📚 사전학습 모형(pre-trained model)의 종류와 개념
✅ CNN 기본 개념
📌 CNN 요약

이미지 데이터는 여러 개의 픽셀로 구성되어 있고, 한 개의 픽셀은 3개의 색상정보를 저장하고 있다. 일반 신경망으로 이미지 데이터를 학습할 경우 3차원 이미지를 1차원으로 변환해서 입력하는 과정에서 정보 손실이 발생한다. 또한 파라미터가 굉장히 많아지기 때문에 과적합 가능성이 증가한다. 따라서 CNN은 필터를 이용해서 이미지의 각 부분의 정보를 추출한다. 필터는 이미지의 각 셀들과 내적 연산을 수행(합성곱)하면서 activation map을 생성한다. 이렇게 생성된 activation map은 또 하나의 이미지로 보고 다시 필터를 통해서 정보를 추출하는 과정을 반복한다. 그리고 최종적으로 1차원 데이터로 변환해서 softmax 함수를 출력층에 사용해서 이미지를 분류한다.
📌 CNN을 사용한 이미지 분류 방법 2가지
| 구분 | 설명 | ||
| 1. | 사용자가 직접 CNN 생성 | - 직접 ConvNet2D를 여러개 쌓아서 신경망 구축 - 단점 : 정교한 모형 구축하는데에 많은 시간 / 데이터 / 컴퓨팅 파워가 필요하다 |
|
| 2. | 사전학습 모델 사용 | • 사전 학습 모델이란 이미 방대한 양의 학습 데이터를 이용해서 학습을 완료한 모델이다. 해당 모델의 구조와 파라미터 최적값이 학습을 통해서 정해져 있다. • 성능이 좋은 정교한 모형을 사용할 수 있고, 오랜 시간과 컴퓨팅 파워를 사용해서 대용량 데이터를 학습한 모델을 효율적으로 사용할 수 있다. |
|
| 2-1. 학습모델 그대로 사용 | • 원래 모델을 그대로 사용하는 방식으로, 새로운 task가 사전 학습 모형의 task와 유사한 경우에 적용할 수 있다. •하지만, 사전학습 모형은 대부분 ImageNet 대회에서 우승한 모델이기 때문에 대부분의 종속변수 클래스가 동물이라는 점을 유의해야 한다. |
||
| 2-2. 전이학습 (Transfer Learning) |
• 사전학습 모델의 파라미터나 구조를 일부 변형해서 사용하는 방법 새로운 학습 데이터가 필요하지만, 완전히 모델을 새로 만드는 것 만큼 많은 데이터가 필요하지는 않다. |
||
CNN을 사용해서 이미지를 분류하는 방식에는 크게 사용사가 직접 CNN 모델을 구축하는 방법과, 사전 학습 모델을 사용하는 방법으로 구분할 수 있다. 사전학습 모델을 사용하는 과정에서는 해당 모델을 그대로 사용할 수도 있고 모델의 일부를 수정하는 전이학습을 사용할 수도 있다.
✅ 주요 사전학습 모델의 출처
주로 ILSVRC 대회(imagenet 경진대회)에서 상위권에 뽑힌 모델을 주로 사전학습 모델로 사용한다.


Image Net 경진대회에는 총 128만개의 학습 데이터와 5만개의 테스트 데이터를 제공한다. 총 1000개의 종속변수 이미지 클래스가 포함되어 있으며 대부분 동물에 관한 데이터이다.(https://gist.github.com/aaronpolhamus/964a4411c0906315deb9f4a3723aac57)
✅ LeNet

LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
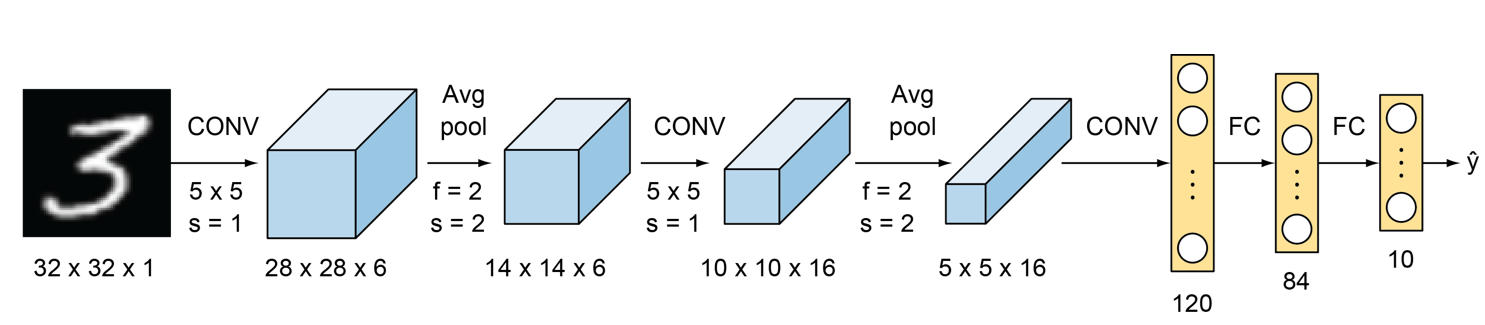
• 최근에는 사용되지 않지만, 기본적인 CNN 구조를 가장 처음 제안한 모델이라는 점에서 의의가 있음
• 세 번의 합성곱 필터와 2번의 average pooling을 사용한 구조이며, tanh 활성화 함수와 average pooling을 사용했는데 최근에는 이 방식을 사용하지 않는다.
• 첫 번째 activation map의 depth=6 이므로, 6개의 필터를 적용했다는 것을 알 수 있다.
✅ AlexNet

Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 1097-1105.
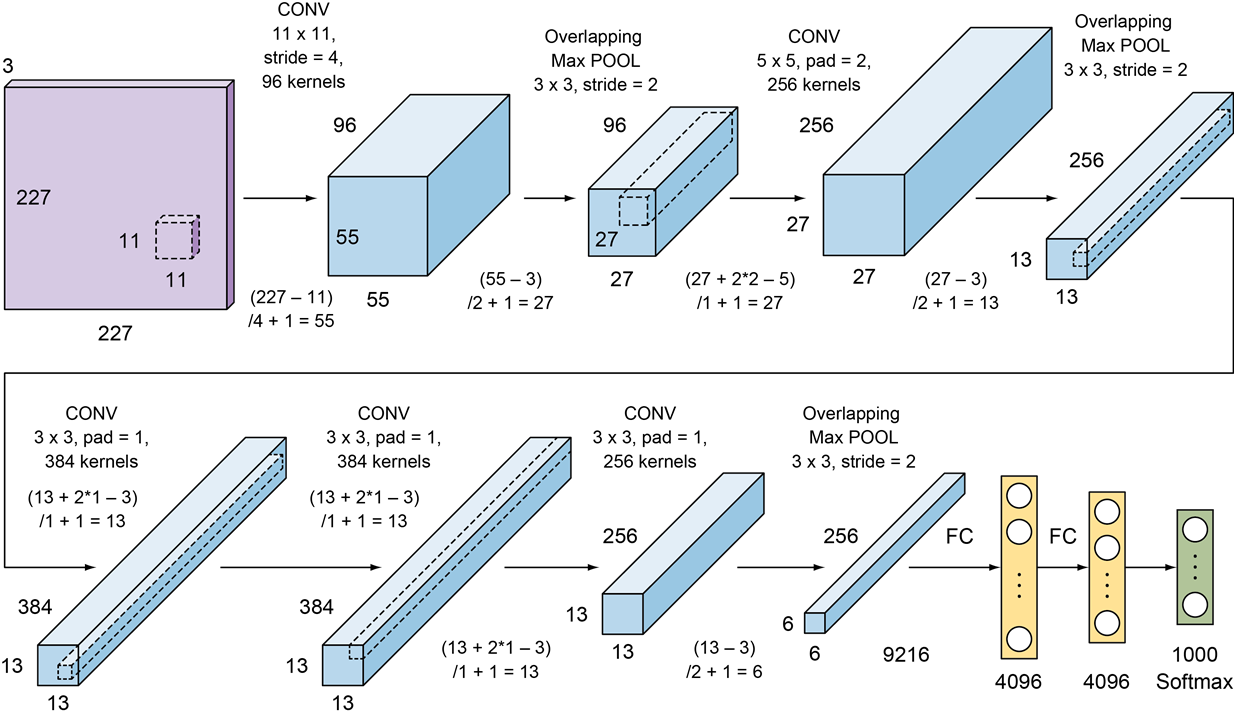
• 1998년 LeNet이 제안된 이후 CNN 알고리즘의 뚜렷한 성능 개선이 이루어지지 않았는데, 이러한 CNN 침체기를 깨면서 2012년 이미지넷 경진대회에서 우승한 모델이다. 비교적 구조가 간단해서 최근에는 많이 사용되지 않음
• LeNet과 유사하게 여러 개의 합성곱 필터와 풀링 레이어를 가지고 있다는 것은 동일하지만,
활성화 함수로 relu로 사용하고 max pooling을 사용했다. 5개의 합성곱 층과 3번의 풀링을 사용함.
• 11x11크기로 stride=4 인 96개의 필터(커널)을 적용함.
최근에는 3x3 이나 5x5 크기의 필터를 사용하는데 여기서는 11x11로 큰 크기의 필터를 사용했다.
필터의 크기가 큰 경우에는 파라미터의 수가 많아져서 모델이 복잡해지기 때문에 과적합이 자주 발생할 가능성이 높다.
또한 이미지에서 정보를 추출하는 횟수가 적기 때문에, 올바르게 학습이 이루어지지 않을 수도 있다.
하지만 그렇다고 무조건 필터의 크기가 작다고 유리한 것은 아니며, stride와 같은 파라미터에 의해서 달라진다.
✅ VGGNet

Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
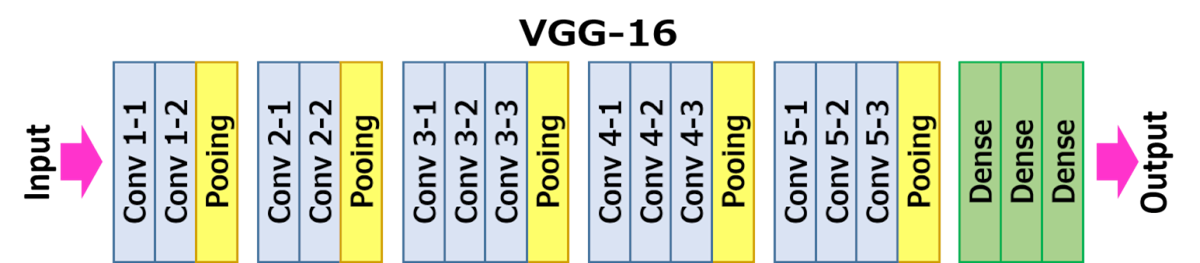
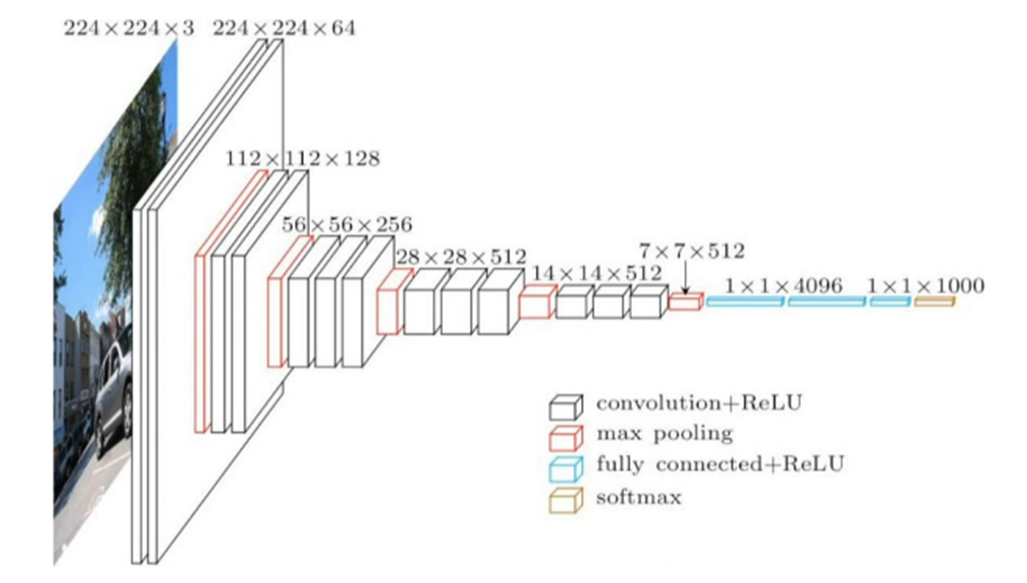
• 2014년 옥스포드 VGG그룹에서 제안된 모델로 이미지넷 대회에서 준우승한 모델
• 전체적인 구조는 AlexNet과 유사하지만 3x3필터를 stride=1로 설정해서 반복해서 적용한다. pooling layer를 제외하고 총 16개 층이어서 VGG-16이라고 부른다. pooling layer에는 2x2로 max pooling을 stride=2로 해서 적용한다.
• VGG-16 과 VGG-19가 있는데 주로 16 버전이 사용된다. 같은 년도 대회에서 우승 모델은 Inception Net이지만 VGG-16이 비교적 구조가 간단하고 사용이 편리해서 더 많이 사용된다(ResNet 다음으로 많이 사용됨).
✅ InceptionNet ( = Google Net)

