📚 분석 개요



• 진행기간 : 2021.04.01 ~ 2022.06.15
• 참여 팀원 : 장영진, 김기현(IS전공), 김선규(회계 전공)
• 사용 데이터 : London Airbnb Data
• 사용 언어 : R
• 분석 목적 :
런던 에어비엔비 데이터를 다각적으로 분석하고 특성을 파악한다. 그리고 분석한 내용을 바탕으로 각 숙소에 대한 적절한 가격을 제안하는 모델을 구축한다.
📌 목차
1. Introduction
1.1 에어비앤비 소개
1.2 핵심 전략
1.3 분석 목적
2. 데이터 출처
2.1 Inside Airbnb
2.2 London Data Store
3. 데이터 전처리
3.1 Inside Airbnb 데이터 전처리
3.2 London Data Store 데이터 전처리
3.3 최종 변수 정리
4. Descriptive Analytics
4.1 기초통계량 확인
4.2 시각화
5. Predictive Analytics
5.1 Multiple Regression : Model #1
5.2 Multiple Regression : Model #2
5.3 결과 비교
5.4 로지스틱 회귀
6. Conclusion
📚 1. Introduction
✅ 1.1 에어비앤비 소개
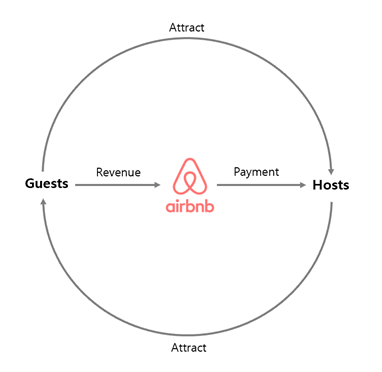
에어비앤비는 세계 최대의 숙박공유플랫폼으로 호스트가 본인의 집 전체 혹은 일부를 게스트에게 빌려주는 방식으로 운영된다. 수익은 호스트와 게스트를 중개하며 수수료를 얻는 방식으로 사업을 운영하고 있다. 에어비앤비의 비즈니스 모델을 도식화하면 아래와 같다. 현재 약 220여 개국, 10만여 도시, 400만 호스트, 800만 게스트를 보유하고 있다 .
✅ 1.2 핵심 전략
에어비앤비의 핵심 전략은 ‘Network Effect’이다. Network Effect란 사용자가 증가할수록 해당 제품이나 서비스에서 창출되는 효과나 가치가 증가하는 것을 의미한다. 에어비앤비의 사용자는 서로를 필요로 하는 호스트와 게스트라는 그룹으로 나눠져 있고 두 그룹 간에 거래관계가 이루어진다. 이러한 네트워크를 양면 네트워크라고 한다. 이러한 네트워크에서는 한 그룹내에서의 사용자가 많아지면 연결 대상이 되는 다른 그룹의 사용자들의 연결 가능성이 높아져 네트워크 가치가 높아지는 현상이 일어난다.

전통적으로 호텔, 리조트 등의 숙박업은 높은 초기 투자비용과 관리비용 때문에 시장의 진입장벽이 높다. 하지만 에어비앤비는 고객의 범위를 게스트에서 호스트로 확장하여 양면 네트워크를 구축하였고, 최종적으로 숙박 공유 플랫폼을 제공함으로써 숙박업에 대한 높은 진입 장벽을 허물 수 있었다
✅ 1.3 분석 목적
에이비앤비의 수익성을 극대화하기 위해서는 네트워크 상의 Node를 많이 확보하여 핵심 전략인 양면 네트워크의 효과를 최대화하는 것이 중요하다. 하지만 여전히 호텔을 선호하는 부동 수요층이 존재하고, 주 고객층인 MZ 세대의 경우 브랜드에 대한 충성도가 낮으며 가격에 매우 민감하게 반응한다. 따라서 에어비앤비가 양면 네트워크를 통해서 지속적인 수익을 창출하기 위해서는 호스트와 게스트 모두에게 합리적인 가격을 제시하는 것이 무엇보다 중요하다.
본 데이터 분석의 목적은 호스트와 게스트 모두에게 합리적인 숙소 가격을 제시할 수 있는 기준을 마련하는데 있다. 적절한 가격과 신뢰도 있는 기준을 마련하여 고객과 호스트의 신뢰성을 확보하고 가격 안정 및 규격화를 통해 산업의 활성화 및 매출의 증대를 기대할 수 있다. 이를 통해 에어비앤비는 회사의 수익을 극대화시킬 수 있을 것이며 호스트 또한 네트워크가 활성화되면 재방문 게스트 등을 통한 고객 확보가 꾸준히 이어져 수익성을 높일 수 있을 것이며 게스트는 신뢰도 있는 가격으로 호텔에 비해 상대적으로 저렴한 숙소를 사용함으로써 여행 경비를 절약할 수 있을 것으로 기대한다.
📚 2. Data Source
London의 Airbnb 가격 예측을 위해 사용된 데이터는 Inside Airbnb와 London Data Store 두 곳에서 수집하였다. 각 데이터의 출처는 아래와 같다.
✅ 2.1 Inside Airbnb ( http://insideairbnb.com/get-the-data/ )
Inside Airbnb는 Airbnb의 웹사이트에 등록되어 있는 숙소에 대한 정보를 추출하여 각 도시별로 종합한 자료를 대중에게 제공하고 있다. Airbnb의 공식 웹사이트에서 자료가 추출되었다는 점, 해당 자료에 가격 예측에 필요한 변수들인 가격, 숙소에 대한 위치 및 세부 정보, host에 대한 정보, 예약 관련 정보 등이 폭넓게 담겨 있다는 점, 실증적인 데이터를 제공한다는 점에서 본 프로젝트의 목적에 적절한 자료라고 판단된다.
✅ 2.2 London Data Store ( https://data.london.gov.uk/dataset/average-private-rents-borough )

