📚 분석 개요

• 진행기간 : 2022.03.25 ~ 2022.04.02
• 참여인원 : 개인
• 사용 데이터 : 네이버 영화 정보 및 평점 데이터
• 분석 목적 :
이 분석에서는 국내에서 2005~2018년 기간에 개봉한 영화들의 데이터를 이용해서 관람객 수를 예측하는 모델을 만든다. 전체 분석 및 모델 구축 프로세스는 아래와 같다.
📌 목차
1. 데이터 및 라이브러리 불러오기
2. EDA(데이터 탐색)
2.1 기초통계량 확인
2.2 데이터 시각화
2.3 상관계수 확인
3. 추가 외부변수 수집
4. 데이터 전처리
4.1 결측치 처리
4.2 이상치 처리
4.3 더미변수화
4.4 Train/Test split
4.5 Feature Scaling
5. 모델 학습
6. 모델 성능 평가
📚 1.데이터 및 라이브러리 불러오기
라이브러리와 데이터를 불러온다. 이 분석에서는 네이버에서 영화 관련 정보와 평점 데이터를 사용하였다. matplotlib 사용 시 한글 폰트가 깨지는 문제를 방지하기 위한 설정을 추가한다. 데이터는 1411 x 12 형태로 구성되어 있다.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import sklearn
import warnings
warnings.filterwarnings('ignore')
#한글 폰트 깨짐 방지
import matplotlib
matplotlib.rcParams['font.family'] ='Malgun Gothic'
matplotlib.rcParams['axes.unicode_minus'] =False
#첫번째 열 인덱스로
df = pd.read_excel('dataset_hw1.xlsx',index_col=0)
df.head()
📚 2. EDA(데이터 탐색)
✅ 2.1 기초통계량 확인
데이터의 기본적인 형태와 통계량을 파악한다. 데이터 유형과 변수가 올바른 형태로 입력되었음을 확인하고, 전반적인 기초통계량을 확인한다.
#data type과 변수가 모두 일치함을 확인
df.info()
