📚 LSTM 개념 설명
✅ RNN의 문제점
✔ Problem of long term dependency (장기의존문제)
입력된 문서에서 상대적으로 초반부에 등장하는 단어들의 정보가 제대로 반영되지 않는다. 즉, 마지막 time step에 대한 RNN층의 출력 hidden state만 다음 층으로 전달하게 되면 앞쪽 RNN층의 정보를 잘 학습하지 못한다.
✅ LSTM (Long Short Term Memory)

RNN이 가지는 장기의존문제를 개선하기 위해서 LSTM은 기억 셀(memory cell)을 추가한다. 기억 셀에는 입력/망각/출력 게이트가 추가되는데 이를 통해서 이전 단어의 정보를 더 잘 반영하고 멀리 떨어져 있는 단어들의 정보를 보다 잘 학습할 수 있다.
기억셀 Ct는 하나의 벡터 형태이고, 차원(벡터 원소의 수)은 LSTM 은닉 층의 노드의 수와 동일하다. 최종적으로 LSTM 층에서 다음 층으로 넘어가는 정보는 hidden state vector 값이다.
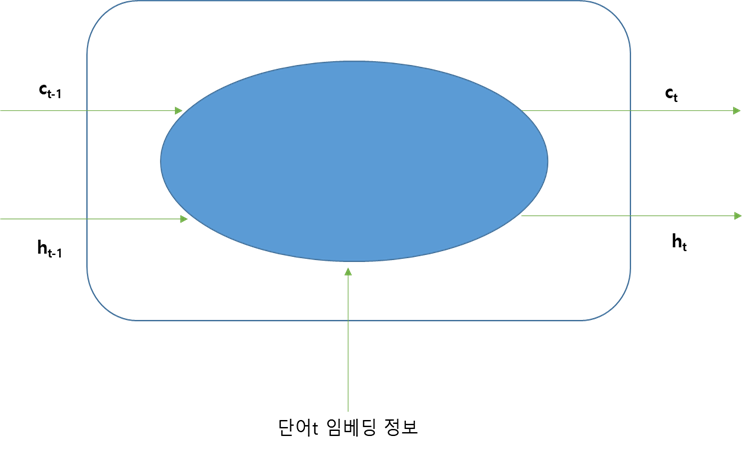
LSTM 층에는 3가지 정보가 전달된다.
① xt : 단어 t의 임베딩 정보
② ht-1 : 이전 단계의 hidden state
③ Ct-1 : 기억 셀
LSTM층(파란색)은 ht와 Ct를 계산해서 다음 층으로 전달한다. 기억 셀은 가장 위에서 왼쪽으로 오른쪽으로 가는 선이다.
이 두 가지 결과를 계산하는 과정에서 게이트(gate)가 사용된다.
✅ 게이트(gate) 설명
게이트는 Forget / Input / Output 3 가지 종류가 있다.
📌 1. Forget 게이트


이전 기억 셀 ct-1이 가지고 있는 정보 중에서 중요하지 않은 정보를 삭제하는 역할을 한다. 이 과정에서 ht-1과 xt의 정보를 사용한다.
ct-1의 각 원소의 정보 중에서 몇 %를 잊어버릴 것이냐를 결정하기 위해서 0~1사이의 값을 반환하는 sigmoid함수를 사용한다.
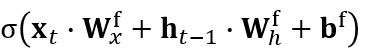

forget gate 업데이트 식의 시그모이드 함수 부분을 그림으로 나타내면 위와 같다.
xt : time step=t에서 LSTM층에 입력된 단어의 임베딩 벡터, 원소를 K개 가지고 있다고 가정 (1 x K 형태)
ht-1 : 이전 단계에서 LSTM 층이 전달하는 Hidden state vector, 기억셀의 원소 수와 동일한 h 개의 노드 가짐. (1 x h 형태)
Wxf : f는 forget gate를 의미함. xt와 기억셀 사이의 파라미터 (K x h 형태)
Whf : ht-1과 기억셀 사이의 파라미터(h x h 형태)

위의 시그모이드 함수 내부의 요소들의 행렬의 크기를 바탕으로 연산 결과를 확인해보면 최종적으로 1xh 형태로 출력된다는 것을 알 수 있다.