London data store는 Greater London Authority (GLA)의 공개 데이터 허브로 London과 관련된 데이터를 정부 차원에서 제공하고 있어서 비교적 신뢰도가 높은 데이터를 얻을 수 있다. 이 분석에서는 Airbnb의 가격들이 해당 지역의 부동산 임대 시장 가격을 적절히 반영하고 있는지 살펴보기 위해 동 웹사이트에서 제공하는 개인 임대 시장의 월 평균 임대료 데이터 자료를 사용하였다. Airbnb 숙소의 호스트들이 주관적으로 가격을 책정하는데 책정된 가격이 실제 부동산 렌트 가격과 어떠한 차이가 있는지 살펴보는데 필요한 자료라고 판단된다.
📚 3. 데이터 전처리
✅ 3.1 Inside Airbnb 데이터 전처리
Airbnb 숙소에 관련된 Raw data는 총 74개의 Column, 74841개의 row로 구성되어 있다. 이 중에 [host_id], [host_name], [picture_url] 등 가격에 영향을 주지 않을 것이라고 판단되는 46개의 변수를 제거했다. 그리고 주어진 데이터셋에서 다음과 같이 파생변수를 생성하였다.
✔ [host_since]: 데이터 최종 업데이트 일자를 기준으로 숙소를 처음 등록한 시점부터 현재까지의 일(days) 수를 계산 (예 : 2020.04.01 – 2009.10.03 = 4198days)
✔ [bathroom_text]: 표기 방식에서 통일되지 않은 텍스트를 삭제하고 숫자로만 계산
✔ [description]: 호스트가 작성한 숙소에 대한 설명으로 불용어를 처리 후 유의미한 단어의 개수를 세어 호스트가 숙소에 대해 얼마나 자세한 설명을 하고 있는지를 수치화
✔ [host_about]: 호스트의 소개로 불용어를 처리 후 유의미한 단어의 개수를 세어 호스트가 본인에 대한 설명을 얼마나 자세히 하고 있는지를 수치화 하여 변수로 사용
✔ [amenities]: 숙소에서 제공하는 편의시설, 물품 목록으로 text로 나열되어 있는 데이터를 제공하는 amenities 숫자를 세서 얼마나 많은 편의시설, 물품 등을 제공하는지를 수치화 하여 사용
✅3.2 London Data Store 데이터 전처리
2016년부터 2019년까지 1분기 및 3분기의 런던 지역(borough)별 평균 임대료에 대한 데이터를 제공한다. Airbnb 숙소 가격과 런던의 평균 임대료를 비교하기 위해서 이 데이터를 수집하였다. Inside Airbnb 숙소 데이터의 기준 날짜가 2021년 4월이지만, london data store에서는 이 일자의 데이터가 없으므로 비교를 위해서 Moving Average를 사용하여 아래와 같이 런던 지역별 2021년 1분기의 평균 임대료를 계산하여 사용했다.
여기서는 2021년 1분기 값을 4분위수로 구간을 나누어 범주형 변수로 사용했다 (상위 1~25% : 4th_qut, 상위 25~50% : 3th_qut, 상위 50~75% : 2th_qut, 상위 75%~100% : 1th_qut). 평균 임대료가 높은 지역일수록 런던의 중심에 가까운 지역임으로 해당 변수는 런던 지역(중심가~외각)의 대용치로 사용한다.