Szegedy et al. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9).
• 구글에서 제안한 2014년 이미지넷 경진대회 우승 모델
인셉션 모듈이라는 방식을 사용해서 모델 성능을 개선시킴. 인셉션 모듈은 이후 모델에서 지속적으로 사용되고 있음

📌 Inception Module :
• 일반 CNN 모델은 층마다 ConvNet을 한 번만 수행한다. 따라서 합성곱 필터의 크기와 풀링 레이어의 사용 위치가 모델의 성능을 구분하는 핵심 요소였다. 구글 팀에서는 이전 층에서 입력되는 값에 대해서 합성곱 필터와 풀링 필터를 포함해서 여러개의 필터를 한번에 적용했다. 이 층을 인셉션 모듈이라고 하고, 이 방식을 통해서 각 층에서 더 다양한 정보를 추출하면서 학습 속도를 개선한다.
• 서로 다른 크기의 필터를 적용하기 때문에 return 하는 activation map 의 가로x세로 크기가 다르게 나타난다. 따라서 이 크기를 통일하고 depth-wise로 합치기 위해서 padding을 사용한다.
📌 Inception Module의 차원 감소 : Bottle Neck 구조


여러 개의 필터를 한번에 사용하면 파라미터의 수가 증가한다. 이는 모형이 복잡해져서 과적합 문제가 발생할 가능성이 증가한다는 것을 의미한다. 따라서 inceiption Net은 이 문제를 해결하기 위해서 중간에 1x1 필터를 추가하여 차원을 감소시킨다.
좌측 이미지)
depth=32인 이전 단계의 활성맵에 3x3필터를 64개 적용하면 3x3x32x64의 파라미터가 생성된다.
우측 이미지)
3x3필터를 적용하기 전에, 중간 단계에 1x1x32 형태의 필터를 추가한다. 여기서 중간층의 depth=16은 임의로 설정한 것.
중간 층의 depth는 반드시 입력층의 depth(32) 보다 작아야 함
중간층을 거쳐서 최종 deptth=64인 활성맵을 만들면 총 파라미터의 수가 (1x1x32x16) + (3x3x16x64) = 9728로 감소한다.
이러한 구조를 bottle neck 구조라고 한다. (depth의 수가 32 -> 16 -> 64 로 병목처럼 변화하기 때문)

인셉션 넷은 층의 수가 많기 때문에 앞쪽 층의 파라미터 업데이트가 이루어지지 않는 경사소실 문제가 발생할 가능성이 높다.
따라서 이 문제를 해결하기 위해서 인셉션 넷은 추가 분류기를 사용한다. 기본적인 분류 모델은 가장 마지막에 메인 분류기만 사용하는데, 이 경우 앞 층 까지 파라미터 업데이트가 완전히 진행되지 않는다. 따라서, 인셉션 넷은 중간에 추가 분류기를 추가해서 종속변수 예측치를 도출한다. 그리고 이 예측치를 통해서 새로운 비용함수를 계산해서 앞쪽 층의 파라미터 업데이트를 실시한다. 추가 분류기는 학습 과정에서만 사용된다.

