📚 Overfitting 방지를 통한 모델 성능 개선
✔ 분류/예측 모델의 과적합을 최소화하고 성능을 향상하는 방법에는 여러 가지가 존재한다. 대표적인 성능 개선 방법들은 다음과 같다.
① 데이터 증식 (data augmentation)
학습에 필요한 추가 데이터 수집이 어려운 경우, 기존 데이터를 증식할 수 있다. 구체적인 방법으로는 통계적 기법, 단순 변형, 생성 모델 사용 등이 있다. torchvision.transforms를 사용하면
② 조기 종료 (Early Stopping)
학습 데이터셋에 과적합이 되지 않도록 일정한 기준을 정하여 모델 학습을 종료하는 방식
③ L2 정규화

optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-3)그림과 같이 원형의 경계를 만들어서 학습 데이터셋의 최적 지점인 w* 에 도달하지 못하게 하고 경계 내부의 v*까지만 도달할 수 있도록 하는 방식. Adam Optimizer를 사용할 경우 weight decay 파라미터를 추가할 수 있다. 값이 클수록 페널티 제약조건이 강한 것을 의미한다.
④ Drop Out

class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.feature_extraction = nn.Sequential(nn.Conv2d(3, 6, 5),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2, 2))
self.classifier = nn.Sequential(nn.Linear(512, 120),
nn.ReLU(),
nn.Dropout(0.5), # 비활성화 시킬 노드의 비율
nn.Linear(120, 64),
nn.ReLU(),
nn.Linear(64, 10))신경망 학습 시에 일정 비율의 노드를 random하게 제외하고 학습하는 방식. 한 번 파라미터가 업데이트될 때마다 제외된 노드와 관련 있는 변수는 업데이트가 되지 않기 때문에, 학습 데이터에 대한 과적합을 억제할 수 있다.
출력층에서는 예측 값을 산출해야 하기 때문에 드롭아웃을 사용해서는 안되고, 은닉층에 대해서만 사용해야 한다. 또한, 모델 평가 단계에서는 드롭아웃을 실시하지 않은 모델로 평가해야 하며, 파이토치에서는 .eval() 를 통해서 원래 전체 모델을 사용할 수 있다.
위 코드에서 nn.Dropout(0.5) 은 해당 레이어에서 50%를 선택해서 drop out 하겠다는 의미이다.
⑤ 배치 정규화 (Batch Normalization)
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
self.conv_block = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(self.out_channels),
nn.ReLU(),
nn.Conv2d(self.out_channels, self.out_channels, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(self.out_channels))
if self.stride != 1 or self.in_channels != self.out_channels:
self.downsample = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.out_channels))미니 배치 방식은 학습할 때마다 미니 배치를 돌아가면서 사용한다. 이는 학습 단계마다 입력값의 분포가 다르고 각 레이어에 입력되는 입력값의 분포가 다르다는 것을 의미한다. 일반 신경망에서 각 노드들은 이전 층에서 넘어온 값들에 대해서 일차 연산을 거쳐서 activation function로 전달한다. 여기서 activation function으로 입력하기 전에 각 피쳐 값을 정규화해서 균등한 분포로 만드는 방식이 배치 정규화이다.
일반적으로 각 배치는 전체 데이터와 분포가 다른데, 이를 통해서 과적합을 방지할 수 있고 더 빠르게 수렴할 수 있다. 위 코드의 라인11, 14처럼 nn.BatchNorm2d 를 통해서 배치 정규화를 실시할 수 있다.
⑥ 교란 라벨 (Disturb Label) / 교란 값(Disturb Value)
classification 문제에서 일정 비율의 라벨을 의도적으로 잘못된 라벨로 만들어서 학습을 방해하는 방식. 단순한 방식이지만 과적합을 효과적으로 막을 수 있다. regression 문제의 경우 일정 비율만큼 라벨에 노이즈를 주입해서 과적합을 방지할 수 있다.