#기초통계량 확인
df.describe()

✅ 2.2 데이터 시각화
기초 통계량에 대한 정보만으로 데이터를 파악하는 데에는 한계가 있기 때문에 데이터의 세부적인 특성을 파악하기 위해서 데이터 시각화를 실시하였다. 변수의 특성에 따라 범주형 / 연속형 변수를 나눠서 시각화를 진행했다.
✅ 2.2.1 범주형 변수 시각화
barplot을 이용해서 범주형 변수의 분포를 살펴보았다.
#범주형 변수 선택
df_ctg = df[['genre','country','rating','companyNm']]
df_ctg.head()
#한글 폰트 안 깨지도록 설정
matplotlib.rcParams['font.family'] ='Malgun Gothic'
matplotlib.rcParams['axes.unicode_minus'] =False
#seaborn의 countplot 사용
for col in df_ctg.columns:
plt.figure(figsize=(20,10))
sns.countplot(data = df_ctg, x=col)
#sns.barplot(df_ctg.loc[df_ctg[col].notnull(), col])
plt.title(col, fontsize=20)
plt.xlabel(col, fontsize=15)
plt.ylabel('Count', fontsize=20)
plt.show()
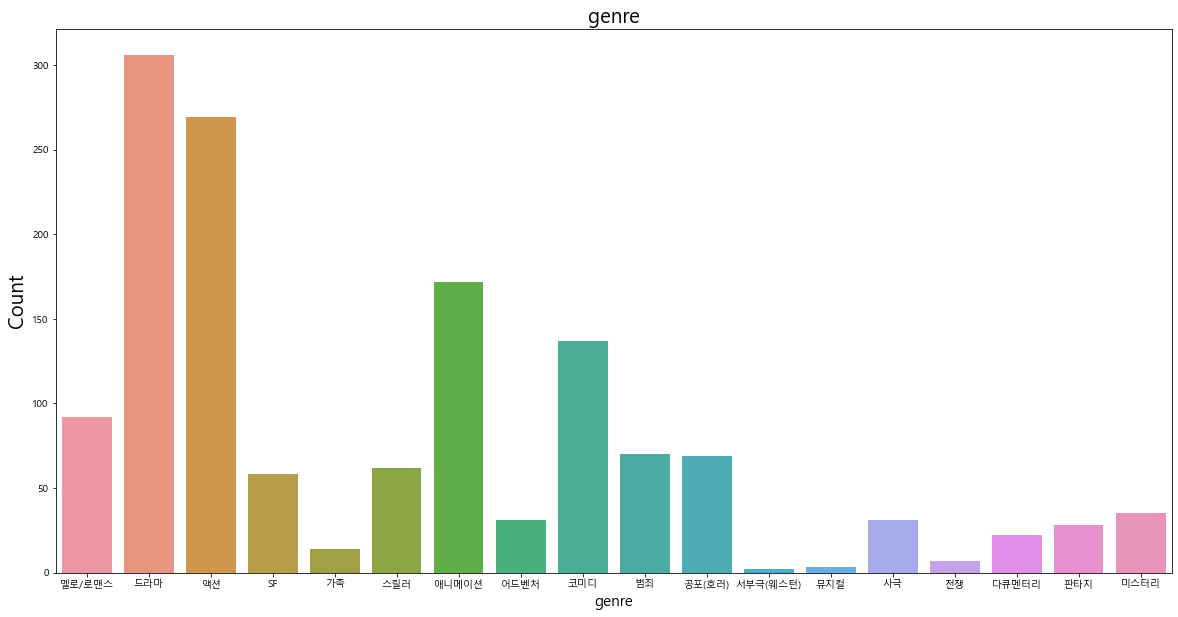
장르(genre)변수의 분포를 살펴보았을 때, '드라마','액션','애니메이션','코미디' 등 보편적으로 접근성이 높은 영화가 많다는 것을 확인할 수 있다.
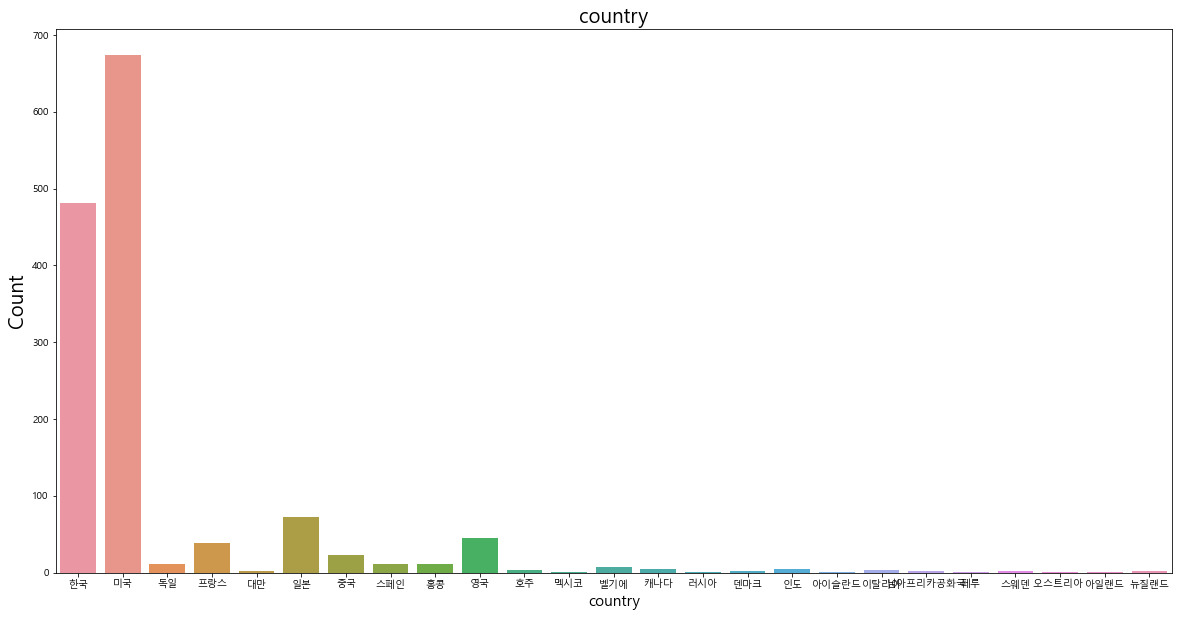
영화 제작 국가(country) 변수에서는 '한국', '미국'의 비중이 압도적으로 높게 나타났고, 그 다음으로 '일본', '영국' 순위임을 알 수 있다. 따른 국가의 영화들은 상대적으로 비중이 매우 낮기 때문에 country 변수를 모델에 학습할 때 이러한 부분을 고려해야 한다.
