◈ Factorization Machine 이란
MF나 SVD++를 일반화한 모델이다. CF 계열 알고리즘의 끝판왕이라고 볼 수 있다.
MF의 경우유저와 아이템 두 가지 입력변수가 rating에 미치는 공통의 K 개의 feature를 P,Q 매트릭스 형태로 추출해서 사용한다. SVD++는 P, Q 매트릭스외에 또다른 K 개의 리처를 추가적으로 뽑아낸다.
만약 n개의 다수의 입력 변수를 사용하는 것을 일반화 한 모델이 Factorization Machine 이다. 즉, n개의 변수가 있을 때, 모든 2개의 변수 짝의 interaction에 대해서 피쳐를 뽑아내서 factorize 하는 방식이다. n=2이라면 구조상 MF와 동일하다.
✅ FM의 장점
• 변수의 독립적인 영향 뿐만 아니라, 변수 간의 상호작용(interaction)을 학습한다.
• sparse data인 경우에도 factorization을 사용해서 학습할 수 있다.
• MF의 경우 사용자와 아이템에 대한 정보만 사용한 것과 달리, 어떤 종류의 변수도 모델에서 추가해서 사용할 수 있다.
• MF는 일반적으로 피쳐의 수가 상당히 커야 성능이 좋지만, FM은 피처의 수가 적은 것이 sparse data를 잘 처리하기 때문에 상대적으로 성능이 더 좋다.
• 최근에는 FFM(Fiel aware Fcatorization Machine)도 개발되어 사용되고 있다. 하나의 피처에 대해서 하나의 latetn vector만 가지는 FM에 비해서 다수의 latent vector를 가질 수 있도록 만든 것이다.
대규도 sparse data에 적합하지만 dense&numeric data에는 잘 맞지 않고 과적합 가능성이 높다
✅ 계산 방식


예측하고자 하는 유저의 rating 값인 y^(X)는 위와 같이 표현할 수 있다. 두 식은 같은 의미를 가지고있다.
xi * xj : 주어진 변수 중에서 가능한 2 쌍의 조합을 곱한다 :
<vi, vj> : 그리고 이 과정에서 해당 변수의 v 매트릭스 행렬의 원소들도 함께 곱한다.
• 파란색 부분 <Bias Score> :
변수 간의 bias를 따로 뽑아낸 부분
• 초록색 부분 <Latent Score> :
하나의 변수에 대해서 다른 모든 변수들과의 짝을 만들어서 내적을 계산하는 것이다. n과 p는 변수의 갯수를 의미한다. n=2 인 경우에는 기본적은 MF와 동일하고, 이론 상으로는 n의 수를 계속해서 증가시킬 수 있다.

Latent score 부분은 식을 유도해서 수정한다. 원래 식에는 변수가 4개가 있어서 복잡도가 O(kp2) 이지만, 식을 수정할 경우 vi,f와 xi 변수만 남아서 O(kp)로 복잡도를 감소시킬 수 있다. xi 변수만 사용해서 계산을 할 수 있다는 것은, 두 가지 변수에 대한 계산을 할 때 하나의 변수의 정보만 알 고 있으면 계산을 수행할 수 있다는 의미이다.

