📚 BERT : Bidirectional Encoder Representation from Transfomer
✅ BERT 개요
📌 BERT 란?
이미지 분석에서 사전학습 모형을 사용하는 것처럼 텍스트 데이터를 미리 학습한 사전학습 모델이다.
BooksCorpus (800M words)와 Wikipedia(2,500M words)를 이용해서 학습하였다. 트랜스포머에서 encoder 부분만 사용한 모델이며, MLM / NSP 방식으로 학습을 진행한다.
📌 출처 논문
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.

📌 BERT의 2가지 형태
L = encoder block의 수 / H = 임베딩 벡터 또는 hidden state 벡터의 차원의 수 / A = 사용된 self attention의 수
① BERT base
(L=12 / H=768 / A=12 / Total Parameters=110M,1억1천만)
② BERT large
(L=24 / H=1024/ A=16 / Total Parameters=340M,3억4천만)
BERT base의 경우 12개의 인코더 블록이 있으며, 각각 최종적으로 768 차원의 hidden state 벡터를 출력한다. 그리고 12개의 인코더 블록의 정보를 모두 사용하는 것이 아니라, 마지막 4개의 인코더 블록에서 출력하는 정보를 사용한다.
📌 Context-based embedding 과 비교
Word2vec, FastText 등의 기법도 문맥 정보를 사용하지만, 동음이의어를 구분하지 못하는 한계점이 존재한다.
예시) '내가 너의 사과를 훔쳐먹어서 미안해. 사과할게'
이 문장에서 두 사과는 다른 의미이지만 word2vec은 동일한 임베딩 벡터를 출력한다.
반면 BERT는 주변 단어의 정보를 사용하는 self-attention을(+positional embedding) 통해서 hidden state 정보를 계산하기 때문에 단어의 의미에 따라서 다른 임베딩 벡터를 출력할 수 있다.
📌 BERT에서 문장과 시퀀스
BERT에는 문장이 입력될 때, 단일 문장이나 두 개의 문장이 쌍으로 입력된다.
• Sentence : 일반적인 문장은 주어와 술어로 이루어져 있지만, 버트에서는 문장의 구성성분과 상관없이 연속적인 단어들의 span을 한 문장으로 본다.
• Sequence : 앞서 정의한 single sentence일수도 있고, pair sentences일수도 있다.
✅ BERT 의 구조

BERT는 두개의 문장으로 구성된 시퀀스 데이터를 입력받는다. 여기서 입력되는 문장의 토근들 중 일부는 마스킹 처리가 된다.
✔ CLS 토큰은 입력되는 시퀀스 데이터의 시작을 알려주는 역할을 하며, 시퀀스 전체의 정보를 반영한다 .
✔ SEP 토큰은 두 개의 시퀀스가 입력되었을 때, 문장을 구분하기 위해서 사용된다.
✔ BERT 모델은 여러 개의 인코더 블록으로 구성되고 최종적으로 각 토큰에 대한 hidden state인 Ti 를 출력한다.
출력층의 C는 입력된 문서의 전체 특성을 담고있는 임베딩 벡터이다. 감성분석이나 텍스트 분류 같은 경우에는 C 토큰의 정보만을 사용하기도 한다. 최종 출력된 결과를 보면 NSP와 MLM을 동시에 실시한 것을 알 수 있다.
✅ 입력 데이터

BERT는 3가지 토큰 정보가 입력된다. 세 가지 임베딩 벡터의 차원이 동일하므로 이를 모두 더해서 모델에 입력한다.
(1) Token embedding :
각 단어 토큰에 대한 임베딩 벡터를 의미한다.
BERT는 WordPiece라는 개념을 사용해서 단어를 입력하는데, 단어장에서 총 30,000개의 단어 임베딩을 사용한다.
(2) Segment embedding :
시퀀스가 2개가 입력될 때, 각 시퀀스를 구분하는 정보
(3) Position embedding :
트랜스포머에서 사용된 positional embedding 과 동일함
✅ BERT 학습 방식 ( Pre-Training )
BERT는 아래 두 가지 목적을 가지고 학습을 수행하면서 토큰들의 임베딩 정보와 모델의 파라미터를 학습한다.
📌 Task 1 : Masked Language Mode (MLM)
MLM은 전체 시퀀스에서 15%를 랜덤하게 MASK 토큰으로 변경한다.

