◈ 참고자료 출처
• "Python을 이용한 개인화 추천시스템", 임일, 청람
◈ 개념
✅ 사용자의 평가 경향 고려 : Bias-From-Mean Average
• 일반적으로 사용자마다 평점을 부여하는 기준이 다르기 때문에, 해당 평점이 가지는 의미도 다르게 된다. 같은 평점 3점을 부여했더라도 평균이 2점인 사용자와 평균이 4점인 사용자의 의미가 다르다. 즉, 평점을 계산할 때 해당 사용자의 평가 경향을 고려할 필요가 있다.
• 이러한 단점을 보완하기 위해서 원래 평점에서 해당 사용자의 평균 평점을 빼서, 다른 유저와의 유사도로 가중평균해서 예상 평점 계산한다.

평가 경향 반영한 평균 계산 식
→ 의미 : 해당 아이템의 평점이 해당 유저의 평균에서 얼마나 떨어져 있는지를 계산하는 식임
# movielens 데이터 불러오기
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('C:/Users/Yeong/Desktop/u.data', names=r_cols, sep='\t',encoding='latin-1')
ratings = ratings.drop('timestamp', axis=1)
#rating matrix 생성
x = ratings.copy()
y = ratings['user_id']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, stratify=y, random_state=12)
rating_matrix = x_train.pivot(values='rating', index='user_id', columns='movie_id')처음부터 데이터를 다시 불러오고 각 행이 user인 rating matrix 생성
# 유저간 유사도 계산
matrix_dummy = rating_matrix.copy().fillna(0)
user_similarity = cosine_similarity(matrix_dummy, matrix_dummy)
user_similarity = pd.DataFrame(user_similarity, index=rating_matrix.index, columns=rating_matrix.index)
## 다른 부분
# 모든 사용자의 개별 평점 평균 계산
rating_mean = rating_matrix.mean(axis=1)이전과 동일하게 유저 간 유사도 매트릭스를 생성한다. 또한, bias from mean average방식을 사용하기 위해서 각 유저의 평점 평균을 계산한다.
#bias from mean 추천
def ubcf_bias(user_id, movie_id):
import numpy as np
# 현 user의 평균 가져오기(나중에 계산 위해서)
user_mean = rating_mean[user_id]
if movie_id in rating_matrix:
# 해당 user와 다른 user들의 유사도 가져오기
sim_scores = user_similarity[user_id]
# 현재 item의 rating 모두 가져오기
movie_ratings = rating_matrix[movie_id]
# 모든 user의 rating 평균 가져오기
others_mean = rating_mean
# 해당 item에 대한 rating이 없는 user 삭제
none_rating_idx = movie_ratings[movie_ratings.isnull()].index
movie_ratings = movie_ratings.drop(none_rating_idx)
sim_scores = sim_scores.drop(none_rating_idx)
others_mean = others_mean.drop(none_rating_idx)
# 평균으로부터의 편차 예측치 계산
movie_ratings = movie_ratings - others_mean
prediction = np.dot(sim_scores, movie_ratings) / sim_scores.sum()
# 편차 예측치에 해당 user의 평균 더하기
prediction = prediction + user_mean
else:
prediction = user_mean #해당 영화가 없으면 해당 사용자의 평균 평점으로 예측
return prediction
score(ubcf_bias)평균에서의 편차를 가중평균해서 계산하고 이를 최종적으로 반환한다.
user_mean으로 미리 해당 유저의 평균을 계산해둔다. 또한 others_mean에 모든 유저들 각자의 평점을 저장해두고 나머지 과정을 앞선 CF와 동일하게 진행한다. 그리고 prediction에 해당 유저의 예측 편차 값을 저장한다.
최종적으로는 예측한 편차(prediction)에 해당 유저의 평균(user_mean)을 더해서 출력한다.
여기서 else 구문은 예측 값을 도출하려는 영화가 평점 매트릭스에 없는 경우인데, 이때는 해당 유저의 평균 평점을 반환한다.
✔ 이 방식도 마찬가지로 KNN 과 결합해서, 거리가 가까운 유저 일부만을 선택해서 평균에서의 편차를 계산할 수 있음 (평가경향 고려 + KNN)
✅ Normalization 방식
• 위와 같은 방식으로 편차를 고려하는 것과 달리, 각 유저의 평점을 모두 정규화 해서 평점을 계산할 수 있음.