⑦ 라벨 스무딩 (Label Smoothing)
일반적인 classification 문제에서는 소프트맥스나 시그모이드 함수를 통해서 0 또는 1의 값을 예측한다. cross entropy loss를 계산할 때, 실제값을 0 or 1 이 아니라 0.2 or 0.8로 구성해서 과적합을 방지하는 방식이 라벨 스무딩이다. 라벨 1을 예측할 때, 확률 값이 0.7로 나타나면 원래는 1로 나오도록 학습이 진행된다. 이때 기준을 0.8로 낮추면 보다 적게 실제값과 가까워지는 방향으로 학습하고, 이를 통해서 과적합을 완화할 수 있다.
📚 1. 조기종료 (Early Stopping) 사용하기

• 모델의 과적합을 막는 방법 중 하나는 조기종료 (early stopping)이다. 위와 같이 학습이 진행될 때, train set에 과적합을 막으려면 중간에 적절한 지점에서 학습을 멈추는 것이 중요하다.
📌 라이브러리, 데이터 불러오기
import torch
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
# CPU/GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f'{device} is available.')
#정규화 방식 정의
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))] #.Normalize([meanR, meanG, meanB], [stdR, stdG, stdB])
)
# 학습용 데이터 불러오기
dataset = torchvision.datasets.CIFAR10(root = './data', train=True, download=True, transform = transform) #dataset = 5만개
trainset, valset = torch.utils.data.random_split(dataset, [30000,20000])
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)
valloader = torch.utils.data.DataLoader(valset, batch_size=32, shuffle=False)
#테스트용 데이터 불러오기
testset = torchvision.datasets.CIFAR10(root ='./data', train=False, download=True, transform = transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=32, shuffle=False)필요한 라이브러리를 불러오고 GPU 사용 여부를 확인한다. 데이터를 불러올 때는 정규화를 실시하고 여기서는 CIFAR10 이미지를 사용한다.

CIFAR 10 이미지는 위와 같이 10개의 클래스로 구성되어 있고 torchvision에서 제공하는 데이터셋에는 train/test를 포함해서 총 6만 장의 이미지가 포함되어 있다.
print(len(trainloader.dataset))
print(len(valloader.dataset))데이터를 불러온 후 train / validation / test 로 분리한다. 여기서는 train : 30000 / validation : 20000 개로 설정한다. test set은 자동으로 1만 개가 불러와진다.
📌 Validation Set에서 손실함수 계산
def validation_loss(dataloader):
n = len(dataloader)
running_loss = 0
with torch.no_grad(): #평가만 하기 때문에 requires_grad 비활성화
resnet.eval() #정규화 기법들이 작동하지 않도록 eval 모드로 설정
for data in dataloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = resnet(images)
loss= criterion(outputs, labels)
running_loss += loss.item()
resnet.train() #모델을 다시 train 모드로 변경
return running_loss/n라인 5,6: 평가만 하기 때문에 requires_grad를 해제하고, 정규화 기법들이 작동하지 않도록 eval 모드로 설정한다.
라인 13 에서 다시 모델을 train 모드로 변경한다.
📌 ResNet 모델 정의
클래스를 이용해서 ResNet 모델을 정의한다.
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
self.conv_block = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(self.out_channels),
nn.ReLU(),
nn.Conv2d(self.out_channels, self.out_channels, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(self.out_channels))
if self.stride != 1 or self.in_channels != self.out_channels:
self.downsample = nn.Sequential(
nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.out_channels))
def forward(self, x):
out = self.conv_block(x)
if self.stride != 1 or self.in_channels != self.out_channels:
x = self.downsample(x)
out = F.relu(x + out)
return outclass ResNet(nn.Module):
def __init__(self, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 64
self.base = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3,stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU())
self.layer1 = self._make_layer(64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(512, num_blocks[3], stride=2)
self.gap = nn.AvgPool2d(4) # 4: 필터 사이즈
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, out_channels, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
block = ResidualBlock(self.in_channels, out_channels, stride)
layers.append(block)