따라서 인셉션 넷의 최종 비용함수는 위와 같이 정의된다.
✅ ResNet (Residual Network)

He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
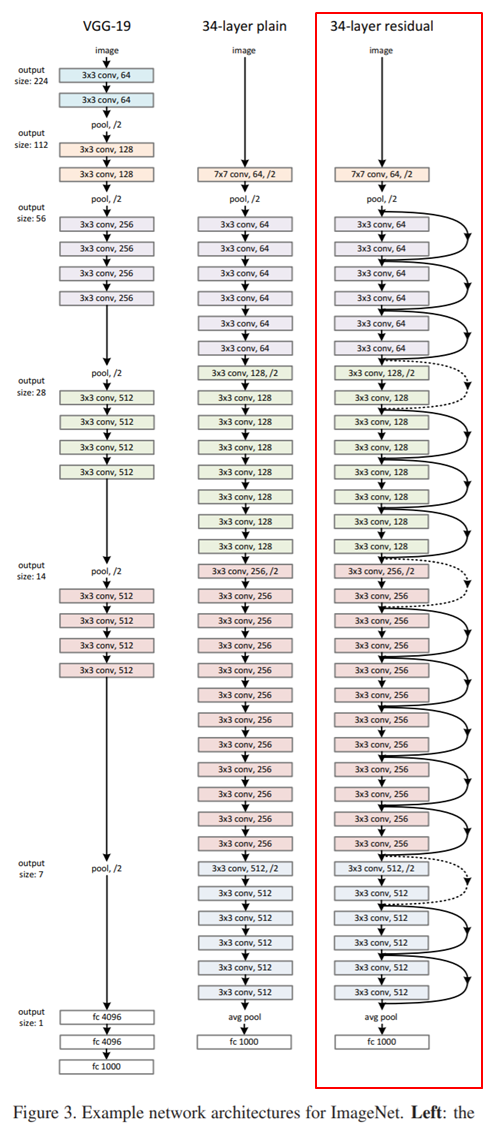
• 마이크로소프트에서 제안하고 2015년 이미지넷에서 우승한 모델. 당시 최초로 사람의 분류 성능을 뛰어넘으면서 인공지능에 대한 기대가 증가하게 되는 계기가 되었다. 최근까지 가장 많이 사용되는 사전학습 모델이다.
• 좌측은 VGG-19 모델, 중간은 레이어가 34개로 더 깊어진 구조, 우측이 34개의 레이어를 가진 residual net 구조이다.
📌 층이 많을 경우 문제점과 원인

일반적으로 위의 그림과 같이 신경망이 깊어지면 오히려 오차가 증가한다. 해당 논문에서는 파라미터 증가로 과적합이 발생하는 것은 특정 시점까지이고, 그 이후부터는 성능이 일정하게 유지된다는 것을 실험을 통해 밝혔다. 즉, 위의 우측 그래프에서 볼 수 있듯이 층의 갯수가 많아지는 것은 과적합의 주요 원인이 아니었다.
→ 과적합을 발생시키는 원인은 '경사 소실(Gradient Vanishing)'로 인한 파라미터 업데이트가 이루어지지 않는 것이었음.
따라서 ResNet에서는 이러한 경사 손실의 문제를 해결하기 위해서 Skip Connection 이라는 구조를 사용한다.
📌 ResNet의 핵심 아이디어
레이어의 수가 성능 저하의 원인이 아니므로, 레이어가 증가해도 성능이 저하되어서는 안된다고 생각함. 적어도 더 얕은 네트워크(shallower network)만큼의 성능이 나와야 한다는 아이디어 떠올림.
따라서 입력값을 그대로 출력하는 identity mapping을 추가하더라도, 그것을 추가하지 않은 네트워크 만큼의 성능이 나와야 함.
따라서, 다음과 같은 핵심 아이디어를 기반으로 모델 생성한다.
입력값을 이용해서 출력값을 완전히 새로 계산하는 것이 아니라, 입력값과 원래 출력하고자 하는 값의 차이(residual)만을 새롭게 학습하자


