◈ 개념
✔ 목표 : 동질적인 데이터를 하나의 그룹으로 묶는 것. 대표적인 비지도 학습 방식.
• exploratory method로 데이터의 그룹에 대한 사전 지식이 필요 없으며, 주로 다른 데이터마이닝 기법 적용 전에 사용되는 경우가 많다.
• 지도학습 기법에서도 해석가능성이 중요하지만, 클러스터링은 특히 해석 가능성이 중요하다. 아무리 깔끔하게 클러스터링 시각화가 가능하더라도, 해석이 모호하면 무용지물.
✅ Distance 계산
✔ Euclidean Distance :

• 변수가 4개 이상으로 많아지면 시각적으로 클러스터 확인이 어렵기 때문에, 유클리드 거리를 자주 사용함
• 각 변수의 scale의 영향을 받기 때문에, 정규화를 필수적으로 해야함.
• 그 외 distance measure
✔ Categorical 변수의 거리 계산? (Distance for Binary data)
① Matching Coef. = (a+d) / n
② Jaquard's Coef. = d / (b+c+d)
• 자카드 계수는 발생한 사건에 중요도를 두기 때문에, 0인 사건(a)는 무시하고 계산함
✅ 클러스터 간의 거리를 계산하는 방법
• 계층적 클러스터링 방법에서, 서로 다른 클러스터를 하나의 클러스터로 묶을 때 사용하는 기준
① Minimum Distance : 두 클러스터에서 가장 가까운 거리를 계산
② Maximum Distance : 두 클러스터에서 가장 먼 거리를 계산
③ Average Distance : 두 클러스터의 평균 거리를 계산
④ Centroid Distance : 두 클러스터 중심의 거리를 계산
✅ 계층적 클러스터링 (Hierarchical Clustering)
✔ Agglomerative Methods : 합병에 의한 방법 (cf. Divisive Methods : 분할에 의한 방법)
• 미리 클러스터의 수를 지정하지 않음
• 개별 레코드가 하나의 클러스터로 간주하고 시작
• 가장 가까운 두 개의 클러스터를 하나의 클러스터로 결합
• 이러한 step by step 과정을 Dendrogram 으로 표시 가능함
ex) 아래 그림에서 (1,18), (14,19)가 각각 클러스터로 분류되었고, 이 두 클러스터가 상위 단계에서 하나의 클러스터로 결합함
• 계층적 군집화에서 상위 클러스터로 결합할 때의 기준은 다음과 같음.
| 클러스터 결합 방식 | 설명 |
| Single Linkage | 상위 클러스터로 결합 시, minimum distance 사용함 |
