📚전이 학습 (Transfer Learning)
✅ 전이학습 이란?
기존의 모델을 불러와서 풀고자 하는 새로운 문제에 적용하는 방식을 의미한다. 파이토치에서는 torchvision.models as models를 이용해서 ImageNet 대회에서 사용된 사전학습 모델을 쉽게 사용할 수 있다.
📌라이브러리 및 데이터 불러오기
import torch import torchvision import torchvision.transforms as transforms from torch.utils.data import DataLoader import torch.nn as nn import torch.optim as optim #GPU 사용여부 확인 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print(device)
📌데이터 불러오기 및 전처리
# 데이터 불러오기 및 전처리 작업 transform = transforms.Compose( [transforms.RandomCrop(32, padding=4), transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True,download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=16,shuffle=False)
CIFAR 10 데이터를 불러오고 이미지를 랜덤으로 크롭한다. 그리고 각 채널에 대해서 평균 0.5, 표준편차 0,5로 정규화를 실시한다. RandomCrop(32)는 이미지를 32픽셀로 아무렇게나 잘라서 출력한다.
📌모델 불러오기 및 수정
#ResNet 모델 불러오기 model = torchvision.models.resnet18(pretrained=True) #출력층 확인: fully connected layer model.fc

#모델 구조 수정 model.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1) num_ftrs = model.fc.in_features model.fc = nn.Linear(num_ftrs, 10) model = model.to(device)
pretrained=True를 하면 ResNet18 구조와 사전 학습 된 파라메타를 모두 불러온다. pretrained=False를 하면 ResNet18 구조만 불러온다. 모델과 텐서에 .to(device)를 붙여야만 GPU 연산이 가능하니 꼭 기입한다.
또한 원래 ResNet 모델은 이미지넷 데이터를 이용해서 학습한 모델이다. 이미지넷 데이터는 클래스가 1000개 이기 때문에 출력 노드가 1000개이다. 따라서 CIFAR10 데이터의 클래스 수인 10에 맞게 출력 노드를 10개로 수정해야 한다.
📌모델 학습
criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-2)
for epoch in range(30): running_loss = 0.0 for data in trainloader: inputs, labels = data[0].to(device), data[1].to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() cost = running_loss / len(trainloader) print('[%d] loss: %.3f' %(epoch + 1, cost)) torch.save(model.state_dict(), './models/cifar10_resnet18.pth') print('Finished Training')
손실함수의 옵티마이저를 설정하고 모델 학습을 진행한다. 전이학습을 위해서 모든 에폭을 다 시행하고 학습이 끝나면 라인19와 같이 모델을 저장해야 한다.
📌저장한 모델 불러오기
#저장한 모델 불러오기 model = torchvision.models.resnet18(pretrained=False) model.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1) num_ftrs = model.fc.in_features model.fc = nn.Linear(num_ftrs, 10) model = model.to(device) model.load_state_dict(torch.load('./models/cifar10_resnet18.pth'))
학습과정에서 저장한 모델을 불러온다. 전이학습 과정에서는 새로운 데이터와 태스크 목표에 맞춰서 파라미터가 업데이트된다.
📌예측하기
correct = 0 total = 0 with torch.no_grad(): model.eval() for data in testloader: images, labels = data[0].to(device), data[1].to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
📚 Model Freezing
✅ 모델 프리징 이란
기존 모델의 변수를 그대로 사용하기 위해서 업데이트가 이루어지지 않도록 지정하는 방법. 사전 학습 모델의 변수를 그대로 유지할 수 있어서 학습 속도와 정확도를 향상시키거나 다른 모델과 붙여서 다른 구조를 만들 수도 있다. 예를 들어 이미지 인식 모델에서 이미지 피쳐 추출은 기존 모델을 사용하고 분류 부분은 다른 방식으로 대체할 수 있다.
데이터를 불러오고 전처리 하는 과정은 위와 동일하다.
📌모델 불러오기
model = torchvision.models.alexnet(pretrained=True)AlexNet 모델을 불러온다. pretrained=True를 하면 AlexNet 구조와 사전 학습 된 파라메타를 모두 불러오고 pretrained=False를 하면 AlexNet 구조만 불러온다.
model.classifier #분류기 부분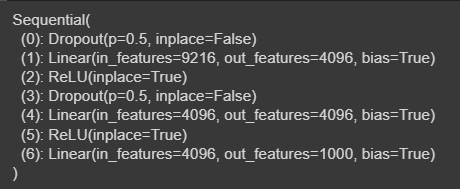
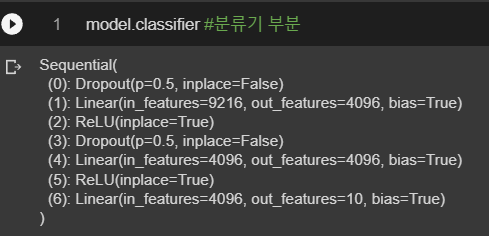
AlexNet에서 분류기 부분만 확인할 수 있다. 이 모델도 이미지넷 데이터를 학습하였기 때문에 출력 노드의 수가 1000개 이다. 따라서 CIFAR10 이미지에 맞게끔 출력 노드를 10개로 수정해야 한다.
#model.features[0] = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1) num_ftrs = model.classifier[6].in_features # fc의 입력 노드 수를 산출한다. model.classifier[6] = nn.Linear(num_ftrs, 10) # fc를 nn.Linear(num_ftrs, 10)로 대체한다. model = model.to(device)
📌모델 파라미터 확인
# 가중치와 편향 목록 출력 for i, (name, param) in enumerate(model.named_parameters()): print(i,name)