x : 입력값
H(x) : 해당 층에서 원래 출력하고자 하는 값.
F(x) = H(x) - x : 잔차
Skip connection 구조에서는 입력값을 바로 출력에 연결하는데 H(x)=F(x)+x 로 표현할 수 있고, F(x)=0(잔차가 0)이 되도록 학습한다. 이렇게 할 경우 미분을 했을 때 0이 되어 F(x)=0으로 소실 되더라도, H(x)=0+x 에서 x의 1이 남아있기 때문에 경사 소실이 해결된다. 또한 이 구조에서는 단순히 더하기만 추가되기 때문에 연산량에서도 부담이 없다.
기존 모델에서는 최적의 H(x)를 찾는 방향으로 학습하면서 weight를 수정한다. 반면 ResNet은 잔차인 F(x)를 감소시키는 방향으로 학습한다.
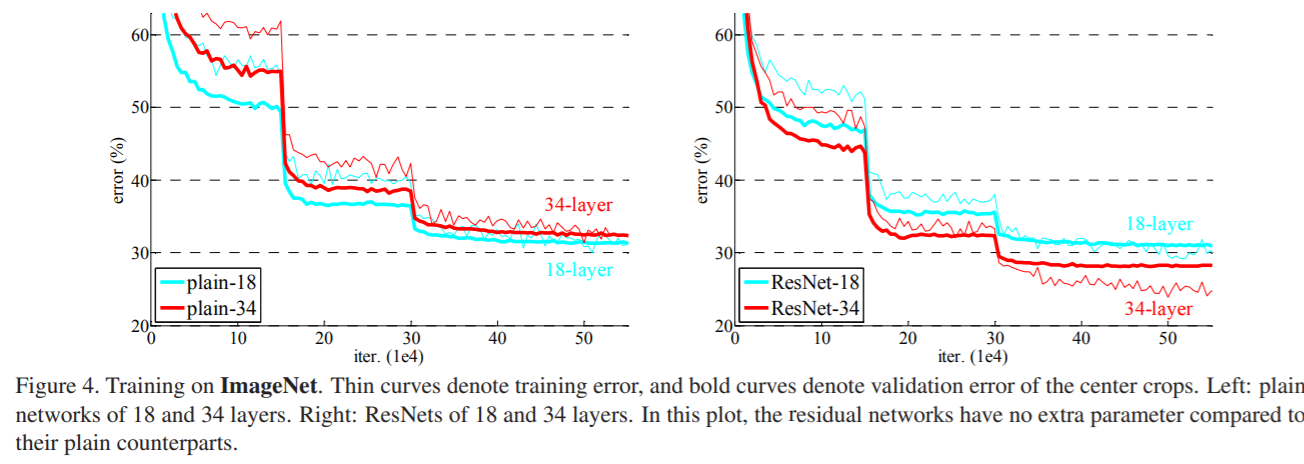
논문의 실험 결과를 살펴보면 좌측 일반 신경망 구조에서는 레이어 수가 많아질수록 성능이 감소하지만, 우측 그림에서 잔차를 이용한 학습 방식에서는 레이어 수에 따라서 성능이 개선된다는 것을 알 수 있다.
✅ MobileNet

Howard et al., (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.
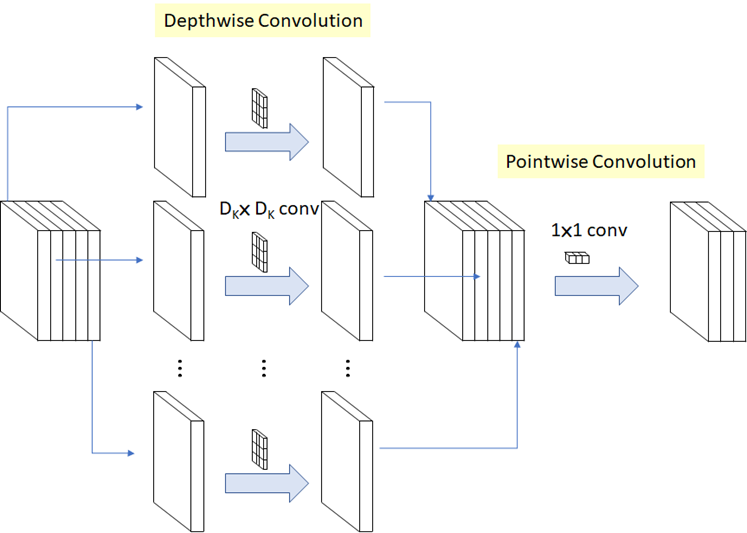
• 모바일과 같이 컴퓨팅 파워가 부족한 기기에서 이미지 분류를 하기 위해서 개발된 모델
depth=5인 activation map 의 채널(depth)별로 depth=1인 필터를 적용한 모델. 그리고 최종적으로 인셉션 넷과 동일하게 마지막에 1x1 필터를 적용하는 보틀넥 구조를 사용함.
• 성능은 크게 감소시키지 않으면서 파라미터 수를 감소시켜서 빠르게 학습이 가능하다.
✅ DenseNet

Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700-4708).
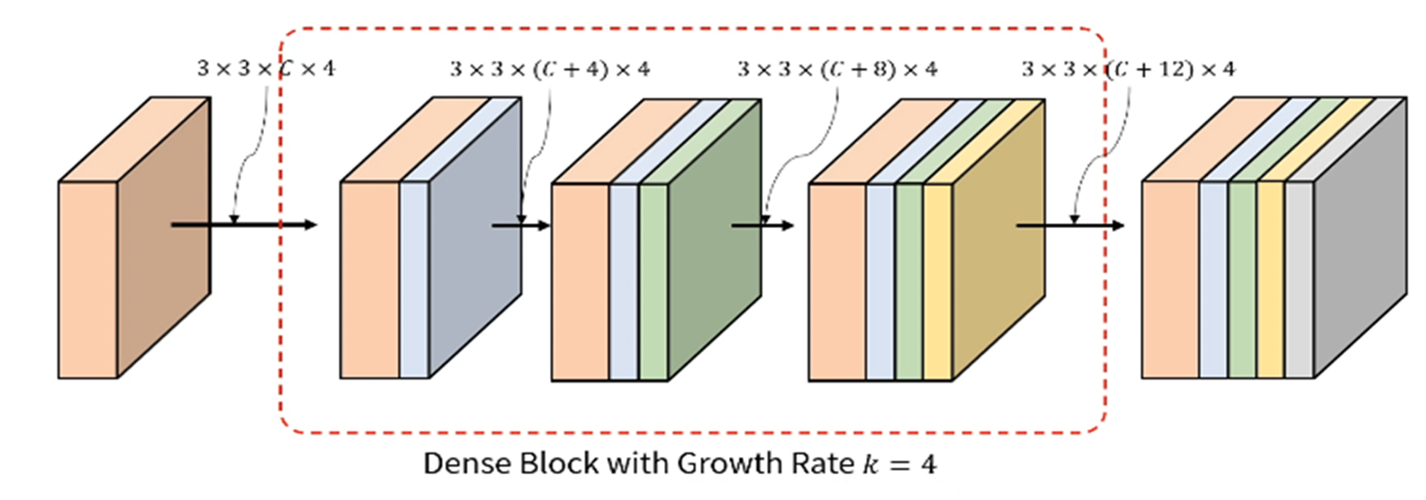
• ResNet의 문제점을 보완. 이 페이퍼에 따르면 identity mapping layer에서 x + F(x) 로 입력값과 출력값을 단순히 더해서 출력하는 것은 정보의 흐름을 방해할 수 있다고 주장함. DenseNet 이 값을 더한게 아니라 depth-wise로 그냥 이어붙이기 한 것.
두 번째 그림의 빨간색 부분의 depth = C, 파란색 부분 depth =4 . 따라서 이 활성맵에 적용되는 필터의 depth=C+4
초록색 부분의 depth=4
✅ Efficient Net
• 2019년 구글에서 제안한 비교적 최신 기법이다. 사전학습 모형으로 많이 사용되지는 않는다.
•compund scaling method를 사용함. Width / Depth / Reolution 등을 고려해야 하는데 컴퓨터의 성능에 따라서 적절하게 선택해야 한다. 따라서 사용자의 환경에 따라서 다르다.
📚 Reference
• 연세대학교 디지털사회과학센터(CDSS) 파이썬을 활용한 딥러닝 기초 워크숍, 이상엽 교수님
• Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 1097-1105.
• Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
•Szegedy et al. (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1-9)
• He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770-778).
• Howard et al., (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.
•Tan, M., & Le, Q. (2019, May). Efficientnet: Rethinking model scaling for convolutional neural networks. In International Conference on Machine Learning (pp. 6105-6114). PMLR
'머신러닝, 딥러닝 > 딥러닝' 카테고리의 다른 글
| CNN을 이용한 텍스트 분류 (0) | 2022.01.18 |
|---|---|
| CNN 사전학습 모델을 이용한 이미지 분류 (3) | 2022.01.18 |
| RNN(순환신경망) 기본 (0) | 2022.01.14 |
| CNN(합성곱 신경망) 기본 (0) | 2022.01.13 |
| 딥러닝 기본 개념 - 신경망 구조, 활성화 함수, Optimizer (0) | 2022.01.11 |




댓글