◈ 공모전 개요

• 참여 기간 : 2019.12. ~ 2020. 2
• 팀 구성 : 2명
• 개요 :
첫 공모전에서 제대로 된 분석을 해보지도 못하고 실패하고 나서 절치부심해서 다시 준비한 공모전이다. DB 금융경제 공모전은 크게 두 가지 분야 중 하나를 선택해서 참여할 수 있다. (1) 은행/보험 분야, (2) 증권/자산/금융경제 분야로 나뉘는데, 나는 (2)를 선택했다. 비교적 머신러닝을 접목할 수 있는 흥미로운 주제가 많을 것 같았고 사용가능한 데이터도 더 많을 것이라고 생각했기 때문이다. 함께 참가한 친구는 김씨고 나는 장씨여서, 팀명 김앤장으로 곧바로 참가 신청서를 제출했다.
◈ 진행 과정
✅ 주제 선정 및 데이터 수집
전체 공모전 진행 과정에서 주제 선정과 데이터 수집에 가장 많은 시간을 투자했다. 창의적이면서 동시에기존 틀에서 완전히 벗어나지 않는 분석이 필요하다고 생각했다. 게다가 data availability도 중요하게 고려해야 했다. 처음 참가한 빅데이터 공모전에서 데이터도 못 구하고 영혼까지 털렸었고, 지금은 내부적으로 데이터를 받을 수 있는 source도 존재하지 않았다. 분석의 합리성, 창의성, 데이터 가용성을 동시에 고려하면서 균형 잡힌 주제를 선정하는 과정이 매우 어려웠다.
은행/보험 분야도 인공지능이 활발하게 사용되고 있지만, 개인정보와 특히 밀접하게 관련이 있는 분야라서 학부생이 데이터를 얻기가 쉽지 않았다. 데이터를 얻으려고 이리저리 메일을 보내봤는데 아무 곳에서도 답장을 주지 않았다(지금 생각해보면 아주 당연하다). 은행 상품이나 보험 상품을 제안할 수도 있지만, 단순히 아이디어 제안이 아닌 데이터를 바탕으로 근거 있는 제안을 하는 것이 아니라면 이 공모전에서 내가 얻을 수 있는 것이 많지 않다고 생각했다. 그래서 (2)증권/자산/금융경제 부문으로 방향을 정하고, Kaggle이나 데이콘과 같은 사이트의 데이터를 샅샅이 찾아보기 시작했다.
여러 아이디어 중에서 특히 관심을 가지고 찾았던 분야는 주가 예측과 관련된 분석이었다. 같은 팀인 친구가 꾸준히 투자를 해왔기 때문에 비교적 도메인 지식이 있었고, 무엇보다 가장 흥미가 많이 느껴지는 주제였다. 단순히 수치 데이터로만 주가를 예측하는 것 보다 데이터를 기반으로 창의적인 시도를 하기 위해서 비정형 데이터와 주가와의 관계를 살펴보고자 하였다. 가장 먼저 떠오른 것은 뉴스였지만, 어떤 뉴스를 어떤 방식으로 사용할 것인지 난감했다. 또한 좋은 뉴스가 있으면 시장이 긍정적으로 반응하고, 나쁜 뉴스가 있으면 부정적으로 반응하는 것은 너무나 당연한 결과여서 창의성이 부족하다고 생각했다. 한 달 내내 데이터를 찾고 주제를 수정하면서 골머리를 앓던 중에, Kaggle에서 아래 데이터를 발견했다.
Sun, J. (2016, August). Daily News for Stock Market Prediction, Version 1. Retrieved [Date You Retrieved This Data] from https://www.kaggle.com/aaron7sun/stocknews.
2008년 ~ 2016년까지 Reddit WorldNews Channel 카테고리에서 일별 vote 기준으로 상위 25개 게시글의 제목을 크롤링한 데이터이다. 그리고 이 데이터를 익일 다우존스 지수 등락 여부와 merge해서 사용했다.
✅ 데이터 분석
레딧은 이용자가 직접 컨텐츠를 공유하고 토론할 수 있는 온라인 커뮤니티이며 다양한 하위 카테고리로 구성되어 있다. 아마존 Alexa에서(https://www.alexa.com/topsites) 제공하는 전 세계 웹 사이트 순위(Google, Youtube, Facebook 등 포함)에서 19위를 기록하고 있다. 사용자들의 일별 레딧 사용시간은 평균 6분 40초로, 이는 Facebook, Google, Youtube, Amazon, Baidu 다음으로 많다. 국내에는 익숙하지 않지만 해외에서는 많은 정보의 공유가 이루어지는 활성화된 인터넷 커뮤니티이다(국내의 디시 인사이드와 유사하다).