✅ 3.3 최종 변수 정리
분석 및 모델 학습에 사용할 최종 변수 목록은 다음과 같다.
| 변수 이름 | 변수 유형 | 변수 이름 | 변수 유형 |
| description | integer | beds | integer |
| host_since | numeric | amenities | integer |
| host_location | character | price | numeric |
| host_about | integer | availability_90 | integer |
| host_response_time | factor | availability_365 | integer |
| host_response_rate | numeric | number_of_reviews | integer |
| host_is_superhost | factor | review_scores_rating | integer |
| neighbourhood_cleansed | character | review_scores_accuracy | integer |
| latitude | numeric | review_scores_cleanliness | integer |
| longitude | numeric | review_scores_checkin | integer |
| room_type | factor | review_scores_communication | integer |
| accommodates | integer | review_scores_location | integer |
| bathrooms_text | numeric | review_scores_value | integer |
| bedrooms | integer | instant_bookable | integer |
| AveRentPrice | factor |
✅ 전처리 부분 코드
#load library
library(tidyverse)
library(dplyr)
library(ggplot2)
library(tm)
library(data.table)
library(SnowballC)
library(tidytext)
library(tidyverse)
library(textdata)
#load data
setwd('C:/Users/janji/Desktop/그룹 프로젝트')
london <- read.csv('London listing.csv')
#check class of variables
sapply(london, class)
#check missing values
colSums(is.na(london))
#remove rows with missing values
london <- na.omit(london)
############## pre-processing #################
########## [description] / [host_about] ##########
# counting number of words
#customized function
cleanFun <- function(htmlString) {
htmlString <- gsub("<.*?>", "", htmlString)
htmlString <- gsub("[^A-Za-z]", " ", htmlString)
#return(removeWords(htmlString, stopwords('en')))
htmlString <- removeWords(htmlString, stopwords('en'))
htmlString <- gsub(" +", " ", htmlString)
return(sapply(strsplit(htmlString, " "), length))
}
#apply customized function
london$description <- cleanFun(london$description)
london$host_about <- cleanFun(london$host_about)
########## [host_since] ##########
#remove '' values
dplyr::count(london, host_since, sort = TRUE)
london$host_since[which(london$host_since== '')]<- NA
london <- na.omit(london)
#calculate start date of hosting
london$host_since <- as.Date("2021-04-01")-as.Date(london$host_since)
#change object time from 'difftime' to 'numeric'
london$host_since <- as.numeric(london$host_since, units='days')
########## [host_response_time] ##########
# caution : N/A & "" type exist (text)
table(london$host_response_time)
#london %>% filter(host_response_time == '')
for(i in 1:dim(london)[1]){
if(london[i,5]=='N/A'){
london[i,5]='NoInfo'
}else{
next
}
}
for(i in 1:dim(london)[1]){
if(london[i,5]==''){
london[i,5]='NoInfo'
}else{
next
}
}
#change data type for dummy variable (character -> factor)
london$host_response_time=as.factor(london$host_response_time)
########## [host_response_rate] ##########
table(london$host_response_rate)
#N/A 와 "" 값은 '0%' 로 변경
for(i in 1:dim(london)[1]){
if(london[i,6]=='N/A'){
london[i,6]='0%'
}else{
next}}
for(i in 1:dim(london)[1]){
if(london[i,6]==''){
london[i,6]='0%'
}else{
next}}
#change data type (factor -> numeric)
london$host_response_rate <- as.numeric(gsub("\\D", "", london$host_response_rate))
#too much skewness !
hist(london$host_response_rate)
########## [host_is_superhost] ##########
#dummy variable --> t=1, f=0
london$host_is_superhost <- ifelse(london$host_is_superhost=='t',1,0)
########## [room_type] ##########
table(london$room_type)
#replace outlier with most frequent variable : 'Entire home/apt'
#london %>% filter(room_type=='')
#which(london$room_type == '')
#london[66856,11] = 'Entire home/apt'
#check variable distribution
dplyr::count(london, room_type, sort = TRUE)
#change data type
london$room_type <- as.factor(london$room_type)
#barplot graph
tbl <- table(london$room_type)
barplot(tbl, beside = TRUE, legend = TRUE)
