📚 가중 무작위 샘플링 (Weighted Random Sampling)
일반적으로 분류 문제에서 클래스가 불균형할 경우 과적합을 야기할 가능성이 높다. 딥러닝 모델 학습시에는 전체 데이터가 불균형 하더라도, 미니 배치를 뽑을 때 각 클래스를 균형 있게 뽑아서 학습시킬 수 있다. 이 방식을 가중 무작위 샘플링(weighted random sampling) 이라고 한다.
📌 가중치 함수 설정 : torchvision.datasets.ImageFolder 사용
def make_weights(labels, nclasses):
labels = np.array(labels) # where, unique 함수를 사용하기 위해 numpy로 변환한다.
weight_list = [] # 가중치를 저장하는 배열을 생성한다.
for cls in range(nclasses):
idx = np.where(labels == cls)[0]
count = len(idx) #각 클래스 데이터 수 카운트
weight = 1/count
weights = [weight] * count #라벨이 뽑힐 가중치를 1/count로 동일하게 전체 라벨에 할당
weight_list += weights
return weight_list라벨이 0부터 N까지 순서대로 정렬되어 있는 경우 ImageFolder를 사용해서 불러오면 라벨이 정렬되어 데이터가 생성된다. 따라서 라벨을 기준으로 순차적으로 가중치를 할당하면 된다.
📌 가중치 함수 설정 : torchvision.datasets.ImageFolder 사용 X
def make_weights(labels, nclasses):
labels = np.array(labels)
weight_arr = np.zeros_like(labels)
_, counts = np.unique(labels, return_counts=True)
for cls in range(nclasses):
weight_arr = np.where(labels == cls, 1/counts[cls], weight_arr)
# 각 클래스의의 인덱스를 산출하여 해당 클래스 개수의 역수를 확률로 할당한다.
# 이를 통해 각 클래스의 전체 가중치를 동일하게 한다.
return weight_arr
각 이미지 데이터가 순서대로 정렬되어 있지 않은 경우에는 인덱싱이 매칭이 되지 않기 때문에 위 방식으로 코딩해야 한다.
📌 데이터 불러오기
transf = tr.Compose([tr.Resize((16,16)),tr.ToTensor()])
trainset = torchvision.datasets.ImageFolder(root='./class', transform=transf) # 데이터 세트 불러오기예제 데이터를 불러온다. 이 데이터는 클래스가 2개이고, 14 vs 4 개로 분포가 비대칭적이다. 각 이미지는 서로 분류되어서 class 폴더 안에 들어있다.
📌 가중치 생성하기
weights = make_weights(trainset.targets, len(trainset.classes))
weights = torch.DoubleTensor(weights)
print(weights)
가중치를 생성하고 텐서로 변환한다. 모든 데이터에 대한 각각의 가중치가 생기고, 각 클래스의 가중치 합은 1이다.
📌 데이터로더 생성하기
sampler = torch.utils.data.sampler.WeightedRandomSampler(weights, len(weights))
trainloader_wrs = DataLoader(trainset, batch_size=6, sampler = sampler)
trainloader_rs = DataLoader(trainset, batch_size=6, shuffle=True)총 18개 데이터가 있는데 여기서는 배치를 6으로 설정한다.
📌 무작위 샘플링
for epoch in range(5):
for data in trainloader_rs:
print(data[1])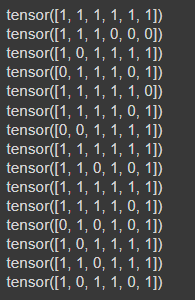
각 배치에 배정된 클래스를 살펴보면, 개수가 많은 클래스인 1이 많이 할당된 것을 알 수 있다.
📌 가중 무작위 샘플링
for epoch in range(5):
for data in trainloader_wrs:
print(data[1])
가중 무작위 샘플링을 실시하면, 비교적 0에 해당하는 클래스가 자주 선택된 것을 확인할 수 있다.
📚 가중 손실 함수
✅ 중간 제목
✔ 🏷️📌📘
가중 손실 함수는 수가 적은 클래스에 대해서 더 큰 가중치를 부여해서 업데이트 균형을 맞추는 것이다. 파이토치의 nn.CrossEntropyLoss는 가중 손실 함수를 제공하기 때문에, 미리 정의된 파라미터 weight 값을 부여하면 된다.
import torch.nn as nn
import torch
num_ins = [40,45,30,62,70,153,395,46,75,194] # 실제 클래스 수
weights = [1 - (x/sum(num_ins)) for x in num_ins]
class_weights = torch.FloatTensor(weights).to(device)
criterion = nn.CrossEntropyLoss(weight=class_weights)
여기서 num_ins는 실제 데이터의 각 클래스의 개수를 카운트한 리스트이다. 여기서는 가중치를 각 클래스의 확률을 구하고, 1에서 이 값을 뺀 것을 가중치로 사용했다. class_weights는 비율이 텐서 형태로 저장되어 있고 이를 크로스 엔트로피 함수의 파라미터로 입력하면 된다.
📚 Reference
딥러닝을 위한 파이토치 입문, 딥러닝호형 저, 영진닷컴
'머신러닝, 딥러닝 > 파이토치' 카테고리의 다른 글
| [파이토치 스터디] 준지도 학습 (Semi-Supervised Learning) (0) | 2022.02.24 |
|---|---|
| [파이토치 스터디] 전이학습, 모델 프리징 (0) | 2022.02.23 |
| [파이토치 스터디] 과적합 방지를 통한 모델 성능 개선 (0) | 2022.02.23 |
| [파이토치 스터디] 오토인코더 (1) | 2022.02.16 |
| [파이토치 스터디] RNN, LSTM (0) | 2022.02.09 |




댓글