이 데이터를 통해서 일자별로 상위 25개 뉴스를 파악할 수 있고, 사람들이 중요하게 고려한 뉴스가 무엇인지를 보다 쉽게 파악할 수 있었다. 중요성이 높다는 것은 그만큼 주가에도 영향을 미칠 이벤트일 가능성이 높다는 의미이기도 하다. 게다가 기존 연구에서는 특정 언론사의 뉴스를 사용한 사례가 많았지만, 레딧의 뉴스 게시글은 다양한 언론사의 뉴스 원문이 링크로 연결되어 있다. 따라서 특정 언론사의 뉴스만을 사용해서 분석한 것 보다, 여러 관점과 견해를 편향되지 않게 반영할 수 있다.
또한, 뉴스의 본문이 아니라 제목이나 서론으로 분석하는 방식은 여러 가지 장점이 있다. 선행 연구에서 뉴스 제목을 이용할 경우 뉴스 본문을 사용하는 것 보다 데이터의 노이즈를 감소시킬 수 있고, 중요한 단어를 분석에 효과적으로 반영할 수 있다는 것을 확인했다 (Nassirtoussi et al., 2015). 추가적으로 데이터의 크기 자체가 감소하기 때문에 효율적인 메모리 사용 및 학습시간 감소 효과를 얻을 수 있다.
✔ 분석 프레임워크
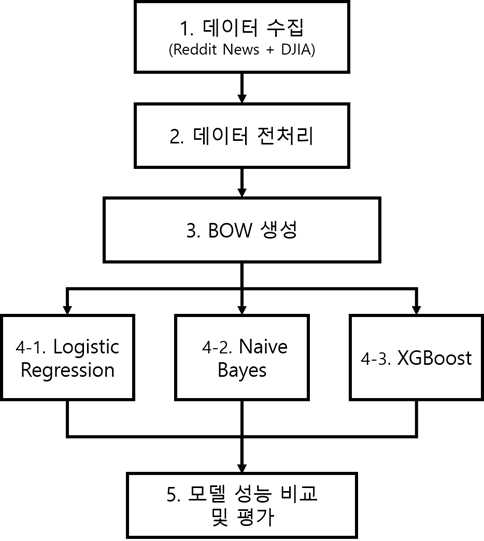
① 데이터 수집
레딧 데이터와 익일 다우존스 지수 데이터를 수집하여 결합했다.
② 데이터 전처리
데이터에 포함되어 있는 불용어를 제거한다. 일반적으로 텍스트 분석 시 불용어로 분류되는 단어들은 영어의 정관사, 부정관사, 숫자 등이 있다. 기본적인 전처리 후에 다우존스 지수 상승/하락 시의 레딧 인기 뉴스의 워드 클라우드를 살펴보면 다음과 같다.
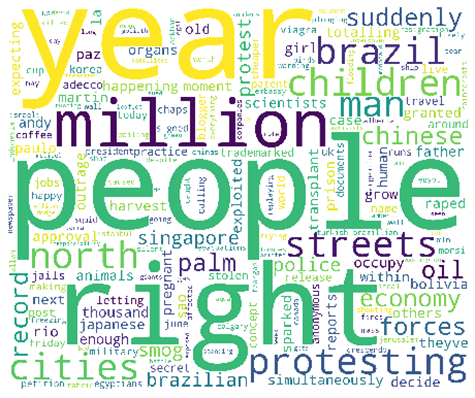

일부 단어들은 직관적으로 받아들여지기도 하지만, 일부 단어들은 추가로 해석이 필요하거나 배경 지식이 필요한 경우가 있음을 알 수 있다.
③ Bag-of-Words 생성
일반적으로 머신러닝 모델의 숫자형 데이터가 입력된다. 이를 위해서 일별 뉴스 제목의 텍스트를 모아서 BOW (Bag Of Words)를 생성한다. BOW는 텍스트를 일종의 봉투(Bag)에 넣는다는 의미로, 뉴스 제목에 등장하는 단어를 모두 한 곳에 모으는 것을 의미한다.