모델에 포함된 가중치와 편향을 포함한 파라미터를 순서대로 출력한다.
📌모델 프리징 실시
# 합성곱 층은 0~9까지이다. 따라서 9번째 변수까지 역추적을 비활성화 한 후 for문을 종료한다. for i, (name, param) in enumerate(model.named_parameters()): param.requires_grad = False if i == 9: print('end') break
위의 모델 파라미터를 확인해보면, 합성곱 층이 0~9 까지이기 때문에 9번째 변수까지 requires_grad를 비활성화 하고 for 문을 종료한다.
📌requires_grad 비활성화 확인
# requires_grad 확인 f_list = [0, 3, 6, 8, 10] #피쳐맵 파라미터 c_list = [1, 4, 6] #분류기 파라미터 for i in f_list: print(model.features[i].weight.requires_grad) print(model.features[i].bias.requires_grad) for j in c_list: print(model.classifier[j].weight.requires_grad) print(model.classifier[j].bias.requires_grad)
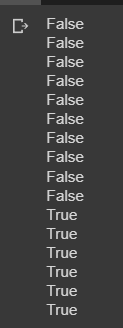

파라미터 업데이트를 프리징하고 결과를 확인해보면, 피쳐 추출에 해당하는 부분은 requires_grad가 비활성화 된 것을 확인할 수 있다.
📚 Reference
딥러닝을 위한 파이토치 입문, 딥러닝호형 저, 영진닷컴
'머신러닝, 딥러닝 > 파이토치' 카테고리의 다른 글
| [파이토치 스터디] 파이토치 기초 (0) | 2022.03.01 |
|---|---|
| [파이토치 스터디] 준지도 학습 (Semi-Supervised Learning) (0) | 2022.02.24 |
| [파이토치 스터디] 클래스 불균형 다루기 (가중 무작위 샘플링, 가중 손실 함수) (0) | 2022.02.23 |
| [파이토치 스터디] 과적합 방지를 통한 모델 성능 개선 (0) | 2022.02.23 |
| [파이토치 스터디] 오토인코더 (1) | 2022.02.16 |




댓글