########## [bathrooms_text] ##########
#check variable distribution
dplyr::count(london, bathrooms_text, sort = TRUE)
#total 41 types of baths and shared-baths --> Regardless of bathroom type, only count number of bathroom
which(london$bathrooms_text == '')
london$bathrooms_text[which(london$bathrooms_text== '')]<- '1 bath'
london$bathrooms_text[which(london$bathrooms_text== 'Shared half-bath')] <- '1 bath'
london$bathrooms_text[which(london$bathrooms_text== 'Half-bath')]<- '1 bath'
london$bathrooms_text[which(london$bathrooms_text== 'Private half-bath')]<- '1 bath'
london$bathrooms_text <- as.numeric(gsub("[A-Za-z]", "", london$bathrooms_text))
#london$bathrooms_text <- ifelse(london$bathrooms_text==NA, 0, next)
#barplot graph
tbl <- table(london$bathrooms_text)
barplot(tbl, beside = TRUE, legend = TRUE)
\
########## [bedrooms] ##########
dplyr::count(london, bedrooms, sort = TRUE)
#replace NA with 0 (assuming that there is no bedroom)
london[is.na(london$bedrooms),'bedrooms'] <- 0
########## [beds] ##########
dplyr::count(london, beds, sort = TRUE)
#replace NA with 0 (assuming that there is no bed)
london[is.na(london$beds),'beds'] <- 0
########## [amenities] ##########
#count number of amenities
london$amenities <- sapply(strsplit(london$amenities, ","), length)
########## [price] ##########
#remove "$" sign
london$price = gsub("[\\$]","",london$price)
#change data type
london$price <- as.numeric(london$price)
########## [instant_bookable] ##########
london$instant_bookable <- ifelse(london$instant_bookable=='t',1,0)
###############################################
###### Make variable : Average Rent Price ######
###############################################
#load data
library(readxl)
rentprice <- read_xlsx('AverageRentPrice.xlsx', skip = 1)
#remove unnecessary region
rentprice <- rentprice[1:33,]
#분위수 확인
quantile(rentprice$Q1)
View(arrange(rentprice,desc(Q1)))
###make dummy variable with rent price
#위에서 출력된 각 분위수 구간을 결과를 눈으로 확인하면서 리스트 작성함
london$AvgRentPrice <- NA
qutile_4th <- c('Kensington and Chelsea','Westminster','City of London
','Camden','Hammersmith and Fulham','Richmond upon Thames','Islington','Wandsworth')
qutile_3th <- c('Hackney','Tower Hamlets','Lambeth','Southwark','Brent','Merton','Barnet','Haringey')
qutile_2th <- c('Ealing','Newham','Greenwich','Kingston upon Thames','Harrow','Hounslow','Enfield','Waltham Forest')
qutile_1th <- c('Lewisham','Redbridge','Bromley','Hillingdon','Barking and Dagenham','Havering','Sutton','Croydon','Bexley')
london$AvgRentPrice <- ifelse(london$neighbourhood_cleansed %in% qutile_4th,'4th_qut',
ifelse(london$neighbourhood_cleansed %in% qutile_3th,'3th_qut',
ifelse(london$neighbourhood_cleansed %in% qutile_2th,'2th_qut','1th_qut')))
#select necessary variables : 모델 1에 들어가는 변수들 선택하는 과정
london_mod1 <-subset(london, select =c('price','neighbourhood_cleansed','AvgRentPrice','description','host_since','host_about','host_response_time','host_is_superhost','room_type','accommodates','bathrooms_text','bedrooms','amenities','availability_90','number_of_reviews','review_scores_rating','instant_bookable'))
#remove missing values
london_mod1 <- london_mod1 %>% filter(complete.cases(london_mod2))
#check class of each variables
sapply(london_mod1, class)
#change to factor variables
london_mod1$AvgRentPrice <- as.factor(london_mod1$AvgRentPrice)
london_mod1$host_is_superhost <- as.factor(london_mod1$host_is_superhost)
london_mod1$instant_bookable <- as.factor(london_mod1$instant_bookable)
#change name of variable
london_mod1 <- rename(london_mod1, "bathrooms" = "bathrooms_text")
### model1, model2 각각 따로 저장
#save each dataframe
write.csv(london_mod1,'london_mod1.csv')
write.csv(london,'london_mod2.csv')
📚 4. Descriptive Analytics
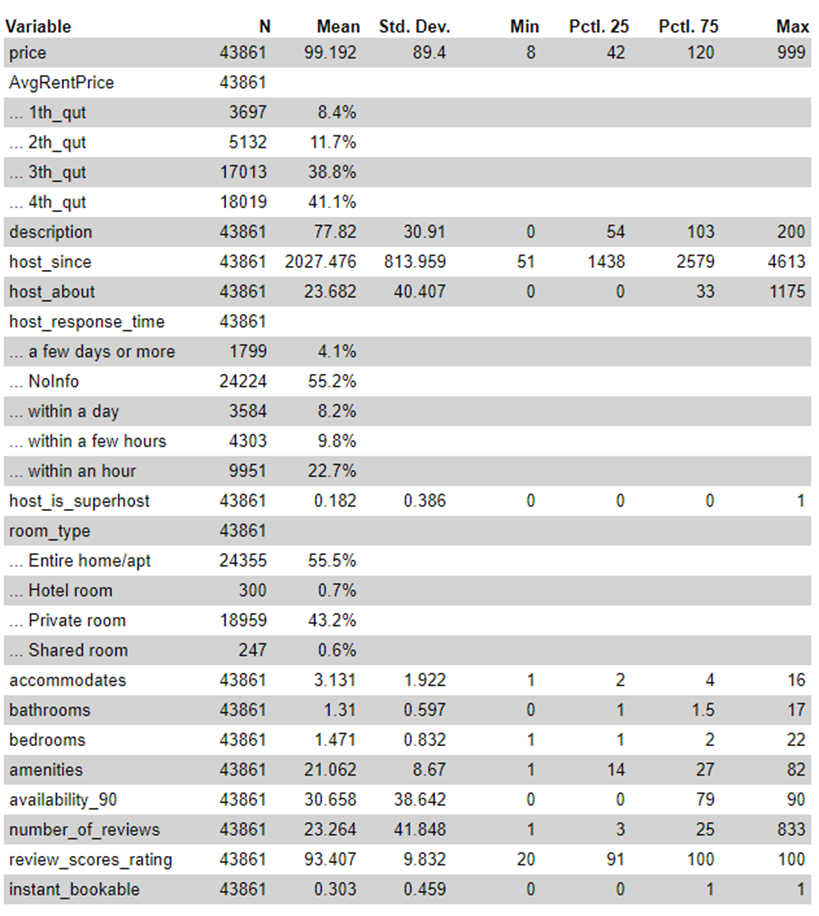
✅ 4.1 기초통계량 확인
✅ 4.2 시각화
주요 변수에 대해서 태블로와 R을 사용하여 시각화를 진행하였다.
📌1. 지역(Borough)별 평균 Airbnb 숙소 가격