w1~w5가 입력될 때, w4가 MASK 토큰으로 변경되어 입력되었다. 여기서 w1~w5는 인코딩 블록을 거쳐서 O1~O5로 출력되고, 다시 뉴럴넷 레이어를 거쳐서 최종적으로 w`1~w`5로 출력된다. 여기서 w`4가 w4와 동일한 방향으로 나타나도록 학습하는 것이 MLM이다.
🏷️ 마스킹 방식의 문제점
하지만 마스킹은 pre train 과정에서만 실시하고, fine-tuning 단계에서는 등장하지 않아서 마스크 토큰에 대한 미스매치가 발생할 수 있다는 문제점이 있다.
따라서 이러한 문제를 해결하기 위해서 i 번째 토큰이 마스킹 토큰으로 선정되었을 때, 실제로 80%만 [MASK] 토큰으로, 10%는 Random 토큰으로, 10%는 변경하지 않고 그대로 남겨둔다.

hairy 라는 단어를 마스킹한다고 할 때, 위와 같이 진행된다. 여기서 apple은 랜덤 토큰으로 전혀 상관없는 의미의 토큰이 들어온다.

논문에서는 여러 번의 실험을 통해서 경험적으로 성능이 가장 우수한 8:1:1 비율을 선택하였다. 이 방식을 통해서 pre-train과 fine-tuning 시의 미스매치를 해소할 수 있다.
📌 추가설명
아래 그림은 'my dog is cute and it has a short tail' 라는 문장을 입력했을 때의 예시이다.


(마스킹 1.) 이미지의 초록색 T[MASK]에 해당하는 부분을 확대하면 (마스킹 2.) 이미지이다. 마스킹 2에서 출력되는 노드는 마스킹된 단어가 어떤 값을 가질 지에 대한 확률이 출력된다.
초록색 층에서 MASK 토큰에 대한 hidden state가 출력되면, 그 값을 FNN으로 전달하고 softmax(분류문제)를 거쳐서 비용함수를 계산한다.
이렇게 MLM을 이용해서 모델을 학습한 이유는, 실제 분석을 위한 fine-tuning시에는 [MASK] 토큰이 사용되지 않기 때문에, 이러한 mismatch를 어느정도 해결해서 성능을 향상시키기 위해서이다.
📌 Task 2 :Next sentence Prediction (NSP)
Question Answering이나 Natural Language Inference와 같은 작업은 두 개의 문장 간의 관계를 이해할 수 있어야 수행 가능하다. 하지만, GPR나 엘모와 같은 랭귀지 모델은 문장 단위로 학습하기 때문에 문장 간의 관계를 학습하기가 어렵다. 이러한 문제를 해결하기 위해서 BERT는 Binarized next sentence prediction 방식을 사용했다. 이 과정은 MLM과 함께 수행된다.


전체 코퍼스에서 두 개의 문장을 추출하는데 50%는 실제 앞뒤 문장을 사용하고, 나머지 50%는 랜덤으로 두 문장을 사용한다. 그리고 가장 마지막에 출력되는 C 토큰을 이용하여 이 문장들이 Nest sentence인지 아닌지 판별하는 classification 을 수행한다. 이 과정은 MLM과 함께 진행된다. 논문에 따르면 이 방식은 간단하지만 모델 성능을 향상에 기여한다.
🏷️ 예시
https://www.youtube.com/watch?v=IwtexRHoWG0

위와 같이 예시 스크립트가 있다고 할 때

위의 두 문장은 연속되는 문장이므로 C 토큰이 'IsNext'로 분류한다.

한편, 이 문장들은 연속하지 않기 때문에 'NotNext'로 예측한다.
✅ BERT의 하이퍼 파라미터
사전에 학습된 BERT 모델의 하이퍼 파라미터 설정은 아래와 같다.

- Maximum token length : 두 개의 시퀀스가 입력될 때, 두 개의 시퀀스를 합해서 총 512개의 토큰까지만 받을 수 있다.
- LR : 10000 스텝 이후에 감수
- 활성함수 : GeLU 사용
✅ Fine Tuning 과정
BERT 구조 위에 레이어를 추가하면 다양한 종류의 TASK를 수행할 수 있다.