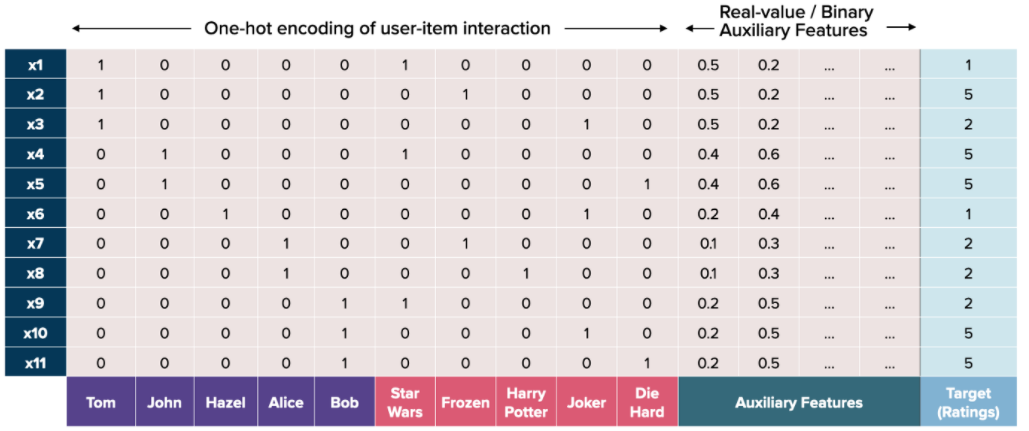
FM은 기본적인 user-item rating 매트릭스를 아래 그림과 같이 모두 원 핫 인코딩을 한 형태로 변경한다.
즉, 첫 번째 행은 Tom이 StarWars영화에 대해서 1점이라고 평을 남긴 데이터 row 이다. 이전 Matrix Factorization 같은 경우에는 보라색과 빨간색 부분으로만 계산을 한다면, FM에서는 초록색으로 표시된 Auxiliary Features를 사용하게 된다. 여기에 여러 가지 특징(시간, 직업 등)들을 넣어서 사용할 수 있다.
여기서 세로 column 하나가 위의 계산 공식에서 xi에 해당한다. 따라서 Tom에 대한 열은 x1에 해당된다.
유저들은 모두 서로 다르기 때문에 보라색 columns 끼리는 interaction 효과가 발생하지 않는다. (Tom 이면서 John 일 수 없기 때문). 또한 아이템(영화) 간에도 interaction이 발생하지 않는다. 하지만, 유저-아이템 간에는 interaction이 발생한다. 이것을 이용해서 계산하는 것이 Matrix Factorization 이다.

그리고 위의 계산식에 대해서 미분을 실시해서 업데이트 룰을 구할 수 있다.

이러한 업데이트 룰을 계산할 수 있다.
W'i 는 bias에 대한 업데이트 룰이고, a 는 학습률 / e 는 에러 / xi 는 변수 값
V'i,f 는 V 매트릭스에 대한 업데이트 룰이다. vi,f 는 vi i번째 변수의 k(=f) 개의 값을 의미한다.

w 매트릭스 :
각 변수마다 존재하기 때문에, w 매트릭스의 원소는 변수 갯수인 n개와 동일하다
v 매트릭스 :
피쳐 매트릭스를 나타낸다. xn 변수에 대해서 모두 k 개의 원소를 가짐
✅ Sparase Matrix 처리
하지만 위와 같이 계산할 경우 sparse matrix이기 때문에, x 의 값이 0인 경우에는 모든 식이 0으로 계산된다. 따라서 불필요한 연산을 많이 수행하게 된다.
따라서 FM 에서는 x 변수의 값이 있는 부분만 선택해서 인덱스와 값으로 별도의 리스트로 저장하고 계산하는 방식을 사용한다. 따라서 위의 좌측 그림에서는 user / item/ other 에서 각각 하나씩 총 3개의 요소에 대한 인덱스가 추출된다.
→ 인덱스 리스트 : (1,6,8)
→ value 리스트 : (1,1,40)
그리고 우측 아래 그림에서 x1 의 row에 1의 값이 곱해지고
x6의 row에 1의 값이 곱해지고
x9의 row에 1600 이 곱해진다. (40^2)
그리고 이 값을 axis=0 으로 수직으로 모두 더해서 K개의 원소를 남긴다. <코드 보면서 설명 이해>
◈ 실습 : 유저와 아이템만 사용하는 경우
import numpy as np
import pandas as pd
from sklearn.utils import shuffle
# 무비렌즈 데이터 불러오기
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('C:/Users/u.data', sep='\t', names=r_cols, encoding='latin-1')모델 구축에 사용할 무비렌즈 데이터를 불러온다.
# User encoding : 유저 수만큼의 딕셔너리 생성
user_dict = {}
for i in set(ratings['user_id']):
user_dict[i] = len(user_dict)
n_user = len(user_dict)
# Item encoding : 아이템 수 만큼 딕셔너리 생성
item_dict = {}
start_point = n_user
for i in set(ratings['movie_id']):
item_dict[i] = start_point + len(item_dict)
n_item = len(item_dict)
start_point += n_item
num_x = start_point # Total number of x : 943(사용자) + 1682(아이템)
ratings = shuffle(ratings, random_state=1)FM 연산을 수행하기 위해서 원핫 인코딩 행렬 형태로 변경한다.
이 과정에서 유저와 아이템 수 만큼 각각의 딕셔너리를 생성한다.