Kensington and Chelsea, Westminster, City of London, Camden 등 런던 중심가에 가까운 지역일수록 Airbnb의 가격이 높은 것을 알 수 있다. 평균 가격이 가장 비싼 Kensington and Chelsea는 평균 가격이 가장 저렴한 Bexley보다 약 3배 가량 높게 산정되어 있다.
📌2. 지역(Borough)별 평균 렌트 가격

런던의 평균 렌트 또한 Kensington and Chelsea, Westminster, City of London, Camden 등 런던 중심가에 가까운 지역일수록 높은 것을 알 수 있다. Airbnb 가격과 동일하게 평균 렌트가 가장 비싼 Kensington and Chelsea는 평균 렌트가 가장 저렴한 Bexley보다 약 3배 가량 높게 산정되어 있다. 따라서 평균 렌트 가격이 높은 지역일 수록 Airbnb 가격 또한 높게 책정될 것이라 예상하고 Scatter Plot를 작성해 두 가격의 상관관계를 살펴보았다.
📌3. 렌트 가격과 Airbnb 가격의 상관관계

예상한대로 평균 렌트와 Airbnb 가격 간에 양의 상관관계가 있음을 알 수 있다. 따라서 Airbnb의 가격을 결정하는데 숙소의 지역 그리고 그 지역의 렌트 시세가 중요한 변수임을 알 수 있다.
📌 4. Room type에 따른 평균 Airbnb 숙소 가격

Entire home/apt와 Hotel Room의 평균 가격이 비슷하고, Private room과 Shared room의 평균 가격이 비슷하다. 집 전체를 빌려주는 유형(Entire home/apt, Hotel Room)의 Airbnb 가격이 집의 일부 또는 방만 빌려주는 유형(Private room, Shared room)보다 약 3배 높은 것을 알 수 있다.
📌 5.지역(Borough)별 Airbnb 숙소개수

숙소 유형은 Entire home/apt과 Private home이 많은 것을 알 수 있다. 집 전체를 빌려주는 유형과 집의 일부만 빌려주는 유형의 비율은 지역별로 조금씩 차이가 있지만 총 숙소의 개수가 적은 지역일 수록 두 유형의 비율이 비슷하다. 가장 큰 차이를 보이는 지역인 Westminster, Kensington and Chelsea는 집 전체를 빌려주는 숙소의 유형이 3배에서 4배 가량 많은 것을 알 수 있다.
📌 6. Room type에 따른 분포