BOW에는 단어들이 단순히 텍스트 집합의 형태로 저장되는 것이 아니라, 각 단어가 하나의 열이 되고, 각 열에 단어별로 등장한 빈도가 계산된다. BOW를 생성하면 텍스트가 수치 값을 가지는 행렬 형태로 변환되고, 이를 통해 머신러닝 모델의 입력 변수로 지정이 가능하게 된다.

위와 같이 단어 행렬로 BOW를 만들기 위해 본 연구에서는 파이썬 라이브러리를 이용하여 ①Count ②TF-IDF(Term Frequency – Inverse Document Frequency) 두 가지 방식을 사용하였다.
Count 방식은 단순히 단어가 등장하는 빈도 수를 카운트한다. 한편, TF-IDF 방식은 개별 문서에서 자주 나타나는 단어에 높은 가중치를 주고, 모든 문서에서 전반적으로 나타나는 단어에 대해서는 패널티를 부여한다. 특정 일자의 뉴스 제목에서 특정 단어가 자주 나타난다는 것은 그 단어가 해당 일자의 사건이나 분위기를 설명하는 중요한 단어임을 의미한다. 한편, 모든 일자에서 공통적으로 자주 나타나는 단어라면 해당 단어는 언어의 특성상 범용적으로 사용되는 단어일 가능성이 높다. 예를 들어, ‘taliban’, ‘uk’, ‘troops’ 등의 단어는 해당 뉴스의 특징을 어느 정도 설명하는 단어라고 볼 수 있지만, ‘all’, ‘talk’, ‘without’ 등의 단어는 해당 뉴스의 특징을 나타내기 보다는 보편적으로 많이 쓰이는 단어이기 때문에 중요성이 떨어진다고 볼 수 있다. 따라서 TF-IDF 방식은 모든 문서에서 반복적으로 자주 나타나는 단어에 패널티를 부여함으로써 BOW 행렬을 구성한다.
일반적으로 Count 방식보다 TF-IDF 방식이 성능이 좋은 경우가 많지만, 사용하는 머신러닝 알고리즘에 따라서 결과가 달라질 수 있기 때문에 Count 방식과 TF-IDF 방식을 모두 이용해서 분석하고 결과를 비교했다.
④ 머신러닝 모델 학습
로지스틱 회귀(Logistic Regression), 나이브 베이즈(Naive Bayes), XGBoost(eXtreme Gradient Boost) 알고리즘을 사용해서 각각 모델을 만들고 성능일 비교했다. 각 모델은 전 단계에서 2가지 방식(Count, TF-IDF) 각각으로 만들어진 BOW를 입력 데이터로 학습한다. 로지스틱 회귀와 나이브 베이즈는 벤치마크 알고리즘으로 사용하기 위해서 선택했다. 또한 캐글과 같은 데이터 사이언스 관련 대회에서 Gradient Boost 기반 알고리즘이 활발하게 사용되고 있다는 점을 발견했다. 알고리즘의 작동 방식을 살펴보았을 때, 우리 데이터에 대해서도 분류 성능이 좋을 것이라고 판단해서 핵심 알고리즘으로 채택했다.
Gradient Boost는 학습 성능은 좋지만 연산시간이 오래 걸린다는 단점이 있다. XGBoost는 이러한 Gradient Boost를 병렬로 연결하여 성능을 향상시키고 학습 시간을 단축시킨 기법이다. 또한 XGBoost는 학습시간이 줄어드는 장점 외에도 과적합(Overfitting)을 방지할 수 있다는 장점이 있다.
모델 학습과정에서는 grid search를 실시에서 파라미터 최적화를 진행했다. 컴퓨팅 파워의 한게가 있었지만, 코랩이랑 로컬 컴퓨터를 이용해서 최적의 파라미터를 찾기 위해서 노력했다.
⑤ 모델 성능 비교 및 평가
BOW를 만드는 두 가지 방식(Count, TF-IDF)과 3가지 머신러닝 모델(로지스틱 회귀, 나이브 베이즈, XGBoost)을 각각 결합하여 총 6개의 결과를 제시하고 최적의 모델의 성능을 비교 및 평가한다.
2008년부터 2014년까지의 데이터(40,275개)를 학습 데이터로 사용하였고, 2015년 이후의 데이터를 테스트 데이터(9,450개)로 사용하여 정확도를 평가하였다.