단, 그림에서 보면 빨간 부분부터 아이템 열이 시작하므로, 아이템 딕셔너리의 인덱스는 유저 수 +1 부터 시작해야 한다.
num_x 에는 총 변수의 갯수가 저장되어 있는데, 여기서는 943(유저 수) + 1682(아이템 수) 이다.
# 원 핫 인코딩한 형태의 데이터 생성
#(인덱스), (value) 를 별도로 저장하는 리스트
data = []
y = [] #평점 저장하는 리스트
w0 = np.mean(ratings['rating'])
for i in range(len(ratings)):
case = ratings.iloc[i] #4개의 열 가짐
x_index = [] #변수 인덱스 초기화
x_value = [] #변수 value 초기화
# User id encoding : 첫번째는 507
x_index.append(user_dict[case['user_id']])
x_value.append(1)
# Movie id encoding : 943(유저 수)+185(movie id) 형태로 반환 = 1127
x_index.append(item_dict[case['movie_id']])
x_value.append(1)
data.append([x_index, x_value])
y.append(case['rating'] - w0)
#중간에 결과 프린트
if (i % 10000) == 0:
print('Encoding ', i, ' cases...')
하지만 실제 원 핫 인코딩을 실시하면 비어있는 값이 굉장히 많은 Sparse matrix 형태가 된다. 이론적으로는 위의 화살표가 있는 그림처럼 처리를 하면 되지만 많은 연산이 필요하다.
따라서 이를 효율적인 형태로 변형해서 사용하기 위해서 값이 있는 부분의 정보만 추출해서 사용한다. 위의 그림의 경우 값이 1인 요소의 인덱스와 값만 나타내면 (0,1,1)로 나타낼 수 있다. 따라서 이러한 방식으로 원핫 인코딩을 한 행렬 에서도 적용한다. 인덱스 부분을 나타내는 것과 (1,10), value 부분(1,1)을 나눠서 표현하면 데이터를 효율적으로 사용할 수 있다.
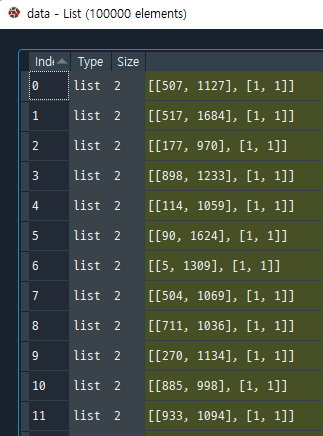
인덱스와 값으로 짝지어진 두 개의 리스트는 data에 위와 같은 형태로 저장된다. 반복문을 돌리면 해당 리스트가 100000개 생성된다.


v 는 x*k 형태의 피쳐 매트릭스이다. 여기서는 2625(x) x 300(k) 형태.

x_1는 계산을 위해서 2차원 형태로 변경한다.

vx = self.v[x_idx] * (x_1) 부분이
위의 노란색 부분에 해당됨

sum_vx_2 = np.sum(vx * vx, axis=0)
노란색 부분에 해당
◈ Reference
'추천시스템' 카테고리의 다른 글
| 하이브리드 추천시스템 (0) | 2022.01.24 |
|---|---|
| Matrix Factorization : 텐서플로우, 케라스로 구현 (0) | 2022.01.23 |
| 추천시스템에서 Binary Data의 사용 (0) | 2022.01.22 |
| Surprise 라이브러리 (0) | 2022.01.21 |
| 추천 알고리즘 - Matrix Factorization (0) | 2022.01.14 |



댓글