• 각 사용자의 평점을 평균, 표준편차를 사용해서 정규화(normalization)
• 정규화된 값에 동일하게 CF 알고리즘을 적용해서 정규화된 예측치를 계산함 → 다시 de-mornalize 실시해서 최종 예측값 도출
✅ 그 외 CF 성능 향상을 위한 방법들
① Default Rating 채우기
• 실제로 사용자들의 평점 매트릭스는 NaN값이 굉장히 많음. 전체 아이템의 1%도 안되는 경우가 많다.
• 따라서 이를 보완하기 위해서 각 사용자 또는 아이템의 평균 값으로 빈 칸을 채워서 coverage를 늘릴 수 있다.
• 단점 : 기본적으로 CF는 다른 사용자들의 다른 취향을 파악해서 채워넣는 것인데,
99%의 값을 평균으로 채워넣게 되면 99%정도로 유사해지므로 추천 정확도가 굉장히 떨어지게 됨
② Significance Weighting
• 기본적으로 CF는 특정 사용자들이 공통적으로 유사하게 평가한 아이템만을 사용해서 유사도를 계산한다.
ex) 아래 그림에서 U1와 U2의 유사도를 계산할 때, 공통으로 평점이 있는 M1~M3만 사용된다 (W5-CF6)
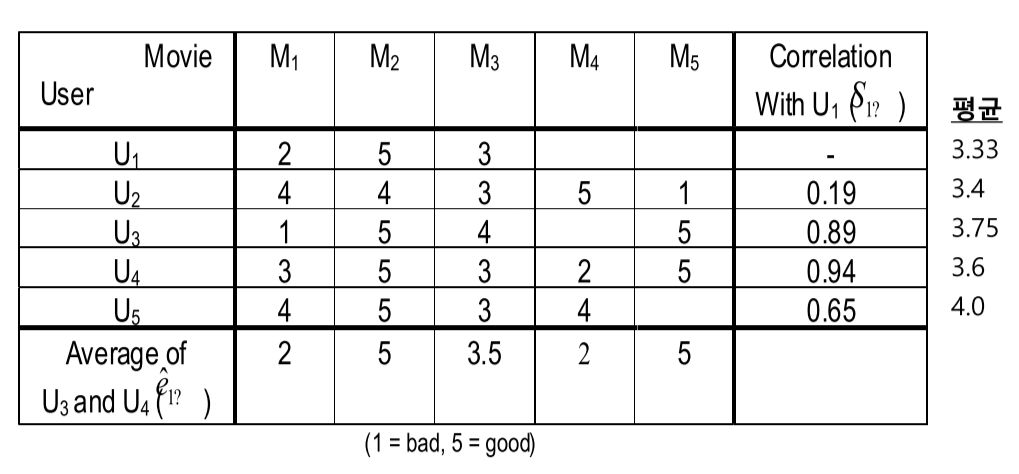
• 즉, 유저 간(또는 아이템 간)의 유사도가 가지는 중요성은 유저마다 다르다.
ex) U1 vs U2의 유사도와 U4 vs U5의 유사도가 동일하게 나타났을 때, 후자가 공통으로 평가한 항목이 더 많기 때문에 중요도가 더 크다
• 따라서 공통적으로 평가한 아이템이 많을 경우 가중치를 부여함. 공통으로 평가한 아이템의 수에 비례에서 가중치를 부여함
• 단점 : 가중치를 직접 부여할 경우 추천하는 항목의 수가 직접적으로 많이 바뀌기 때문에 오히려 정확도가 떨어진다
→ 최근에는 가중치를 계산하는 항목의 수에 대한 mininun level를 설정해서, 특정 수 이상의 항목을 공통으로 보유할 경우에만 가중치 계산함
③ Variance Weighting
• 아이템마다 평점의 분산이 큰 것도 있고 작은것도 있다. 따라서 이를 고려해서 추천에 반영함
④ 시간 고려
• 시점에 따라서 평가 경향이 다를 수 있음. 따라서 현재 시점에서 너무 과거에 평점을 남긴 유저의 데이터는 제거할 필요가 있음
• 어떤 유저는 영화가 나오면 바로 보지만, 다른 유저는 영화가 나오고 나서 한참 뒤에 DVD로 볼 수 도 있음. 이 두 사용자는 영화를 보는 패턴이 완전히 다른 사용자임.
'추천시스템' 카테고리의 다른 글
| 추천 알고리즘 - Matrix Factorization (0) | 2022.01.14 |
|---|---|
| 컨텐츠 기반 추천(Content Based Filtering) (0) | 2022.01.10 |
| 협업필터링 - 아이템 기반(IBCF) (0) | 2021.11.04 |
| 협업필터링 + KNN (0) | 2021.10.11 |
| 협업필터링 기본 (1) | 2021.10.11 |




댓글