◈ 개념 및 용어 정리
• Market basket analysis (Agrawal et al., 1993) 논문에서 처음 제시됨.
• 비지도 학습의 일종으로, 고객들이 특정 품목을 구매할 때 어떤 다른 항목들을 같이 구매(co-occurence)하는지 분석하기 위해서 사용
•affinity analysis 또는 market basket analysis 라고도 불리며, cross-selling 목적으로 사용됨
•Apriori algorithm이 주로 사용되고, 계산량을 줄이기 위해서 support 개념을 이용해서 자주 등장하는 itemset 을 선정함
• 해당 규칙의 성과를 평가하기 위해서 confidence 와 lift 사용
✔ 예시 : 고객들의 faceplate 구매 내역

✔ 예시 : 특정 유저가 읽은 뉴스 카테고리

✅ Itemset
• 각 거래내역에서 가능한 아이템들의 조합을 의미하며, 아이템 1개의 경우도 itemset으로 간주할 수 있음.
•순서는 중요하지 않음

✅ Rules
• Antecendet : if 파트에 해당하며, 한 개 이상의 아이템
• Consequent : then 파트에 해당하며, 하나의 아이템
• 각 거래마다 여러 개의 itemset 조합이 발생하고, 그에 따라서 rule도 여러개 생성 가능. 위의 예제의 경우
{red 구매} → {white 구매}
{red, white 구매} → {green 구매}
{white, green 구매} → {red 구매}
• 이 과정을 모든 거래 내역에 대해서 계산하게 되면, 자주 중복해서 등장하는 if-then 규칙을 뽑아낼 수 있음.
즉, 각 거래내역에서 중복해서 나타나는 규칙에서 패턴을 발견할 수 있음
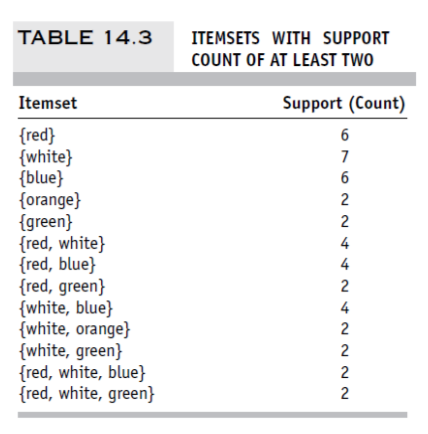
✅ Support
• Item set에 대한 measure
• 하지만 실제 데이터에서 거래내역이 많아지면, itemset과 rule 계산이 복잡해지고 시간이 많이 소요됨.
→ 따라서 거래 내역에서 자주 등장하는 itemset만 선정해서 분석해야 함
•자주 등장하는 itemset을 선정하는 기준이 Support
: number or percent of transaction in which the antecedent and the consequent appear in the data

✅ Apriori Algorithm
• 컴퓨팅 파워의 한계를 고려하여, 모든 규칙을 다 계산하는 것이 아니라 자주 등장하는 아이템셋과 규칙을 선별하는 방법
• frequent itemset을 뽑아내는 방법 : if an itemset is infrequent, then all its supersets will be infrequent.
• support 기준을 우선 선정함. itemset 조합 수를 작은 것부터 늘려가면서, 작은 수에서 support를 받지 못한 item은 다음 단계에서 제외함
< Support를 이용하여 Frequent Itemset 을 선정하는 방법 >
① 최소 Support 값을 선정함
② support 기준을 만족하는 one-itemset 리스트를 생성함
③ 이전 단계의 one-itemset을 사용하여, support 기준을 충족하는 two-itemset 리스트를 생성함
④ 이전 단계의 two-itemset을 사용하여, support 기준을 충족하는 trhee-itemset 리스트를 생성함
⑤ 이 단계를 총 상품의 갯수만큼 반복
• 아래 예시에서, yellow는 1-itemset에서 support >=2를 충족하지 못하기 때문에 첫 단계에서 제외됨
따라서 yellow가 들어가는 조합은 2-itemset개 조합에서도 제외됨

✅ Confidence
• Rule의 성과를 측정하는 방법. Rule에 대한 measure 로 조건부 확률과 유사함
분모를 antecedent itemset의 갯수로, 분자를 antecednet & consequent itemset의 갯수로 계산
• Likelihood of the occurrence of consequence out of all the transactions that contain the antecedent of the rule

• Example 1에서 confidence=0.4 이므로, orange, cold medicine을 구매하면 40%는 soup를 구매한다.
반면, Example 2에서는 conficence=0.2 이므로 rule의 성과가 떨어진다고 할 수 있음.