Airbnb 숙소의 위도, 경도 데이터를 이용하여 숙소 유형별로 지도 상에 표시하였다. 숙소가 런던 전 지역에 걸쳐서 분포되어 있으나 외각에서 런던 중심가에 가까울 수록 많은 것을 알 수 있다.
📚 5. Predictive Analytics
예측 분석 과정에서는 선형회귀를 이용한 모델 2가지와, 로지스틱 회귀를 이용한 분류모델 1개를 비교하였다.
✅ 5.1 Multiple Regression : Model #1
모델 1에서는 분석자가 유의할 것이라고 판단한 총 15개의 독립변수를 선택하여 회귀 모델에 포함하였다.
✔ 종속변수: [price]
✔ 독립변수: 총 15개
| 변수 이름 | 선정 이유 |
| description | 숙소에 대한 소개가 길수록 호스트가 에어비앤비 임대 사업에 적극적인 것으로 볼 수 있어 이는 가격에 영향을 미칠 것으로 예상한다. |
| host_since | 에어비앤비의 가격은 호스트가 주관적으로 책정하기에 호스트에 대한 정보인 호스트의 활동 기간, 호스트에 대한 설명, Superhost 여부, 응답 시간은 가격에 영향을 미칠 것으로 예상한다. |
| host_about | |
| host_is_superhost | |
| host_response_time | |
| room_type | 숙소 유형에 따라 Airbnb의 평균 가격에 큰 차이를 보였음으로 가격에 영향을 미치는 중요한 변수일 것이다. |
| accommodates | 수용 인원수가 많을수록 숙소의 가격이 올라갈 것임으로 수용 인원수는 가격에 영향을 미칠 것으로 예상한다. |
| bathrooms | 화장실의 개수는 숙소의 규모를 판단할 수 있는 요소이기에 화장실의 개수는 가격에 영향을 미칠 것으로 예상한다. |
| bedrooms | 방의 개수는 숙소의 규모를 판단할 수 있는 요소이기에 방의 개수는 가격에 영향을 미칠 것으로 예상한다. |
| amenities | 숙소에서 제공하는 편의 시설 및 물품이 많을수록 호스트가 숙소 유지에 더 많은 비용을 부담하게 될 것임으로 숙소 책정 시 가격에 영향을 미칠 것으로 예상한다. |
| availability_90 | 검색일로부터 90일 간 예약이 가능한 날짜를 나타내는 변수로 예약 가능한 일수에 따라 호스트가 예약률을 높이기 위해 가격을 조정할 유인이 있음으로 가격에 영향을 미칠 것으로 예상한다. |
| number_of_reviews | 후기가 많은 숙소의 호스트는 가격을 높일 유인이 있을 것으로 예상한다. |
| review_scores_rating | 후기 점수에 따라서 호스트가 가격을 조정할 유인이 있을 것으로 예상한다. |
| instant_bookable | 호스트의 수락없이 예약 가능한 숙소는 신속한 예약으로 이어질 수 있기에 즉시 예약 가능 여부는 가격에 영향을 미칠 것으로 예상한다. |
| AvgRentPrice | 평균 임대료는 지역의 위치에 따라 달라짐으로 숙소가 위치해 있는 지역은 가격에 영향을 미칠 것으로 예상한다. |
### Linear Regression : Model 1
#load dataset (혼선 방지 위해 데이터 새로 불러옴)
london_mod1 <- read.csv('london_mod1.csv',row.names = 1)
reg_mod1 <- lm(price ~. -neighbourhood_cleansed,data=london_mod1)
summary(reg_mod1)
#stargazer(reg_mod1,type='text',no.space=TRUE)
stargazer(reg_mod1,type='html',no.space=TRUE,out='Regression-Model1.doc')
###가정사항 체크
#linearity 확인
plot(reg_mod1)
#normality 확인
hist(residuals(reg_mod1), breaks=100, col = "blue",main='Histrogram of residuals - Normality Check')
#다중공산성 확인
vif<-vif(reg_mod1)
#등분산성 확인
bp<-bptest(reg_mod1)
vif
bp
stargazer(vif,type='html',out='vifs.doc',no.space=TRUE,title='VIFs')✅5.2 Multiple Regression : Model #2
모델 2에서는 알고리즘으로 변수 선택(Forward, Backward, Stepwise)을 하기 위해 최종 변수에서 [host_location], [neighbourhood_cleansed], [latitude], [longitude]를 제외한 변수를 모두 포함하였다.
✔ 종속변수: [price]
✔ 독립변수: 총 24개
| AvgRentPrice | description | host_since | host_about |
| host_is_superhost | room_type | Accommodates | bathrooms |
| amenities | availability_90 | availability_365 | host_response_time |
| host_response_rate | bathrooms | Beds | review_scores_rating |
| review_scores_accuracy | review_scores_cleanliness | review_scores_checkin | review_scores_communication |
| review_scores_location | review_scores_value | number_of_reviews | instant_bookable |
### Linear Regression : Model 2
#load data (혼선 방지 위해 데이터 새로 불러옴)
london_mod2 <- read.csv('london_mod2.csv',row.names = 1)
#위치, 위도, 경도 변수 삭제
london_mod2 <- subset(london_mod2, select = -c(host_location,neighbourhood_cleansed,longitude,latitude))
## Variable Selection by Algorithm
#regression with all variables
reg_all <-lm(price~., data=london_mod2)
summary(reg_all)
#select variables with algorithm : STEPWISE
step(reg_all, direction='both')
#run regression with chosen variables
reg_all_both <- lm(formula = price ~ host_since + host_about + host_response_time +
host_response_rate + host_is_superhost + room_type + accommodates +
bathrooms_text + bedrooms + beds + amenities + availability_90 +
availability_365 + number_of_reviews + review_scores_rating +
review_scores_cleanliness + review_scores_checkin + review_scores_communication +
review_scores_location + review_scores_value + instant_bookable +
AvgRentPrice, data = london_mod2)
#select variables with algorithm : FORWARD
step(reg_all, direction='forward')
reg_all_forward <- lm(formula = price ~ description + host_since + host_about +
host_response_time + host_response_rate + host_is_superhost +
room_type + accommodates + bathrooms_text + bedrooms + beds +
amenities + availability_90 + availability_365 + number_of_reviews +
review_scores_rating + review_scores_accuracy + review_scores_cleanliness +
review_scores_checkin + review_scores_communication + review_scores_location +
review_scores_value + instant_bookable + AvgRentPrice, data = london_mod2)
#select variables with algorithm : BACKWARD
step(reg_all,direction='backward')
reg_all_backward <- lm(formula = price ~ host_since + host_about + host_response_time +
host_response_rate + host_is_superhost + room_type + accommodates +
bathrooms_text + bedrooms + beds + amenities + availability_90 +
availability_365 + number_of_reviews + review_scores_rating +
review_scores_cleanliness + review_scores_checkin + review_scores_communication +
review_scores_location + review_scores_value + instant_bookable +
AvgRentPrice, data = london_mod2)
#export results
library(stargazer)
stargazer(reg_all_both,reg_all_forward,reg_all_backward, type='html', no.space = TRUE,out='Regression-Model2.doc')✅ 5.3 결과 비교
📌모델 1

독립 변수 [description]과 [host_response_time] 중 NoInfo, within a day, within an hour은 통계적으로 유의하지 않은 결과가 나왔다. 수정된 결정 계수는 0.505 (50.5%)로 본 모델의 설명력이 50% 이상되어 reasonable하다고 볼 수 있다.
📌모델 2

독립 변수 [description]과 [host_response_time] 중 NoInfo, [review_scores_accuracy]는 통계적으로 유의하지 않은 결과가 나왔다. [description]과 [host_response_time] 중 NoInfo가 Price와 유의하지 않은 상관관계인 것을 Model #1과 동일하나 Model #1에서는 within a day, within an hour 또한 유의하지 않은 결과를 보여준다. Model #2의 수정된 결정 계수는 0.514 (51.4%)로 Model #1보다 더 높은 설명력을 가지고 있으나 독립 변수의 개수가 더 많아 설명력이 올라간 것으로 판단된다. 그렇기 때문에 Model #2가 절대적으로 Model #1보다 더 뛰어나다고 볼 수 없다. 따라서 본 프로젝트의 최종 모델로는 해석 용이성을 위하여 분석자가 논리적으로 선택한 변수들로 구성된 Model #1을 선택한다.
✅ 선형회귀 가정 검증
1. 선형성 (Linearity)

→ 무작위 오차 분포 확인됨으로 선형성 가정을 만족한다. (회색 점선과 빨간 선 일치)
2.정규성 (Normality)

→ Residual의 히스토그램이 정규 분포의 형태를 보임으로 정규성 가정을 만족한다.
3. 등분산성 (Homoscedasticity)

→ P-Value가 귀무 가설을 기각시킴으로 등분산성의 가정을 만족시키지 못한다.
4. 다중공선성 (Multicollinearity)

→ 모든 변수의 VIF가 10보다 작게 나왔음으로 다중공선성이 만족된다고 볼 수 있다.
5. 독립성 (Independence of error)
→일반적으로 한 호스트의 가격 책정이 다른 호스트의 가격에 영향을 미치지 않음으로 독립성을 만족한다고 볼 수 있다.
따라서 최종 회귀 모델은 아래와 같이 나타낼 수 있다.