✅ 분석 결과
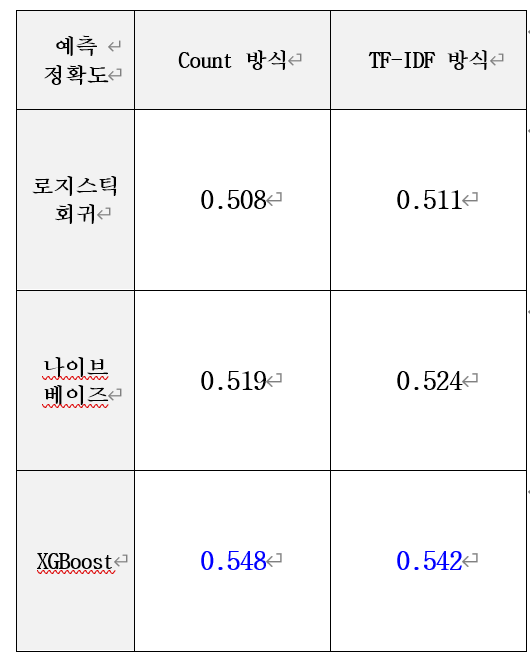
로지스틱 회귀와 나이브 베이즈는 TF-IDF방식이 더 높은 정확도를 보였다. 로지스틱 회귀는 정확도가 50% 근처였으며, 나이브 베이즈는 각각 51.9%와 52.4%로 로지스틱 회귀보다 성능이 좋았다. XGBoost의 경우 Count 방식이 예측 정확도가 높았으며, 각각 정확도 54.8%와 56.3%로 로지스틱 회귀와 나이브 베이즈 보다 높은 뛰어난 성능을 보였다.
절대적인 accuracy 수치가 지나치게 낮았다. 물론 로지스틱, 나이브베이즈 보다 XGB의 정확도가 높긴 하지만, 등락 예측에 정확도 54%는 사실 원숭이가 찍는 것과 크게 다를 바가 없다. 또한, precision, recall, F1 score등 다른 지표들도 골고루 살펴봤어야 모델의 성능을 올바르게 평가할 수 있었을 것이라는 생각도 든다.
✅ 추가 분석
정확도가 낮은 한계점을 보완하기 위해서, 특정한 상황에서 예측을 실시해 보았다. 김상수, 남달우 외(2012)에 따르면 뉴스의 양은 뉴스의 영향력, 거래량과 관련이 있다. 뉴스의 양이 증가하면 매수 매도가 활성화되어 거래량이 증가하는데, 이는 주가에 미치는 뉴스의 영향력이 커진다는 것을 의미한다. 즉, 거래량이 높은 일자를 선별하여 예측을 실시함으로써 주가에 미치는 뉴스의 영향력이 더 큰 상황에서 예측을 실시할 수 있다. 본 연구에서 성능이 가장 좋았던 XGBoost 모델의 정확도를 높이기 위하여 2015년 이후, 거래량을 기준으로 상위 45%에 속하는 일자만을 선별하여 분석을 진행하였다. 분석 과정이나 사용 기법은 모두 동일했으며 결과는 다음과 같다.
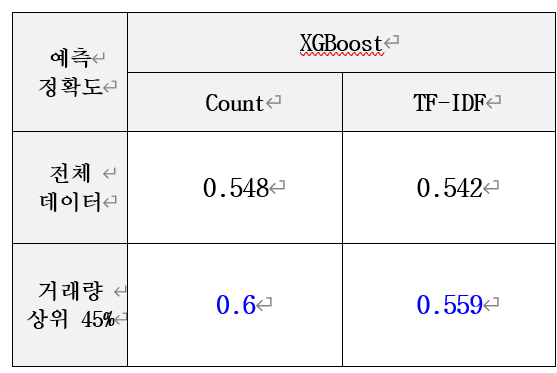
2015년 이후의 전체 데이터를 대상으로 예측한 경우보다 거래량이 많은 일자를 선별하여 분석을 진행하였을 경우, Count 방식의 정확도는 60%로, TF-IDF 방식은55.9%로 상승하였다.
따라서 거래량이 많은 일자에는 뉴스가 주가에 미치는 영향력이 크다는 점을 이용하여 본 연구 모델의 예측 정확도를 높일 수 있었다.