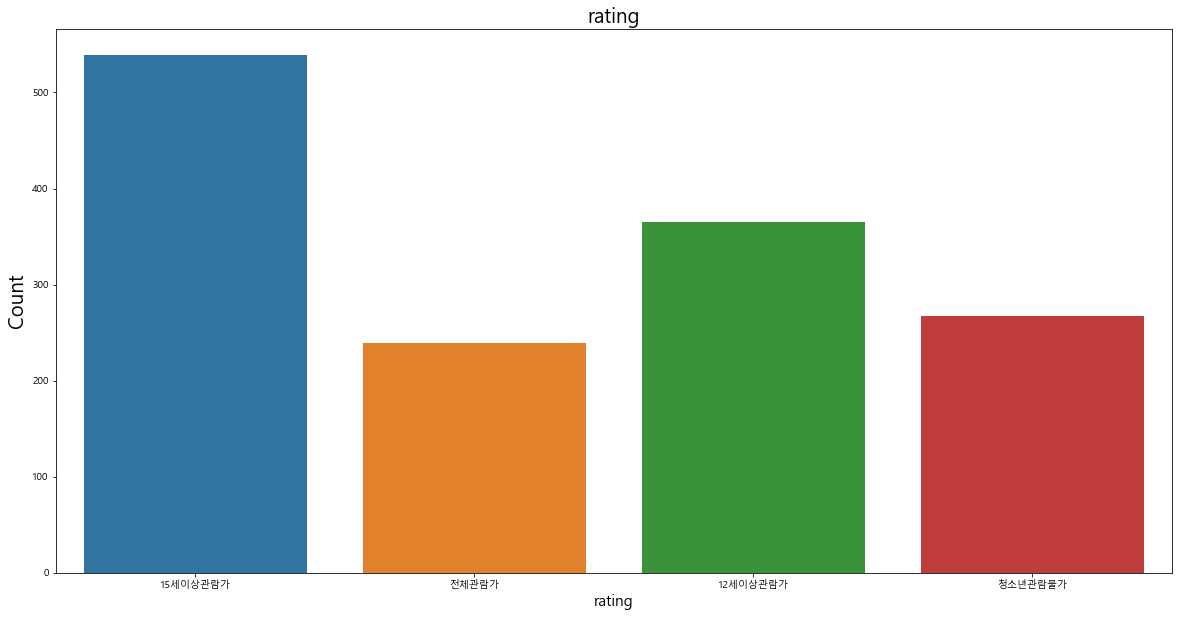
관람객 등급 분포에서는 상대적으로 '15세이상관람가', '12세이상관람가' 분포가 많은 것을 확인할 수 있다.
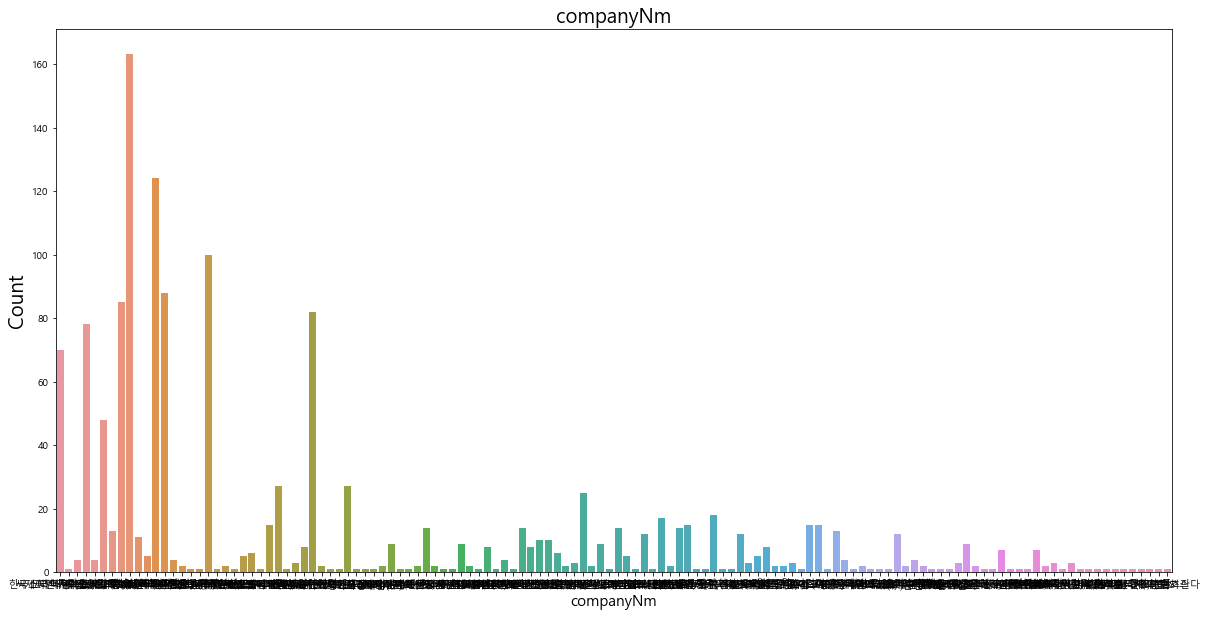
배급사 변수(companyNm)의 경우 배급사가 매우 다양하지만, 등장 빈도의 분포는 일부 배급사에 집중되어 있다는 것을 알 수 있다.