(a) 두 개의 문장을 특정 방식으로 분류하는 태스크 [ output : 범주 예측 ]
(c) 질문/대답(paragraph)로 구성된 문장을 입력할 때, 대답을 출력해주는 태스크 [ output : 새로운 문장 생성]
(b) 하나의 문장을 입력받아서 특정 클래스로 분류 [ output : 범주 예측 ]
(d) 하나의 문장을 받아서 각 토큰마다 정답을 출력 [ output : 새로운 문장 생성]
✅ 기타 참고 자료
📌 허깅 페이스
• Hugging Face에서 제공하는 트랜스포머 사용하기. 다양한 버트 모델을 제공함 (링크에서 확인)
허깅 페이스는 트랜스포머 기반 모델을 다양하게 구현해 둔 모듈이다. 파이토치보다 high level로 구현되어 있어서 보다 편하게 모델을 사용할 수 있다.
https://huggingface.co/transformers/
• downstream task에 따라서 사용할 수 있는 클래스가 별도로 존재함
https://huggingface.co/docs/transformers/model_doc/bert
• 기본적인 사용법 튜토리얼
https://mccormickml.com/2019/05/14/BERT-word-embeddings-tutorial/
📌 한글 감성분석 방법
방법1. BERT의 multilingual 버전 사용
BERT_Kor_movie_review_classification_fine_tuning
방법2. 한글 데이터를 학습한 모델을 사용
KoBERT : https://github.com/SKTBrain/KoBERT
KcBERT : https://github.com/SKTBrain/KoBERT
KoELECTRA : https://github.com/SKTBrain/KoBERT
✅ 유사도
최종적으로 BERT가 출력하는 결과를 통해서 유사하거나 관계가 높은 단어들을 계산할 수 있다.

공간상에서 벡터의 위치는 해당 벡터의 유니크한 특징을 나타낸다. 따라서 위치가 비슷하면 해당 벡터들의 특성이 유사하다고 할 수 있다. BERT base는 768차원의 벡터를 출력하기 때문에, 768 차원의 공간에서 벡터들의 거리를 계산하면 어떤 단어들이 유사한지 유클리디안 거리나 코사인 유사도를 이용해서 파악할 수 있다.


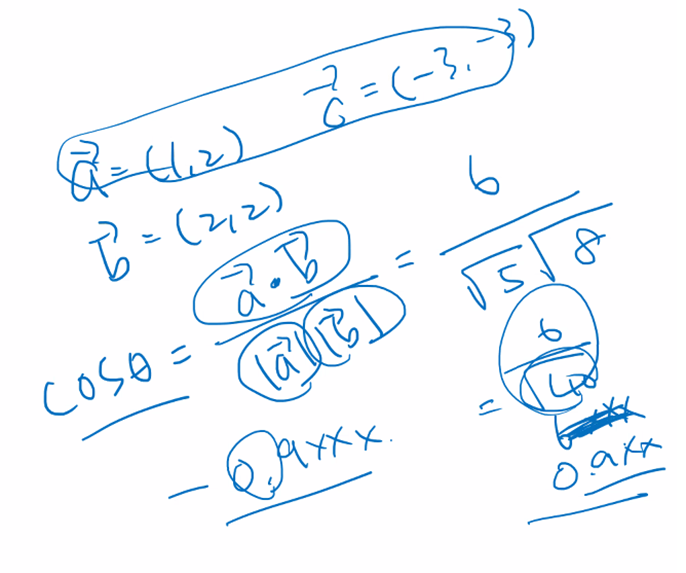
두 벡터의 방향성이 유사한 정도는 벡터 사이의 각도인 사이각을 통해서 표현할 수 있다. 사이각이 작을수록(0에 가까울수록) 유사하고, 클수록(180도에 가까울수록) 방향이 반대이다. 하지만 벡터 간의 각도를 직접 계산하기가 어렵기 때문에 이를 수치적으로 표현하기 위해서 코사인 함수가 사용된다. 코사인 세타의 값이 작을 수록 사이각이 작아지며, 이는 두 벡터의 유사도가 높다는 것을 의미한다.
◈ Reference
• 연세대학교 디지털사회과학센터(CDSS) 파이썬을 활용한 딥러닝 기초 워크숍, 이상엽 교수님
• Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
• https://www.youtube.com/watch?v=IwtexRHoWG0
'머신러닝, 딥러닝 > 딥러닝' 카테고리의 다른 글
| BERT로 한글 영화 리뷰 감성분석 하기 (0) | 2022.02.17 |
|---|---|
| BERT로 영화 리뷰의 감성 분석하기 (0) | 2022.02.14 |
| 오토인코더(Autoencoder), 합성곱 오토인코더(Convolutional Autoencoder) (1) | 2022.01.21 |
| Transfomer 기본 개념 정리 (2) | 2022.01.20 |
| LSTM, Bidirectional LSTM (0) | 2022.01.19 |




댓글