◈ CNN을 사용해서 텍스트 감성 분석 수행하기
✅ 기본 개념 설명
• CNN은 필터를 이용해서 핵심 정보를 추출하기 때문에, 텍스트 데이터를 분석하더라도 기본적으로 3차원 형태로 표현해야 한다.
• (n, m, c) 형태로 표현한다.
n : 문서의 길이를 의미함. 즉, 문서를 구성하는 최대 단어 수 (문서의 길이는 동일하게 통일시켜야 함)
m : 한 단어를 표현하는 임베딩 벡터의 차원 (단어를 저차원의 임베딩 벡터로 변환할 때, 각 벡터가 가지고 있는 벡터 차원을 의미함)
c : 이미지 데이터에서 채널 수, 텍스트 데이터는 1
✔ 예시 :
문서 : The movie was intersting and enjoyable
n=8, m=5, c=1

문서를 임베딩 벡터로 표현한 것을 하나의 이미지로 간주할 수 있다. 여기서 하나의 row가 한 단어를 나타낸다. 따라서 이미지 인식과 동일하게 필터를 이용해서 이 문서의 정보를 추출할 수 있다.
텍스트 분석에서 CNN 필터의 가로의 길이는 벡터 차원과 동일하게 결정된다. (n=5) 텍스트 분석에서 depth는 항상 1로 고정이다.
사용자가 설정하는건 n과 stride 값이다.
여기서 CNN을 이용한 텍스트 분석에서는 필터가 정사각형이 아니라 직사각형 형태임을 유의해야 한다.
이 필터는 가로로 꽉 찬 형태이기 때문에, 세로로만 움직인다. 한 방향으로만 움직이기 때문에 Conv1D 클래스를 사용한다.
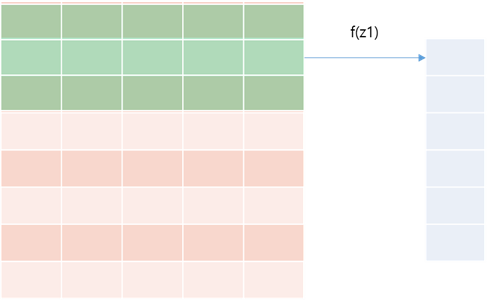
위의 그림은 8x5 이미지에 3x5 크기의 필터를 적용한 것이다. 필터는 위아래 방향으로만 이동하고, 결과로 n-k+1 크기의 1d array가 출력된다. 필터가 아래로 이동하면서 단어 간의 순서를 파악하기 때문에 문서의 정보를 보다 잘 추출할 수 있다.