1xh 벡터에 시그모이드 함수를 적용하면 각 원소에 대해서 시그모이드 함수가 적용된다. 여기에 ct-1을 아마다르 곱하기하면 위에서 본 식으로 표현할 수 있다. (아마다르 곱셉은 같은 위치의 원소끼리의 곱셈을 의미한다)

이전 셀에서 중요한 정보를 담고 있는 경우에는 최대한 적게 삭제해야 한다. 따라서 시그모이드 함수에서 나온 0~1의 값 중에서 1에 가까운 값이 곱해질수록 정보가 적게 삭제된다. 반대로 0에 가까운 숫자가 곱해지면 정보가 많이 삭제된다. Ct-1'은 Ct-1이 가진 정보에서 일부 정보가 삭제된 상태로 업데이트된 값을 의미함. 즉, forget gate만을 통과한 상태를 나타낸다.
📌 2. Input 게이트


forget 게이트를 통과해서 중요하지 않은 정보가 삭제된 Ct-1' 벡터에 대해서 새로운 정보를 추가하는 역할을 한다. 크게 탄젠트 함수 부분과 시그모이드 함수 부분 두 가지로 구성된다.

탄젠트 함수 안의 벡터는 1xh 형태. 그리고 해당 벡터의 각 원소에 탄젠트 함수를 적용해서 -1~1 사이의 값을 반환한다. 이를 통해서 정답 맞추는 데에 긍정적인 역할을 하면 1에 가까운 값으로, 부정적인 역할을 하면 -1에 가까운 값으로 변환하여 출력한다.

또한 시그모이드 함수 부분은 정답을 맞히는데 기여하는 정도에 따라서 비율을 다르게 적용한다.

최종적으로 ct-1'에 더해서 ct로 업데이트한다.
📌 3. Output 게이트


output gate에서는 forget, input gate를 지나서 업데이트 된 기억 셀 ct를 이용해서 LSTM 층의 최종 출력 값인 ht를 계산한다.
ct 원소 중에서 중요한 원소의 비중은 크게, 아닌 것은 작게 수정해서 ht를 계산한다. output gate도 마찬가지로 시그모이드와 탄젠트 두 부분으로 구성되어 있다.

ht-1, xt값에 시그모이드 함수를 사용해서 중요한 원소의 비중(기여도)을 계산한다.

ct 원소들의 긍정/부정 역할을 계산하기 위해서 탄젠트 함수를 적용한다.

time step=t 에서 모든 게이트를 포함한 LSTM의 구조를 살펴보면 위와 같다.