| Complete Linkage | 상위 클러스터로 결합 시, maximum distance 사용함 |
| Centroid Linkage | 상위 클러스터로 결합 시, Centroid Distance 사용 |
| Average Linkage | 상위 클러스터로 결합 시, Average Distance 사용 |
• Dendrogram에 수평선을 그어서 적절한 클러스터의 구성과 수를 선정해야 함
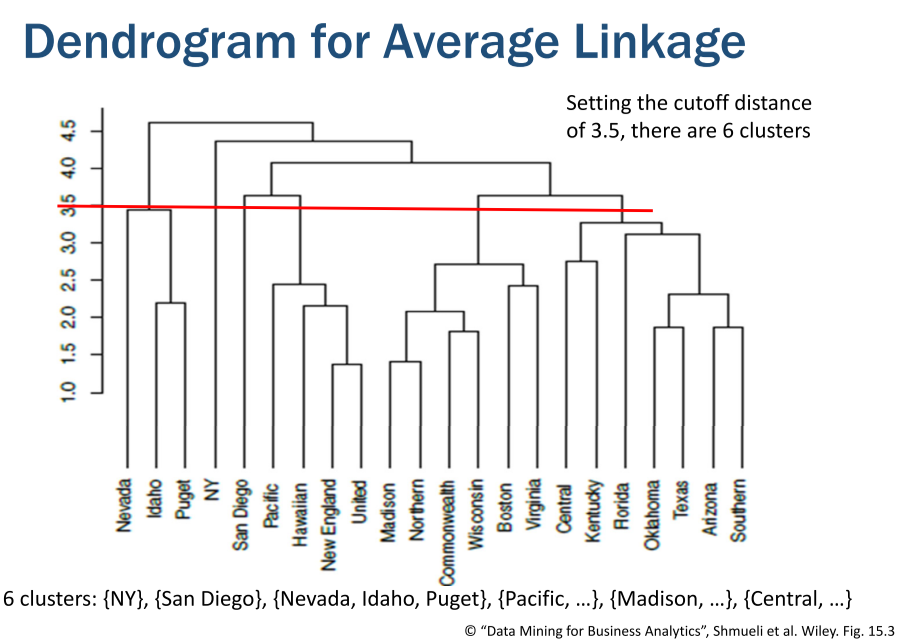
✅ 비계층적 클러스터링 (Non-Hierarchical Clustering)
• 대표적으로 K-means clustering
• 사전에 클러스터의 수를 정해야 함
<K-means 실행 단계 >
• 임의로 데이터를 k 개의 그룹으로 나눔
• 각 그룹의 중심점 계산하고, 중심점에서 가까운 레코드를 찾아서 클러스터 업데이트
• 위 과정을 계속 반복해서, 더이상 중심점이 변화하지 않을 때 까지 반복함
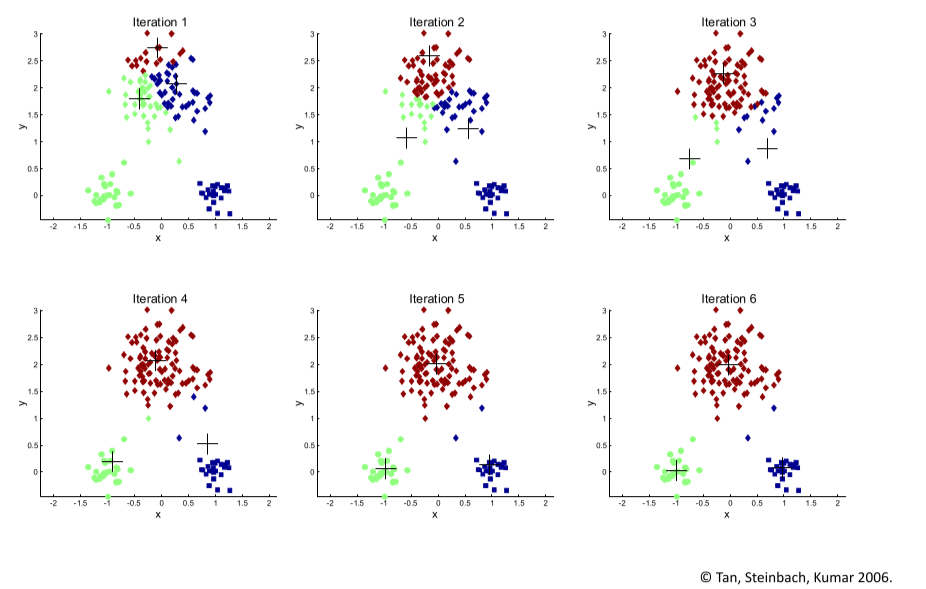
✅ 클러스터링 평가
• 통계적 검증
A, B 클러스터를 비교할 때, A 내부의 레코드간의 거리와 A와 B 클러스터의 차이가 유의미한지 통계적으로 확인
• train / test
데이터를 분리해서, 각 데이터셋에서 동일하게 클러스터가 나타나는지 확인
• 분석 목적에 부합하는 지 평가
클러스터링을 실시한 경우에는 해당 클러스터의 수와 구성 레코드가 분석 목적에 맞도록 유의한지 확인해야 함
◈ 참고자료 출처
•Data Mining for Business Analytics: Concepts, Techniques, and Application in R" by R, Galit Shmueli, Peter C. Bruce, Inbal Yahav, Nitin R. Patel, Kenneth C. Lichtendahl Jr. Wiley. 1st edition. Wiley, 2017.
'머신러닝, 딥러닝 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 선형회귀 (Linear Regression) (0) | 2022.03.14 |
|---|---|
| [머신러닝] 지도학습 / 경사하강법 / 규제화 (0) | 2022.03.07 |
| [머신러닝] Decision Tree (0) | 2021.10.13 |
| [머신러닝] Naive Bayes 개념 정리 (0) | 2021.10.08 |
| [머신러닝] KNN 개념 정리 (0) | 2021.10.06 |




댓글