self.in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.base(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.gap(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def modeltype(model):
if model == 'resnet18':
return ResNet([2, 2, 2, 2])
elif model == 'resnet34':
return ResNet([3, 4, 6, 3])resnet = modeltype('resnet18').to(device)
📌 Loss function, Optimizer 설정
PATH = './cifar_resnet_early.pth' #저장할 모델 이름 지정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(resnet.parameters(), lr=1e-3)📌 모델 학습
train_loss_list = []
val_loss_list = []
n = len(trainloader) # 매 에폭마다 평균 loss 값 계산 위해서
early_stopping_loss = 1 # 가장 낮은 loss 함수 값에 해당하는 모델 저장 위해서, 초기 기준 1로 설정#배치 데이터 받아서 학습 진행
for epoch in range(51):
running_loss = 0
for data in trainloader:
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = resnet(inputs)
loss= criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
#배치 완료할 때 마다 평균 loss 값 계산
train_loss = running_loss / n
train_loss_list.append(train_loss)
val_loss = validation_loss(valloader)
val_loss_list.append(val_loss)
print('[%d] train loss : %.3f, validation loss : %.3f' %(epoch +1, train_loss, val_loss))
#현재 val 에서 loss 값이 기준보다 작으면 모델 저장 (train, val의 loss 함수 값과 에폭)
if val_loss < early_stopping_loss:
torch.save(resnet.state_dict(), PATH)
early_stopping_train_loss = train_loss
early_stopping_val_loss = val_loss
early_stopping_epoch = epoch
#학습 끝나면 조기종료한 에폭과 손실함수 값 출력
print('Final pretrained model >> [%d] train loss: %.3f , validation loss: %.3f' %(early_stopping_epoch + 1,
early_stopping_train_loss, early_stopping_val_loss))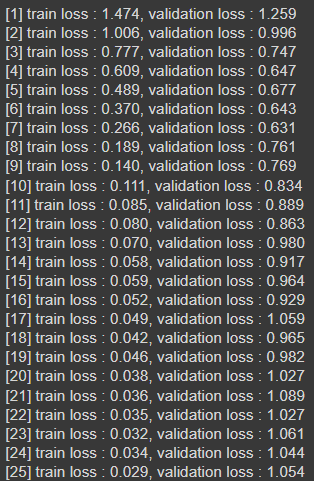

📌 Loss 확인
#loss plot 그리기
plt.plot(train_loss_list)
plt.plot(val_loss_list)
plt.legend(['train','validation'])
plt.title("Loss")
plt.xlabel("epoch")
plt.show()
plt.plot(train_loss_list[:15])
plt.plot(val_loss_list[:15])
plt.legend(['train','validation'])
plt.title("Loss")
plt.xlabel("epoch")
plt.show()
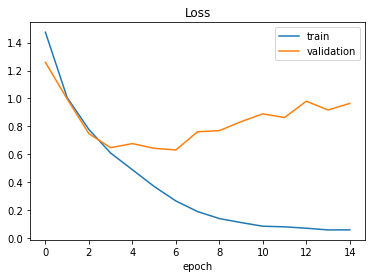
좌측은 전체 에폭의 그래프이고 우측은 에폭=15 까지만 출력한 결과이다. 에폭 6회 정도에서 가장 손실함수 값이 적게 나타났다.
📌 Test set 예측
# 평가 데이터로 예측 실시해서 정확도 확인
# output은 미니배치의 결과가 산출되기 때문에 for문을 통해서 test 전체의 예측값을 구한다.
correct = 0
total = 0
with torch.no_grad():
resnet.eval()
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = resnet(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0) # 개수 누적(총 개수)
correct += (predicted == labels).sum().item() # 누적(맞으면 1, 틀리면 0으로 합산)
print('Test accuracy: %.2f %%' % (100 * correct / total))
# ResNet (overfitting): 75.57 %
# ResNet (ealy stopping): 76.22 %
Test set에 대해서 예측을 실시할 경우 정확도는 80% 정도로 성능이 준수한 것을 확인할 수 있다.
📚 2. 교란 라벨 (Disturb Label) 사용하기
나머지 부분의 코드는 위에서 다룬 1.조기종료 파트와 동일하고, 교란 라벨을 생성하는 클래스만 추가하고 학습 과정에서 사용한다.
class DisturbLabel(torch.nn.Module):
def __init__(self, alpha, num_classes): #alpha:교란라벨 비율, num_classes:클래스 수
super(DisturbLabel, self).__init__()
self.alpha = alpha
self.C = num_classes
self.p_c = (1 - ((self.C - 1) / self.C) * (alpha / 100)) # Multinoulli distribution
self.p_i = (1-self.p_c)/(self.C-1)
def forward(self, y):
y_tensor = y.type(torch.LongTensor).view(-1, 1)
depth = self.C
y_one_hot = torch.ones(y_tensor.size()[0], depth) * self.p_i
y_one_hot.scatter_(1, y_tensor, self.p_c)
y_one_hot = y_one_hot.view(*(tuple(y.shape) + (-1,))) # create disturbed labels
distribution = torch.distributions.OneHotCategorical(y_one_hot) # sample from Multinoulli distribution
y_disturbed = distribution.sample()
y_disturbed = y_disturbed.max(dim=1)[1]
return y_disturbedDisturbLabel 객체를 정의한다. 교란라벨로 처리할 비율과 데이터의 클래스 개수를 입력받는다.
