를 불러오고 reshape를 실시한다. 원래 이미지는 28x28 형태이지만 일렬로 펼쳐서 784개 원소를 가진 벡터로 만든다.
📌 오토인코더 정의
input_size = 784
hidden_size = 128
code_size = 32 # latent vector의 차원
# Encoder 부분 생성
input_img = Input(shape=(input_size, ))
hidden_1 = Dense(hidden_size, activation='relu')(input_img)
code = Dense(code_size, activation='relu')(hidden_1)
# Decoder 부분 생성
hidden_2 = Dense(hidden_size, activation='relu')(code)
output_img = Dense(input_size, activation='sigmoid')(hidden_2)
#오토인코더 정의
autoencoder = Model(input_img, output_img)
📌 모델 학습
autoencoder.compile(optimizer='adam', loss='mse')
autoencoder.fit(x_train, x_train, epochs=30)
📌 예측 실시
decoded_imgs = autoencoder.predict(x_test)
decoded_imgs = decoded_imgs.reshape((10000,28,28))
decoded_imgs.shape

모델을 통해서 생성한 데이터를 출력하면 위와 같다. 이미지로 다시 나타내기 위해서는 28x28 형태로 나타내야 한다.
📌 생성된 이미지 비교
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
# 원래 이미지
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test1[i])
plt.title("original")
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 생성한 이미지
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i])
plt.title("reconstructed")
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()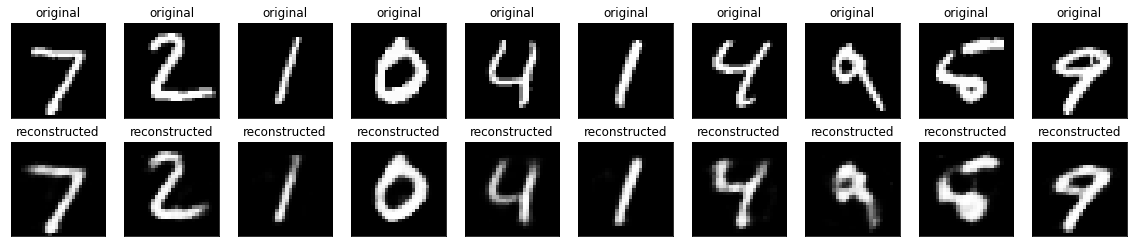

결과를 확인해보면 에폭=30 회로 설정해서 보다 많이 학습한 모델의 이미지의 경계가 미세하게 선명한 것을 알 수 있다.
📚 Reference
https://analyticsindiamag.com/how-to-implement-convolutional-autoencoder-in-pytorch-with-cuda/
transposed convolutional layer 설명
'머신러닝, 딥러닝 > 딥러닝' 카테고리의 다른 글
| BERT로 영화 리뷰의 감성 분석하기 (0) | 2022.02.14 |
|---|---|
| BERT 기본 개념 (0) | 2022.02.13 |
| Transfomer 기본 개념 정리 (2) | 2022.01.20 |
| LSTM, Bidirectional LSTM (0) | 2022.01.19 |
| Stacked RNN (0) | 2022.01.19 |




댓글