• 위의 뉴스 예시에서 {News, Finance} → {Sprots} 라는 규칙에 대해서 confidence 계산해보면
= {News, Finance, Sprots} 등장 확률 / {News, Finance} 등장 확률
= (2/6) / (4/6) = 0/5
로 계산되고, news / finance 카테고리의 뉴스를 읽은 유저의 50%가 sport 카테고리를 읽는다고 해석할 수 있음
✅ Lift
• 특정 규칙이 있을 때, 해당 규칙이 사전 정보가 없는 벤치마크와 비교해서 얼마나 높은지를 비교하는 방법. 즉 두 사건의 독립성(Independence)을 확인하는 것
• 예시 :
{A} → {B} 라는 규칙의 평가할 때,
{A} 가 등장하고 {B}가 등장하는 것과
{A}와 상관없이 {B}가 등장하는 것(서로 독립인 경우, benchmark)를 비교함.
• 해석 : Lift > 1 이면 해당 규칙이 consequent item을 찾아내는 데에 유의미하다고 할 수 있음.
Lift=1.3인 경우 {B} 여부를 판단할 때, {A}가 선행된다면, 관련 정보가 없는 것(benchmark)보다 30% 가능성이 높다는 것을 의미함
• 계산 방식 :


• 예시


✅ Conviction

• 값이 클수록 좋은 것. 32%인 경우 해당 규칙을 통해서 예측 확률이 32% 올라간다고 해석할 수 있음
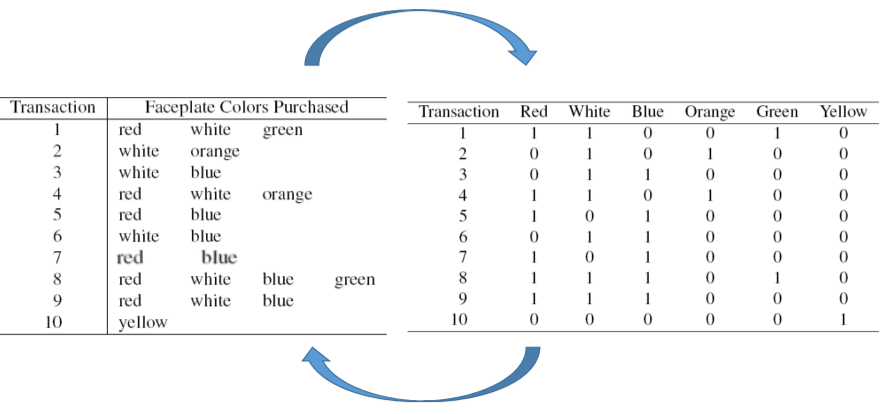
✅ 데이터 포맷
• Transaction data format(좌) vs binary incidence matrix format(우)
• 오른쪽 포맷에서는 데이터가 몇 번 등장했는지는 중요하지 않음. 등장 여부만 파악함 (1,0)
◈ 추가로 고민해야 할 부분
• 장바구니 분석을 비판하는 주장
: 현재의 추천시스템은 추천의 가치를 고려하지 않고 있다