실제 라벨을 뽑을 확률을 self.p_c 로 정의하고, 나머지는 self.p_i로 정한다.
disturblabels = DisturbLabel(alpha=30, num_classes=10)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(resnet.parameters(), lr=1e-3)loss_ = [] # 그래프를 그리기 위한 loss 저장용 리스트
n = len(trainloader) # 배치 개수
for epoch in range(50):
running_loss = 0.0
for data in trainloader:
inputs, labels = data[0].to(device), data[1].to(device) # 배치 데이터
optimizer.zero_grad()
outputs = resnet(inputs) # 예측값 산출
labels = disturblabels(labels).to(device)
loss = criterion(outputs, labels) # 손실함수 계산
loss.backward() # 손실함수 기준으로 역전파 선언
optimizer.step() # 가중치 최적화
running_loss += loss.item()
loss_.append(running_loss / n)
print('[%d] loss: %.3f' %(epoch + 1, running_loss / n))
torch.save(resnet.state_dict(), PATH)
print('Finished Training')
# AlexNet: 0.207 (epoch 50)
# ResNet: 0.083 (epoch 10)위와 같은 방식으로 교란 라벨을 추가해서 학습을 진행할 수 있다.
📚 3. 라벨 스무딩 (Label Smoothing)
라벨 스무딩을 위해서는 손실함수를 새롭게 정의해야 한다. 파이토치에서 제공하는 nn.CrossEntropyLoss() 함수는 실제 라벨의 원-핫 벡터를 입력받을 수 없다. 따라서 라벨 스무딩을 적용하면 원-핫 벡터를 사용할 수 있도록 별도로 손실 함수를 만들어야 한다.
class LabelSmoothingLoss(nn.Module):
def __init__(self, classes, smoothing=0.0, dim=-1):
super(LabelSmoothingLoss, self).__init__()
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.cls = classes
self.dim = dim
def forward(self, pred, target):
pred = pred.log_softmax(dim=self.dim) # Cross Entropy 부분의 log softmax 미리 계산하기
with torch.no_grad():
# true_dist = pred.data.clone()
true_dist = torch.zeros_like(pred) # 예측값과 동일한 크기의 영텐서 만들기
true_dist.fill_(self.smoothing / (self.cls - 1)) # alpha/(K-1)을 만들어 줌(alpha/K로 할 수도 있음)
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence) # (1-alpha)y + alpha/(K-1)
return torch.mean(torch.sum(-true_dist * pred, dim=self.dim)) # Cross Entropy Loss 계산criterion = LabelSmoothingLoss(classes=10, smoothing=0.2)
optimizer = optim.Adam(resnet.parameters(), lr=1e-3)CIFAR10 데이터의 경우 클래스가 10개 이기 때문에 이에 맞춰서 설정하고, 스무딩 비율은 분석자의 판단에 따라서 적절하게 설정한다.
📚 Reference
딥러닝을 위한 파이토치 입문, 딥러닝호형 저, 영진닷컴
'머신러닝, 딥러닝 > 파이토치' 카테고리의 다른 글
| [파이토치 스터디] 전이학습, 모델 프리징 (0) | 2022.02.23 |
|---|---|
| [파이토치 스터디] 클래스 불균형 다루기 (가중 무작위 샘플링, 가중 손실 함수) (0) | 2022.02.23 |
| [파이토치 스터디] 오토인코더 (1) | 2022.02.16 |
| [파이토치 스터디] RNN, LSTM (0) | 2022.02.09 |
| [파이토치 스터디] AlexNet - CIFAR 10 이미지 분석 (0) | 2022.01.31 |




댓글