하나의 LSTM에서 출력된 값은 다음 LSTM 층으로 전달된다.
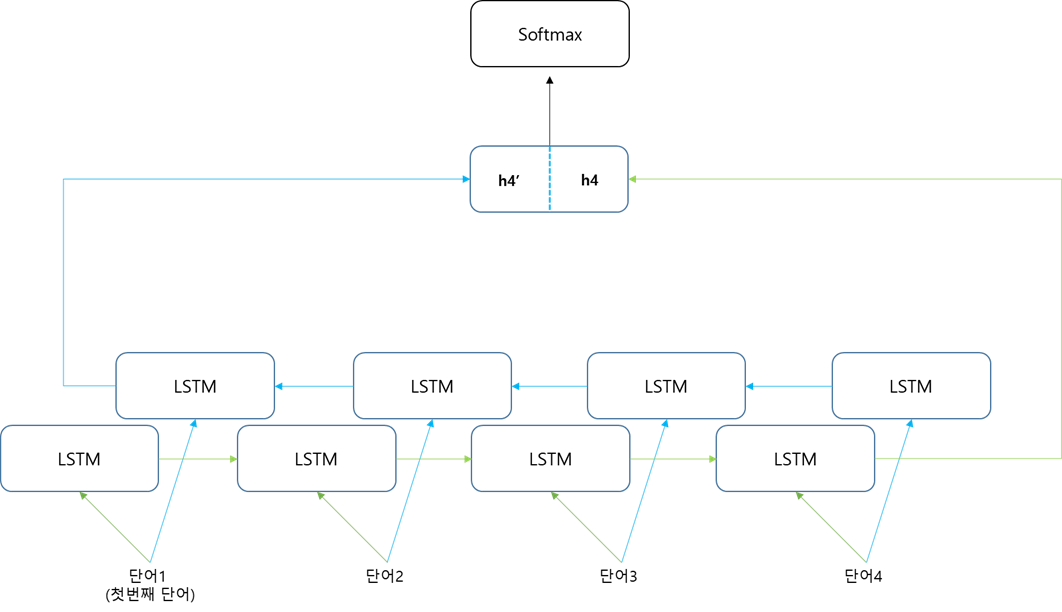
📚Bidirectional LSTM (양방향 LSTM)
일반적인 LSTM은 순방향(왼쪽에서 오른쪽)으로 정보를 추출하지만 역방향의으로도 정보를 추출해서 이용할 수 있다. 이를 양방향 LSTM이라고 한다. 일반적으로 양방향 LSTM을 사용할 경우 시퀀스 데이터에서 더 많은 정보를 추출할 수 있기 때문에 성능이 더 좋게 나타난다.
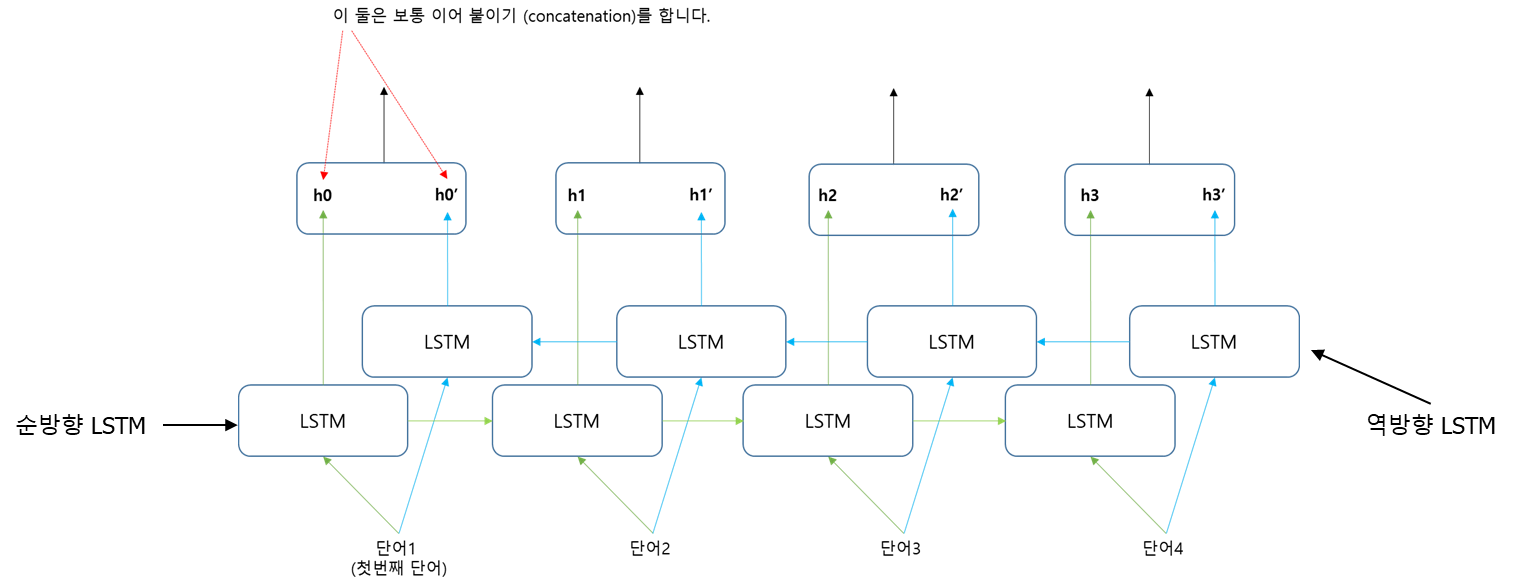
h4' h4는 각각 h개의 원소를 가지고 있다. 이를 맨 위에서 이어 붙여서 2hx1 크기로 만들고 다음 층으로 전달한다
📚 예제 코드
model = models.Sequential()
model.add(layers.Embedding(max_features, 128, input_length=maxlen))
model.add(layers.Bidirectional(layers.LSTM(64)))
model.add(layers.Dense(2, activation = 'softmax'))
model.summary()3번 라인에서 인자로 노드 수 지정. 노드 수=hidden state vector의 원소수 # 가장 마지막에는 순방향/역방향의 벡터가 합치기 때문에 마지막에는 128개의 노드가 나타난다.
📚 GRU 참고



📚 Reference
• 연세대학교 디지털사회과학센터(CDSS) 파이썬을 활용한 딥러닝 기초 워크숍, 이상엽 교수님
• LSTM 개념 설명 참고
https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
'머신러닝, 딥러닝 > 딥러닝' 카테고리의 다른 글
| 오토인코더(Autoencoder), 합성곱 오토인코더(Convolutional Autoencoder) (1) | 2022.01.21 |
|---|---|
| Transfomer 기본 개념 정리 (2) | 2022.01.20 |
| Stacked RNN (0) | 2022.01.19 |
| CNN을 이용한 텍스트 분류 (0) | 2022.01.18 |
| CNN 사전학습 모델을 이용한 이미지 분류 (3) | 2022.01.18 |




댓글