✅ 최종 제출물

✅ 한계점 (★중요)
✔ 제출 당시에 작성한 분석의 한계점
1. 다우존스 지수의 상승 혹은 하락을 이진 분류로만 학습한 것이어서, 실제 시장이 횡보하는 경우 이를 반영하기가 어렵다. 또한 중립적인 의미를 가지는 단어를 모델에 정교하게 반영하기 어렵다.
2. 실제 주가 등락에 영향을 주는 변수가 뉴스 외에도 많기 때문에, 단순히 뉴스 기사만으로 다우존스 지수의 등락을 온전히 설명하는 데에 한계가 있다.
3. 학습하는 데이터의 양이 충분하지 않았고(40,275개), 테스트 데이터의 개수(9,450개) 또한 충분하지 않았다.
✔ 2022년 대학원생 장영진이 평가한 분석의 한계점
5. 주가 등락을 예측하는 것이 과연 의미가 있는가? 최근에는 인공지능으로도 주가를 예측하는 것은(트레이딩이 아님) 사실상 어렵다고 보는 의견도 많이 제기되고 있다. 인간의 비합리성과 예측불가능한 정치,경제적 상황을 정형 데이터로 수치화하여 모델에 반영하기가 너무나 어렵기 때문이다. 게다가 이 분석은 회귀 분석이 아니라 단순 등락 여부 예측이기 때문에 결과의 활용 방안에 대해서도 더 고민이 필요하다.
6. 시계열 분석과 텍스트 분석 결과의 결합이 필요하다. 단순히 레딧의 텍스트로만 주가 등락을 예측하는 것에는 한계가 있다. 애초에 주가는 시계열적 요소가 매우 강하기 때문에 이를 세밀하게 고려해야 한다.
ex) 당일 뉴스가 당일 주가에 영향을 미치는 것인가? 다음 날의 주가에 영향을 미치는 것인가?
당일 뉴스가 당일 주가에 영향을 미치는 것을 실제로 어떻게 반영할 것인가? (구체적인 사용 방법에 대한 고민 부족)
7. 텍스트 데이터는 sequence data라서 순서에 따른 문맥을 반영하는 것이 매우 중요하다. TF-IDF를 사용했다고 하더라도 단순히 단어의 빈도를 사용한 것이기 때문에 해당 뉴스의 문맥을 완전히 반영하지 못한다. 따라서 item2vec, word2vec이나 transfomer 등의 최신 알고리즘을 사용했다면 성능을 대폭 향상시킬 수 있었을 것이다.
◈ 후기

최종적으로 '입선' 을 수상했다. 원래는 장려상이 마지막 이었지만, 우리 분석이 특히 창의성 부분에서 좋은 평가를 받아서 입선 부문을 새로 만들어서 수상할 수 있었다. 사실 공모전 막바지에도 어떻게든 마무리해서 제출하는데에 의의를 두자고 생각하면서 진행했기 때문에 기대가 낮았다. 그럼에도 많은 노력을 들인 공모전에서 이렇게 상을 받을 수 있었다는것이 굉장히 기쁘고 뿌듯했다. 덤으로 상장과 상금까지 받았다



같은 팀인 친구와 거의 2,3달을 매주 만나면서 공모전을 진행했다. 특히 제출 전 마지막 달은 거의 격일 단위로 만나서 카페에서 하루 종일 얼굴 보면서 징글징글하게 있었다. 지금 생각해보면 모르는 게 너무나 많은 상태였지만(물론 지금도 그렇다), 그래도 백지장도 맞들면 조오금은 낫다는 것을 알 수 있었다.
분석의 필요성, 분석의 합리성, 아이디어의 참신성, 데이터 가용성을 모두 고려해서 데이터 분석 관련 프로젝트를 진행하는 것이 얼마나 어려운 과정인지를 체감할 수 있었다. 단점이나 한계점이 많이 보이지만, 그럼에도 데이터 분석과 머신러닝 분야에서 나의 아이디어로 결과물을 만들고 그것이 어느 정도 인정을 받았다는 점에서는 충분한 의의가 있는 공모전이었다.
분석 외적으로도 얻은 것이 많은 공모전이었다. DB김준기 문화재단의 공모전 담당자분과 연락이 닿아서, 당시 회장으로 활동 중이었던 빅데이터 분석 동아리(IBA)에 대해서도 설명을 드렸고 감사하게도 매년 동아리 지원금을 받을 수 있었다. 아직까지도 동아리 후배들은 매년 DB금융경제 공모전에 참가하고 동아리 지원금을 받고 있다. 당시 초기 동아리여서 이런저런 자금난(?)이 많았는데, 매년 꽤 큰 금액을 지원해주셔서 학습 비용으로 아주 유용하게 사용할 수 있었다.