• { 커피 } -> { 도넛 } 의 confidence 가 1일 때, 커피를 마시는 사람에게 도넛을 추천할 필요가 있는가?
굳이 추천하지 않아도 어차피 도넛을 사먹는데 추천이 필요한가?
• 따라서 도넛이 아니라 샌드위치 등 다른 항목을 추천하는 경우와 비교를 해야 한다.
◈ 실습
• Phone Faceplates 데이터 예제
#load data
fp.df <- read.csv("Faceplate.csv")
# remove first column and convert to matrix
# as.matrix () does and will maintain the shape of the input
fp.mat <- as.matrix(fp.df[,-1])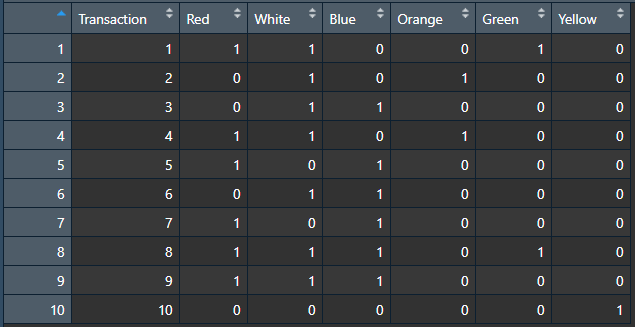
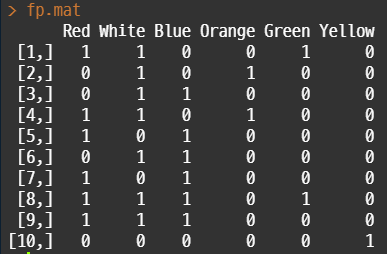
• fp.df 의 데이터를 (좌) 첫 번째 열을 삭제하고 matrix 형태로 변환함
library(arules)
# binary incidence 포맷 -> transaction 포맷으로 변경
fp.trans <- as(fp.mat, "transactions")
fp.trans
inspect(fp.trans)
#1-tiem의 빈도 파악
itemFrequencyPlot(fp.trans)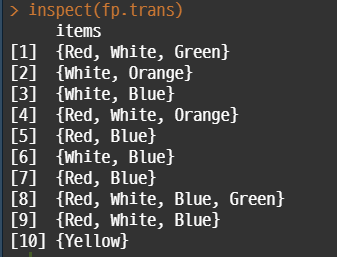

• Association Rules는 arules 패키지를 사용함
• 처음에 로딩한 binary incidence 포맷을, 분석에 사용하기 위한 transaction 포맷으로 변경.
inspect 함수를 이용해서 왼쪽과 같이 출력 가능
# Apriori 알고리즘 적용
rules <- apriori(fp.trans, parameter = list(supp = 0.2,
conf = 0.5,
target = "rules",
minlen=2))
#규칙 확인하기
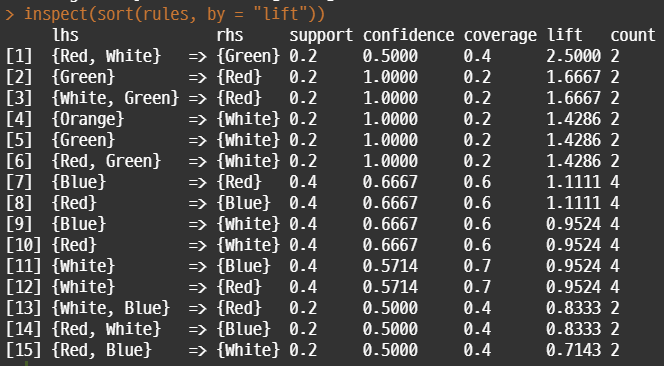
inspect(rules)
inspect(sort(rules, by = "lift"))