평균 월세가 높은 지역(부촌)일수록, 수용인원이 많을수록, 방과 화장실의 수가 많을수록 Airbnb의 가격이 높다. 더하여, 호스트가 Superhost이고, 숙소를 호스트의 수락없이 바로 예약이 가능할 수록 가격이 높다. 또한, 집 전체를 빌릴수록 가격이 높고 호텔, 개인 방, 공유실의 순으로 Airbnb 가격이 낮아진다.
✅5.4 로지스틱 회귀
동일한 데이터로 해당 숙소의 가격이 평균 이상인지 이하인지를 분류하는 이진 분류 모델을 만들어 보았다. 이를 통해 선형 회귀로 [Price]를 예측하는 모델과, 로지스틱 회귀로 [Price]의 값을 평균 이상/이하로 분류하는 모델에서 나타나는 유의미한 변수를 비교해 보고자 하였다. 로지스틱 회귀를 위해서 [Price]변수의 값을 중앙값 보다 높으면 1, 낮으면 0으로 지정하여 [Price_bin]이라는 종속변수를 생성하였다
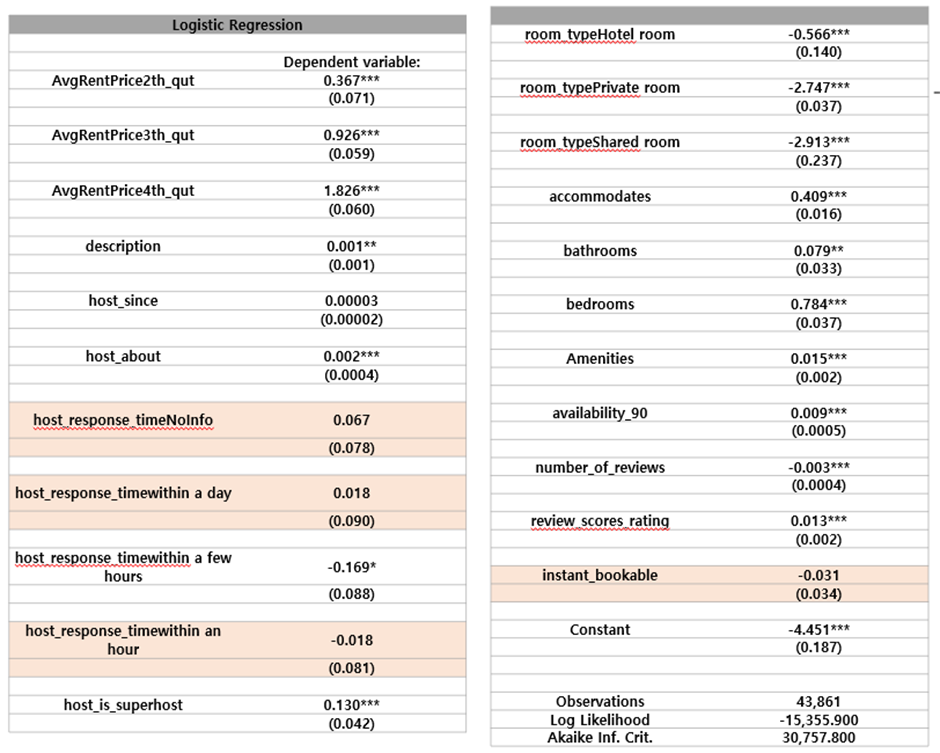
[description]의 경우 Model #1 결과에서는 유의하지 않았으나 로지스틱 회귀 분석에서는 약하지만 가격과 유의한 상관관계를 보여준다. [host_since]는 Model #1 결과에서는 유의한 독립변수이지만 로지스틱 회귀 분석에서는 통계적으로 유의하지 않다.
[instant_bookable]은 Model #1에서 유의하지만 로지스틱 회귀 분석에서는 유의하지 않은 결과가 나타났다. 로지스틱 회귀 분석 결과, 종속변수와 독립변수의 상관관계 대부분이 선형 회귀 분석과 유사한 결과를 보여주지만 일부 차이가 있음을 알 수 있다.
###Logistic Regression
#setwd('C:/Users/janji/Desktop/21년도 1학기/Business Analytics/그룹 프로젝트')
#데이터 불러오기
london_mod1 <- read.csv('london_mod1.csv',row.names=1)
#neighbourhood_cleansed 변수 제외
london_mod1 <- subset(london_mod1, select = -c(neighbourhood_cleansed))
#make binary dependent variable (price_bin)
london_mod1$price_bin <- ifelse(london_mod1$price > median(london_mod1$price, na.rm = TRUE), 1, 0)
#fit model
london_logit <- glm(price_bin ~ .-price, family=binomial(link="logit"), data = london_mod1)
summary(london_logit)
#result
stargazer(london_logit, type="html", title="Logistic Regression", out="Logistic Regression.doc")
#pseudo R square
library(pscl)
pR2(london_logit)📚6. Conclusion
✅ 6.1 Implication
1) 숙소의 지리적 위치 및 임대료는 가격 선정에 큰 영향을 미친다. 따라서 호스트는 숙소의 가격 책정 시, 인근에 등록된 Airbnb 숙소 뿐만 아니라 인근 일반 숙소들의 렌트 가격도 고려하여 합리적으로 가격을 선정해야 한다.
2) 호스트는 숙소를 대여할 때, 대여 형태를 고려하여 가격을 책정해야 한다. 집 전체를 대여하는 것에 비해서 숙소 내의 방을 제공하거나 공용으로 사용하는 경우 가격을 낮게 책정해야 한다.