이 공모전을 통해서 데이터 사이언티스트도 마냥 장밋빛 미래가 보장된 것이 아니라는 것을 알 수 있었다. 온갖 언론과 미디어에서 미래의 직업이라고 주목을 하고 있고, 나도 굉장히 '멋있는' 직업이라고 생각했다. 하지만 실제로 제대로 된 분석은 분석가들의 치열한 고민과 노력을 통해서 완성된다는 것을 알 수 있었다. 이 공모전을 통해서 많은 스트레스를 받기도 하고 내가 배워야 할 내용이 한참 남았단느 것을 알 수 있었다. 하지만, 한편으로는 '어렵지만 재미있는 분야 이거다!! ' 라는 생각이 들었다. 분명 내가 아직 부족하지만 그럼에도 앞으로 계속해서 공부해서 나아갈 수 있는 믿음과 확신을 가지게 되는 계기가 되었다.
◈ Reference
R. P. Schumaker, H. Chen, (2010), A Discrete Stock Price Prediction Engine Based on Financial News, IEEE, in Computer vol. 43 no. 1, pp. 51-56.
안성원, 조성배, (2010), 뉴스 텍스트 마이닝과 시계열 분석을 이용한 주가예측, 한국정보과학회 학술발표논문집, 37(1C), pp 364-369.
정지선, 김동성, 김종우, (2015), 온라인상의 뉴스 감성분석을 활용한 개별 주가 예측에 관한 연구, 한국정보과학회 학술발표논문집, 37(1C), pp 364 – 369
왕인내, 신현아, 권혜진, 최예송, (2016), 뉴스와 공시정보에 기반한 주가 변동 예측 시스템, 한국정보과학회 학술발표논문집, pp 1797-1799
Johan Bollen, Huina Mao, Xiao-Jun Zeng, (2011), Twitter mood predicts the stock market, Journal of Computational Science, Volume2 Issue1, pp 1-8
김영민, 정석재, 이석준, (2014), 소셜미디어 감성분석을 통한 주가 등락 예측에 관한 연구, Entrue Journal of Information Technology, Vol13, No3
김동영, 박제원, 최재현, (2014), SNS와 뉴스기사의 감성분석과 기계학습을 이용한 주가예측 모형 비교 연구, Journal of Information Technology Services, pp 221-223
Tobias Preis, Helen Susannah Moat, Eugene Stanley, (2013), Quantifying Trading Behavior in Financial Markets Using Google Trends, Scientific Reports, Rep3
김유신, 김남규, 정승렬, (2012), 소셜 미디어 감성분석을 통한 주가 등락 예측에 관한 연구, Entrue Journal of Information Technology, 제 13권, 3호, pp 59-79
Growth, S. S., J. Muntenmann, (2011), An Intraday Market Risk Management Approach Based on Textual Analysis, Decision Support Systems, Vol. 50, No.4, pp 680-691
Arman Khadjeh Nassirtoussia, Saeed Aghabozorg, The Ying Wah, David Chek Ling Ngo, (2015), Text mining of news-headlines for FOREX market prediction: A Multi-layer Dimension Reduction Algorithm with semantics and sentiment, Expert Systems with Applications, Vol 42, issue 1, pp 306-324
김상수, 남달우, 조현, 김성희, (2012), 웹 뉴스의 양과 주가의 관계에 관한 연구, 한국 IT 서비스학회, 제11권, 제3호, pp 191-203
'프로젝트 및 공모전' 카테고리의 다른 글
| [공모전] 단계적 군집화를 이용한 온라인학습 플랫폼 이용자 이탈방지 전략 제안 (0) | 2022.08.28 |
|---|---|
| [팀 프로젝트] 온라인 리뷰 토픽모델링을 이용한 스마트폰 브랜드 마케팅 전략 제안 (0) | 2022.08.25 |
| [팀 프로젝트] London Airbnb 데이터 분석 및 가격 예측모델 제안 (0) | 2022.05.12 |
| [개인 프로젝트] 영화 관람객 수 예측 모델 (0) | 2022.04.04 |
| 2019년 서울시 빅데이터 공모전 - 깔끔하게 실패한 첫 공모전 (0) | 2022.01.08 |




댓글