• Apriori 알고리즘을 적용한다. 이 때 파라미터로 support, confidence 최소값을 지정해야 한다.
• minlen 파라미터는 itemset의 최소 아이템 갯수를 지정함. 이 파라미터를 지정하지 않으면 { } => {beer} 이런 규칙들도 결과에 포함됨
• 해석 :
- red, white를 살 확률이 0.2 이고, 그 사람이 green을 구매할 확률은 0.5이다.
- green 을 구매할 확률은 0,2 이고, 그 사람이 red를 구매할 확률은 1이다.
◈ 실습 2
• 아래 뉴스 예시와 같은 형태로, R에서 매트릭스 타입의 데이터를 생성
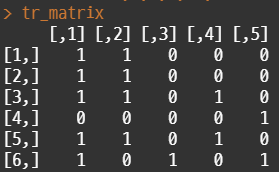
# transaction 형태로 변경
trans = as(tr_matrix, "transactions")
# 데이터 살펴보기
trans
LIST(trans)
summary(trans)
itemFrequencyPlot(trans)
• 위의 예제의 형태로 임의의 데이터를 생성하고 tr_matrix 형태로 저장한다. 연관 분석을 위해서는 주어진 데이터를 transaction 포맷으로 변환해야 한다. LIST / summary / itemFrequencyPlot 함수를 이용해서 해당 데이터를 간단하게 살펴볼 수 있다.
# apriori 알고리즘 적용. support 0.1 이상 & confidence 0.8 이상
rules=apriori(trans, parameter=list(supp=0.1, conf=0.8, target="rules"))
summary(rules)
inspect(sort(rules, by = "lift"))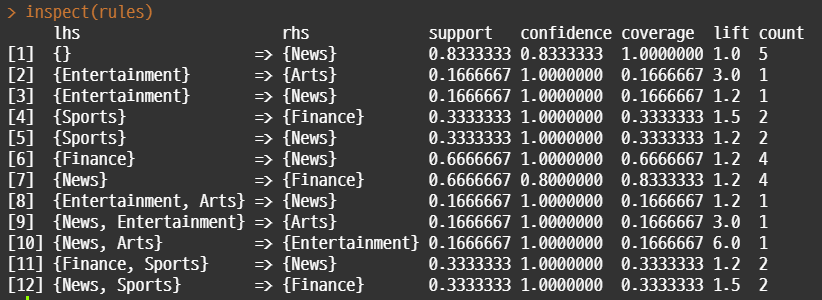
•apriori 알고리즘을 적용한다. 이 과정에서 support와 confidence 를 설정한다. inspect() 함수를 이용해서 규칙을 살펴볼 수 있음
#redundent 규칙 제거
rules.sorted=sort(rules, by="lift")
rules.sorted
subset.matrix=is.subset(rules.sorted, rules.sorted)
subset.matrix
subset.matrix[lower.tri(subset.matrix, diag=T)]=FALSE
subset.matrix