3) 숙소의 수용 인원을 고려한 가격 책정이 필요하다. 또한, 숙소 내부의 특징 중에서 수용인원과 게스트의 숙박 경험에 직접적인 영향을 미치는 화장실, 침대 개수도 가격 형성에 중요한 요소로 고려해야 한다.
4) 선형 회귀와 로지스틱 회귀의 결과에서 나타난 변수들을 비교했을 때, 대부분의 변수가 비슷하게 유의하다고 나타났지만, 일부 변수는 다르게 나타났다.
✅ 6.2 한계점 및 개선점
1) 시간에 따른 가격 변동
이 가격 예측 모델은 시간에 따른 수요 변화를 반영하지 못한 한계가 있다. 숙박 시설은 성수기 및 비수기 또는 주중 및 주말에 따라 가격 편차가 존재한다. 나아가 코로나 19 상황 등 세계 경제에 큰 타격을 주는 외부 요인이 있는 경우 가격의 변동성이 커지나 현재의 모델은 이를 적절히 반영하지 못하고 있다. 시간에 따른 가격 변동 데이터가 확보되어 패널 데이터 분석을 실시한다면 더 유용하고 신뢰도 높은 모델을 도출할 수 있을 것이다.
2) 게스트의 숙소 후기
게스트는 에어비앤비 숙소를 이용할 의사결정을 할 때 숙소에 대한 후기를 매우 중요하게 고려한다. 숙소의 후기가 좋지 않으면 다른 기준들이 만족되어도 최종 예약으로 이어지지 않는 경우도 발생한다. 따라서 숙소의 후기 개수 뿐만 아니라 숙소의 후기 자체에 담겨있는 정보, 감정 등 또한 가격에 영향을 미칠 수 있다. Airbnb Inside에서는 각 숙소별로 등록된 게스트의 후기를 추출하여 제공하고 있다. 이 데이터를 감성 분석하여 가격에 영향을 미치는 독립변수로 활용하고자 하였으나 데이터의 한계로 오류가 발생하여 회귀 모델에 포함하지 못했다. 성공적으로 진행되었다면 동 변수 또한 가격 예측 모델에 유용하게 활용될 수 있었을 것으로 생각한다.
✅ 6.3 개인적 소감
1) 이전까지는 단순히 머신러닝 알고리즘을 적용하고 결과를 비교분석하는 분석을 주로 했었다면, 이 분석에서는 기본적인 가정, 기초통계량, 결과 해석 등을 엄격하게 진행하였다. 겉멋이 아니라 기본이 중요하다는 것을 점점더 깨닫고 있다.
2) 런던에서 오래 생활한 팀원이 있어서 보다 원활하게 분석을 진행할 수 있었다. 혼자서 데이터를 살펴볼 때, 이해가 안 되어서 해석이 막히는 부분이 많았다. 구글링을 해봐도 한계가 있었다. 그런데 팀원끼리 미팅을 하면서 현지에서 생활을 오래 한 팀원의 배경지식과 내가 분석한 내용을 조합하니 해석이 가능한 부분들이 꽤 있었다. 다시 한 번 도메인의 중요성을 느꼈다.
3) 태블로로 처음 시각화를 진행해봤다. 익숙해지기만 하면 매우 효율적/효과적으로 시각화를 할 수 있을 것 같다. 무료 버전 사용이 한정적이라는 것이 아쉽긴 하다...
📚 Reference
http://insideairbnb.com/get-the-data/
https://data.london.gov.uk/dataset/average-private-rents-borough
'프로젝트 및 공모전' 카테고리의 다른 글
| [공모전] 단계적 군집화를 이용한 온라인학습 플랫폼 이용자 이탈방지 전략 제안 (0) | 2022.08.28 |
|---|---|
| [팀 프로젝트] 온라인 리뷰 토픽모델링을 이용한 스마트폰 브랜드 마케팅 전략 제안 (0) | 2022.08.25 |
| [개인 프로젝트] 영화 관람객 수 예측 모델 (0) | 2022.04.04 |
| 제10회 DB 금융경제 공모전 - 입선 (1) | 2022.01.31 |
| 2019년 서울시 빅데이터 공모전 - 깔끔하게 실패한 첫 공모전 (0) | 2022.01.08 |




댓글