📚 미니배치와 DataLoader 사용하기
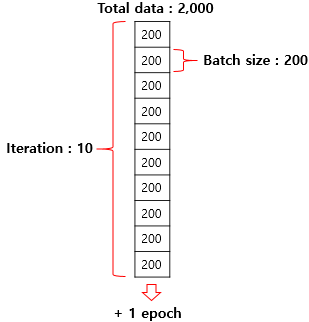
파이토치에서는 DataLoader를 사용해서 미니 배치 형태로 쉽게 처리할 수 있다.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import TensorDataset # 텐서데이터셋
from torch.utils.data import DataLoader # 데이터로더
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])임의이 예제 데이터를 사용한다.
#tensor data 형태로 변경
dataset = TensorDataset(x_train, y_train)
#데이터 로더
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
#모델 정의
model = nn.Linear(3,1)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5)예제 데이터를 tensor data 형태로 변경한다.
그리고 파이토치의 데이터로더 기능을 사용한다. DataLoader(데이터셋, 미니배치 크기, shuffle) 파라미터를 입력해서 사용한다. shuffle을 설정할 경우 각 에폭마다 데이터가 학습되는 순서가 변경된다.
nb_epochs = 20
for epoch in range(nb_epochs + 1):
for batch_idx, samples in enumerate(dataloader):
print(batch_idx)
print(samples)
x_train, y_train = samples
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train)
# cost로 H(x) 계산
optimizer.zero_grad()
cost.backward()
optimizer.step()
print('Epoch {:4d}/{} Batch {}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, batch_idx+1, len(dataloader),
cost.item()
))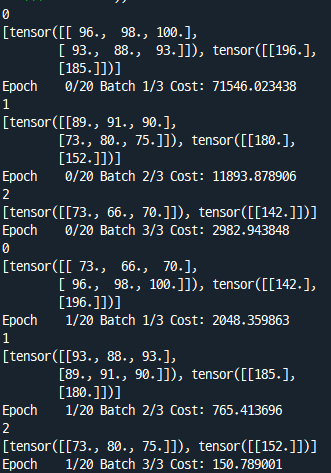
각 에폭마다 batch_idx와 samples가 출력되게 해서 반복해보면, batch 인덱스 0,1,2 가 1회 반복되고 나서 다음 에폭으로 넘어가는 것을 확인할 수 있다.
📚 커스텀 데이터셋
torch.utils.data.Dataset과 torch.utils.data.DataLoadr 를 사용하면 미니배치 학습, 데이터 셔플, 병렬 처리 등을 보다 간단하게 수행할 수 있다.
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class CustomDataset(Dataset): #Dataset 상속
def __init__(self):
self.x_data = [[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]]
self.y_data = [[152], [185], [180], [196], [142]]
#데이터 총 개수 리턴
def __len__(self):
return len(self.x_data)
#인덱스에 해당되는 데이터를 tensor형태로 리턴
def __getitem__(self, idx):
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x,y
dataset = CustomDataset()
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
model = torch.nn.Linear(3,1)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5)위와 같이 커스텀 데이터셋 클래스를 생성할 수 있다.
이후 학습 과정은 동일.
📚 Reference
PyTorch로 시작하는 딥러닝 입문, 유원준 외, 2022, https://wikidocs.net/book/2788
'머신러닝, 딥러닝 > 파이토치' 카테고리의 다른 글
| [파이토치 스터디] 경사하강법 구현, Class 사용하기 (0) | 2022.03.01 |
|---|---|
| [파이토치 스터디] 파이토치 기초 (0) | 2022.03.01 |
| [파이토치 스터디] 준지도 학습 (Semi-Supervised Learning) (0) | 2022.02.24 |
| [파이토치 스터디] 전이학습, 모델 프리징 (0) | 2022.02.23 |
| [파이토치 스터디] 클래스 불균형 다루기 (가중 무작위 샘플링, 가중 손실 함수) (0) | 2022.02.23 |




댓글