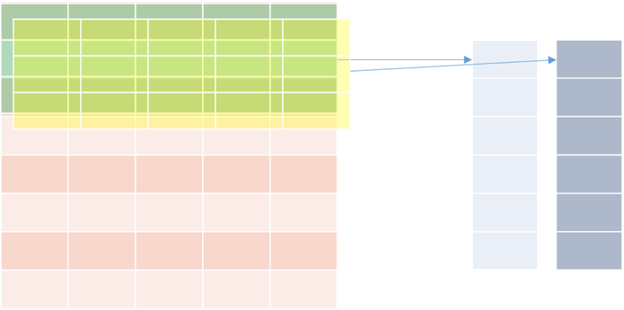
1차적으로 도출된 activation map에 pooling 필터를 적용할 수도 있다. 활성맵에 붉은색의 3x1 pooling 필터를 적용하면, 2x1 형태의 activation map이 리턴된다. 여기서 pooling 필터의 가로 크기는 1로 고정된다. 또한 풀링 필터의 stride 값은 풀링 필터의 크기와 동일하게 적용된다.
ex) 3X1 크기의 필터의 stride 값은 3이다. 그 결과 각 활성맵에서 2x1 크기의 활성맵이 2개가 추출된다.
어떤 크기의 필터가 좋은 지는 주어진 데이터마다 다르다. 따라서 이리저리 시도를 해 보는 수 밖에...
◈ 실습
IMDB 데이터를 이용한 실습
from tensorflow.keras.datasets import imdb
max_features = 10000 #해당 데이터셋에서 빈도수 기준 상위 10000개 단어만 사용
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)케라스에 포함되어 있는 imdb 데이터 사용함. 빈도 수 기준으로 상위 10000개에 해당하는 데이터만 가져온다.
from tensorflow.keras.preprocessing import sequence
max_len = 500
x_train = sequence.pad_sequences(x_train, maxlen=max_len)
x_test = sequence.pad_sequences(x_test, maxlen=max_len)문서의 길이를 500으로 통일하도록 설정. 길이가 길면 truncation이 실시되고, 짧은 경우에는 pad_sequences 함수 이용해서 padding을 실시한다. 모든 단어를 다 사용하고 싶은 경우에는 주어진 데이터에서 길이가 가장 큰 데이터로 맞추면 된다. 하지만 이것이 항상 가장 좋은 성능을 보장하는 것은 아님. padding은 문서 앞, 뒤 크게 영향이 없다.
#원 핫 인코딩
from tensorflow.keras.utils import to_categorical
y_train_one_hot = to_categorical(y_train)
y_test_one_hot = to_categorical(y_test)
from tensorflow.keras.models import Sequential
from tensorflow.keras import layers
#모델 구축
model = Sequential()
model.add(layers.Embedding(max_features, 128, input_length=max_len)) #텍스트 데이터를 임베딩 벡터로
model.add(layers.Conv1D(32, 7, activation='relu')) #필터수 : 32 / 필터 세로 : 7 / 가로는 128로 고정
model.add(layers.MaxPool1D(5)) #5 : 풀링 필터의 세로의 길이 / 가로 길이는 1로 고정임 / stride는 자동으로 5로 고정됨
model.add(layers.Flatten())
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(2, activation='softmax'))
model.summary()
n x m x c : 128 x 500 x 1 형태로 데이터를 만든다. 임베딩 벡터의 차원 128개로 설정해서 각 문서를 500x128 차원으로 만든다.
필터의 가로 크기는 단어의 임베딩 벡터의 크기와 같다. 여기서는 필터의 세로 크기를 7로 32개를 적용했다.
결과적으로 494x32 형태로 값이 리턴된다.

라인14 에서 세로 크기 5인 풀링 필터를 적용하면, stride=5로 자동으로 설정된다.
maxpooling을 실시했으므로 494/5 = 98.8 이다.

텍스트 분석에서는 필터가 위아래 한 방향으로만 이동하기 때문에, Conv1D 클래스를 사용한다. 총 140만개의 파라미터가 존재함을 알 수 있다.
from tensorflow.keras.optimizers import RMSprop
model.compile(optimizer=RMSprop(learning_rate=0.001), loss='binary_crossentropy', metrics=['acc'])
history = model.fit(x_train, y_train_one_hot, epochs=10, batch_size=128, validation_split=0.2)분류 문제이기 때문에 크로스 엔트로피로 설정하고, RMSprop 옵티마이저를 사용한다.
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()
test_loss, test_acc = model.evaluate(x_test,y_test_one_hot)
test_acc
test set 에서 accuracy가 86% 정도로 나타난 것을 확인할 수 있다.
◈ 한글 영화 리뷰 데이터 예제
CNN_sentiment_Korean 파일 참고
◈ Reference
• 연세대학교 디지털사회과학센터(CDSS) 파이썬을 활용한 딥러닝 기초 워크숍, 이상엽 교수님
'머신러닝, 딥러닝 > 딥러닝' 카테고리의 다른 글
| LSTM, Bidirectional LSTM (0) | 2022.01.19 |
|---|---|
| Stacked RNN (0) | 2022.01.19 |
| CNN 사전학습 모델을 이용한 이미지 분류 (3) | 2022.01.18 |
| CNN 사전학습 모델 - LeNet / AlexNet / VGGNet / InceptionNet / ResNet / DenseNet / MobileNet / EfficientNet (0) | 2022.01.17 |
| RNN(순환신경망) 기본 (0) | 2022.01.14 |




댓글