redundant=colSums(subset.matrix, na.rm=T)>=1
redundant
# remove redundant rules
rules.pruned=rules.sorted[!redundant]
rules.pruned
inspect(rules.pruned)• 규칙들을 살펴보면 중복되는 규칙이 있다는 것을 확인할 수 있음. 예를 들어, {A,B} -> {C} 와 {A} -> {C} 규칙이 있는 경우, 전자는 후자에 포함되기 때문에 별도로 규칙을 분리해둘 필요가 없음. 이 경우에는 예시가 간단해서 규칙이 많지 않지만 실제로 데이터가 굉장히 많은 경우에는 컴퓨팅 파워 절약을 위해서 필수적이다.
library(arulesViz)
#scalteer plot
plot(rules.pruned, shading="order", control=list(jitter=0.3))
#balloon plot
plot(rules.pruned, method="grouped")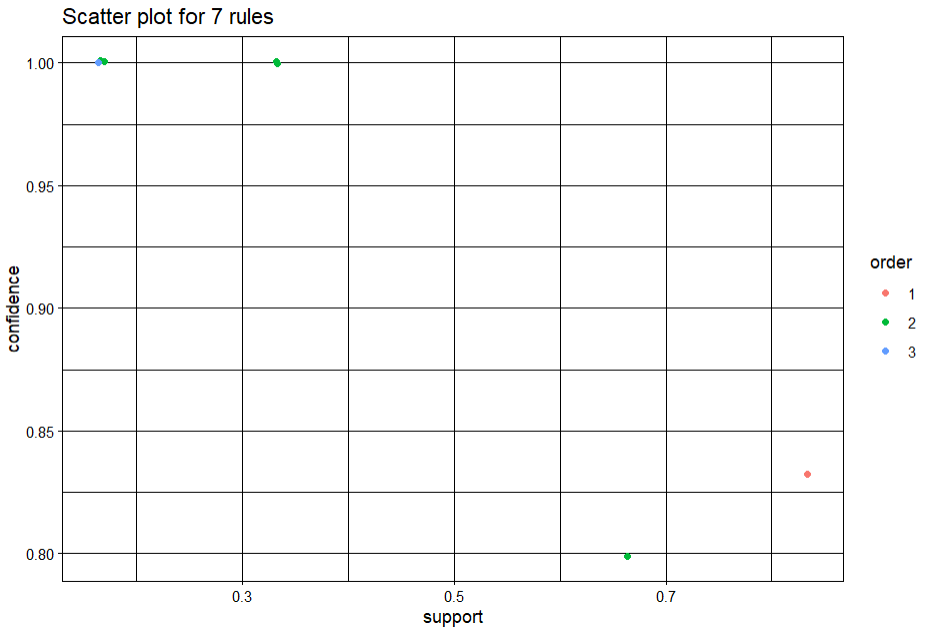
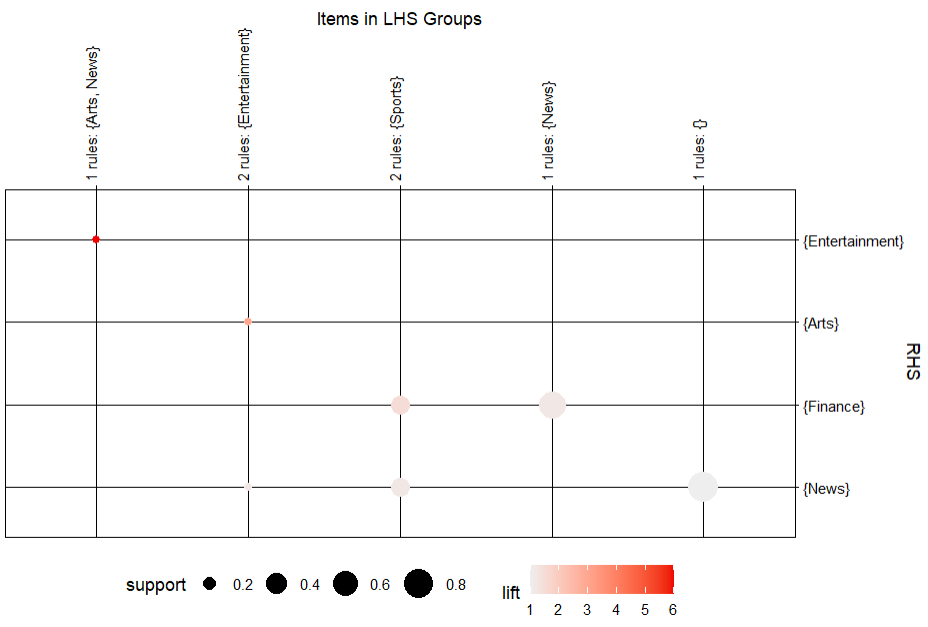
• arulesViz 라이브러리를 이용하여 시각화를 실시할 수 있다. 위는 scatterplot이고 아래는 balloon plot.
◈ 참고자료 출처
• Data Mining for Business Analytics: Concepts, Techniques, and Application in R" by R, Galit Shmueli, Peter C. Bruce, Inbal Yahav, Nitin R. Patel, Kenneth C. Lichtendahl Jr. Wiley. 1st edition. Wiley, 2017.
'데이터 분석 > 통계, 분석기법' 카테고리의 다른 글
| 다변량 확률 분포, Maximum Likelihood Estimator (0) | 2022.04.10 |
|---|---|
| 확률 기본 개념 (0) | 2022.03.28 |
| 생존분석(Survival Analysis) : Kaplan-Meier / Cox Proportional Hazard / BYTD (0) | 2021.11.15 |
| VAR (Vector Auto Regressive) 모형 (0) | 2021.11.01 |
| Markov Chain Monte Carlo 개념 (0) | 2021.10.10 |

댓글