◈ surprise 라이브러리 사용
✅ 라이브러리 소개

✔ 주요 제공 알고리즘
추천시스템 개발을 위한 패키지로 사이킷런의 일부이다. 주어진 데이터에 대해서 빠른 시간내에 결과를 확인하기 위해서 사용할 수 있다. 주어진 데이터에 대해서 surprise 패키지로 여러 알고리즘 중에 어떤 것이 성능이 좋은지 확인을 해보고, 직접 코드를 짜면서 최적화하는 방식으로 알고리즘을 정교화 할 수 있다.

여러 알고리즘을 자체적으로 제공하기 때문에 선택이 가능하다.
◈ 실습 : CF + KNN
# movielens 데이터 불러오기
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('C:/Users/Yeong/Desktop/추천시스템 강의/실습데이터/u.data', names=r_cols, sep='\t',encoding='latin-1')
#reader 클래스 이용해서 스케일링
reader = Reader(rating_scale=(1,5))
data = Dataset.load_from_df(ratings[['user_id', 'movie_id', 'rating']], reader)
#CV 실시해서 바로 결과 확인
result = cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=4, verbose=True)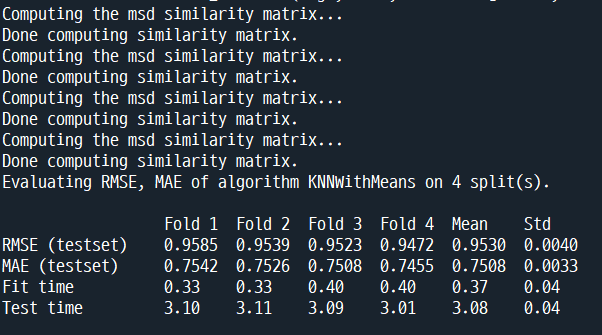
위와 같이 csv 데이터를 불러와서 surprise 패키지의 CV 함수를 사용하면 바로 결과를 확인할 수 있다.
#데이터 나누기
trainset, testset = train_test_split(data, test_size=0.25)
#파라미터 지정
sim_options = {'name': 'cosine','user_based': True}
#학습
algo = KNNWithMeans(k=40, sim_options=sim_options)
algo.fit(trainset)
#예측
predictions = algo.test(testset)
accuracy.rmse(predictions)
사이킷런 패키지와 유사하게 train/test를 나눠서 accuracy를 확인할 수 있다. 함수와 클래스가 조금 다르니까 유의.
sim_options에는 주로 CF 관련 알고리즘의 파라미터를 설정한다. name은 유사도를 무엇으로 할 것인지, user_based=False이면 item based CF가 실행된다. 여기서는 라인 8에서 이웃 크기를 40으로 설정했다.

개별 데이터에 대해서도 예측을 할 수 있다. 위에서는 유저 : 1, 아이템 : 2로 설정하고 예측을 실시한다. 위 결과에서 was_impossible : True인 경우에 학습 데이터셋에서 해당 유저나 아이템에 대한 정보가 없어서 예측이 안되는 경우를 의미한다.
✅ Grid Search 기능
서프라이즈 패키지는 편리한 grid search 기능을 제공한다.

실습 1. KNN 기반 알고리즘의 그리드서치
#라이브러리 불러오기
from surprise import SVD
from surprise import KNNWithZScore
# Importing other modules from Surprise
from surprise import Dataset
from surprise.model_selection import GridSearchCV #그리드 서치
# MovieLens 100K 데이터셋 불러오기
data = Dataset.load_builtin('ml-100k')GridSerachCV 라이브러리와 무비렌즈 데이터를 불러온다.
# 비교할 파라미터 입력
param_grid = {'k': [30, 35, 40, 45, 50],
'sim_options': {'name': ['pearson_baseline', 'cosine'],
'min_support': [1,2],
'user_based': [True, False]}
}
gs = GridSearchCV(KNNWithZScore, param_grid, measures=['rmse'], cv=4)
gs.fit(data)그리드서치를 수행할 파라미터 조합을 입력한다. 사용 알고리즘은 CF+KNN을 이용.
라인 4에서 min_support 는 특정 아이템에 대해서 rating 한 사람이 너무 낮으면 신뢰도가 떨어진다. 따라서 최소한의 평점을 남긴 사람의 숫자를 지정하는 파라미터이다. 총 5x2x2x2=40회의 조합을 테스트한다.
# 최고 RMSE 출력
print(gs.best_score['rmse'])
# 최고 RMSE의 parameter 출력
print(gs.best_params['rmse'])
여기서는 최적 K=40으로 나타났지만, 만약 50이나 30으로 나타났을 경우 위에서 설정한 범위 밖의 값에 대해서도 튜닝을 실시해야 한다.
실습2. SVD 알고리즘의 그리드 서치
# SVD 다양한 파라메터 비교
param_grid = {'n_epochs': [70, 80, 90], #에폭 수
'lr_all': [0.005, 0.006, 0.007], #학습률
'reg_all': [0.05, 0.07, 0.1]} #규제 텀 계수
gs = GridSearchCV(SVD, param_grid, measures=['rmse'], cv=4)
gs.fit(data)
# 최고 RMSE 출력
print(gs.best_score['rmse'])
# 최고 RMSE의 parameter
print(gs.best_params['rmse'])위의 KNN 알고리즘과 동일하게 라이브러리와 데이터를 불러온다.
SVD기반 알고리즘은 지정하는 파라미터의 종류에서 차이가 있다. 간단한 튜닝 과정인데도 알고리즘 자체의 연산량이 많기 때문에 시간이 어느 정도 소요된다.
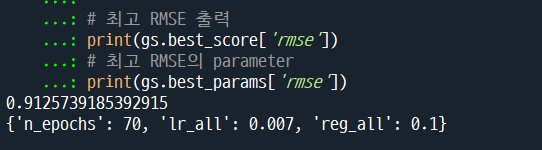
에폭=70이 최적으로 나왔기 때문에, 70보다 더 적은 에폭에 대해서도 테스트를 해봐야 한다.
◈ Reference
• "Python을 이용한 개인화 추천시스템", 임일, 청람
'추천시스템' 카테고리의 다른 글
| 추천 알고리즘 - Factorization Machines (0) | 2022.01.23 |
|---|---|
| 추천시스템에서 Binary Data의 사용 (0) | 2022.01.22 |
| 추천 알고리즘 - Matrix Factorization (0) | 2022.01.14 |
| 컨텐츠 기반 추천(Content Based Filtering) (0) | 2022.01.10 |
| 협업필터링 - 사용자의 평가 경향 고려 (0) | 2021.12.27 |




댓글