추가적으로 각 범주형 변수와 관람객 수의 관계를 boxplot으로 확인하였다.
#한글 폰트 안 깨지도록 설정
matplotlib.rcParams['font.family'] ='Malgun Gothic'
matplotlib.rcParams['axes.unicode_minus'] =False
#범주형 변수 선택 (종속변수 포함)
df_ctg2 = df[['genre','country','rating','companyNm','num_viewers']]
df_ctg2.head()
#seaborn의 countplot 사용
for col in df_ctg.columns:
plt.figure(figsize=(20,10))
sns.boxplot(x=col, y='num_viewers', data=df_ctg2)
plt.title(col, fontsize=20)
plt.xlabel(col, fontsize=15)
plt.ylabel('관람객 수', fontsize=20)
plt.show()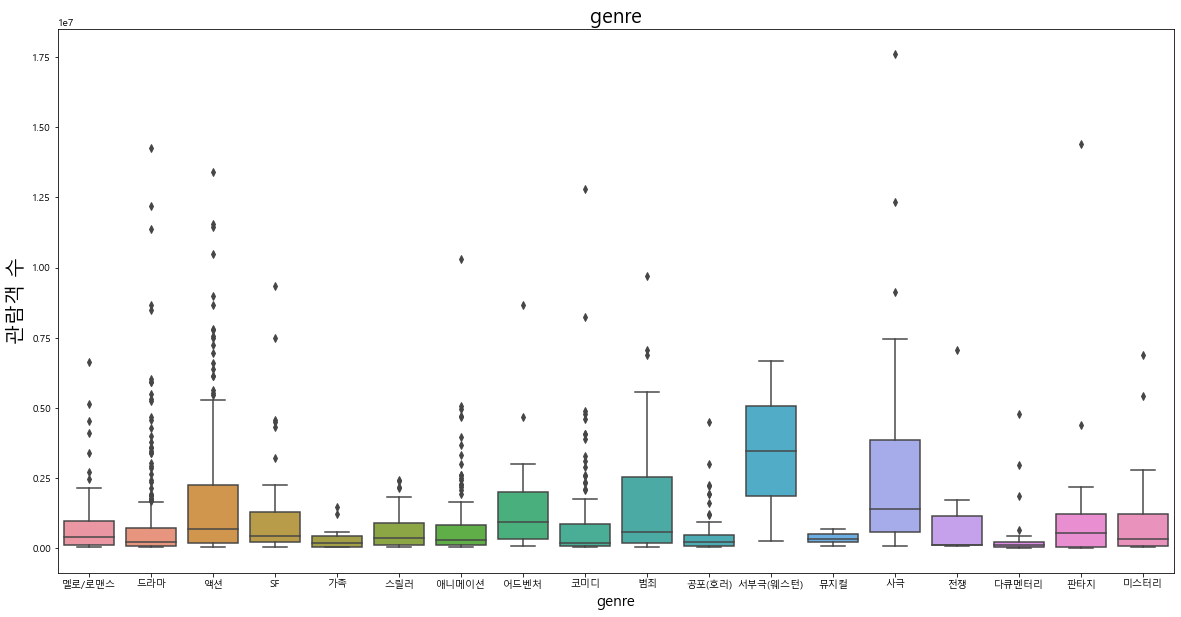
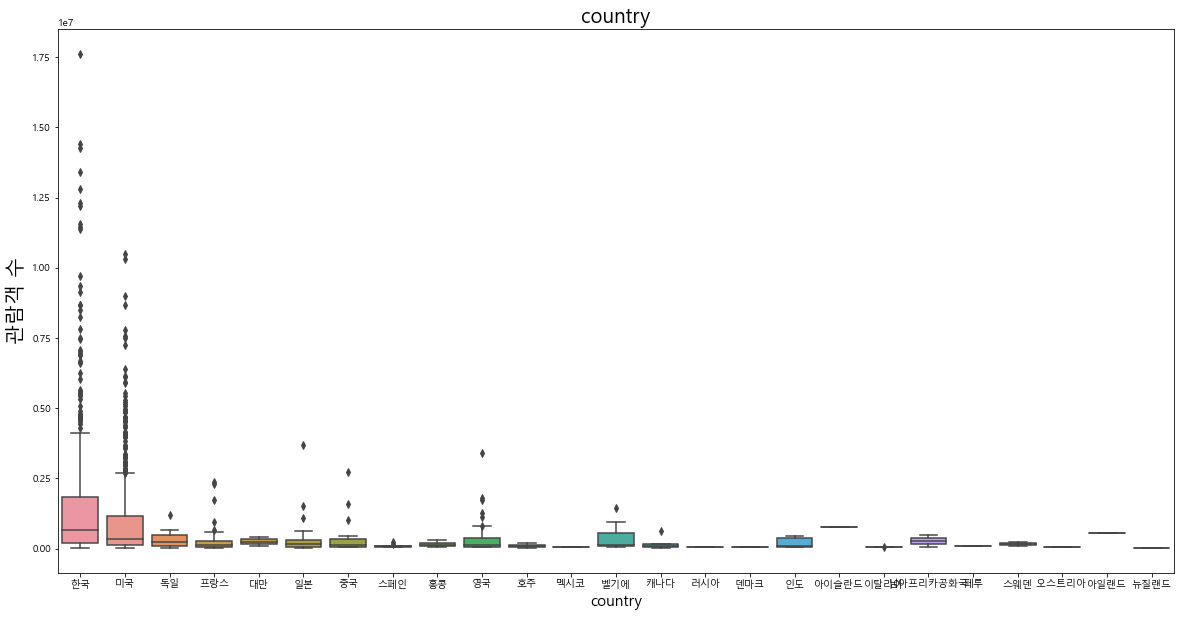
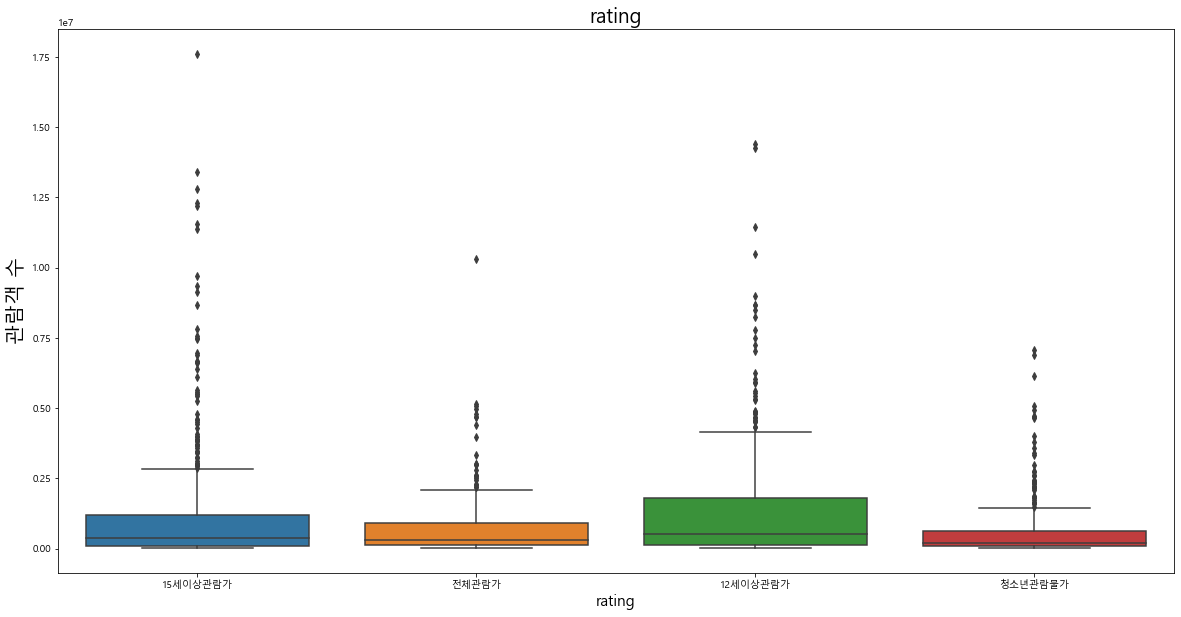
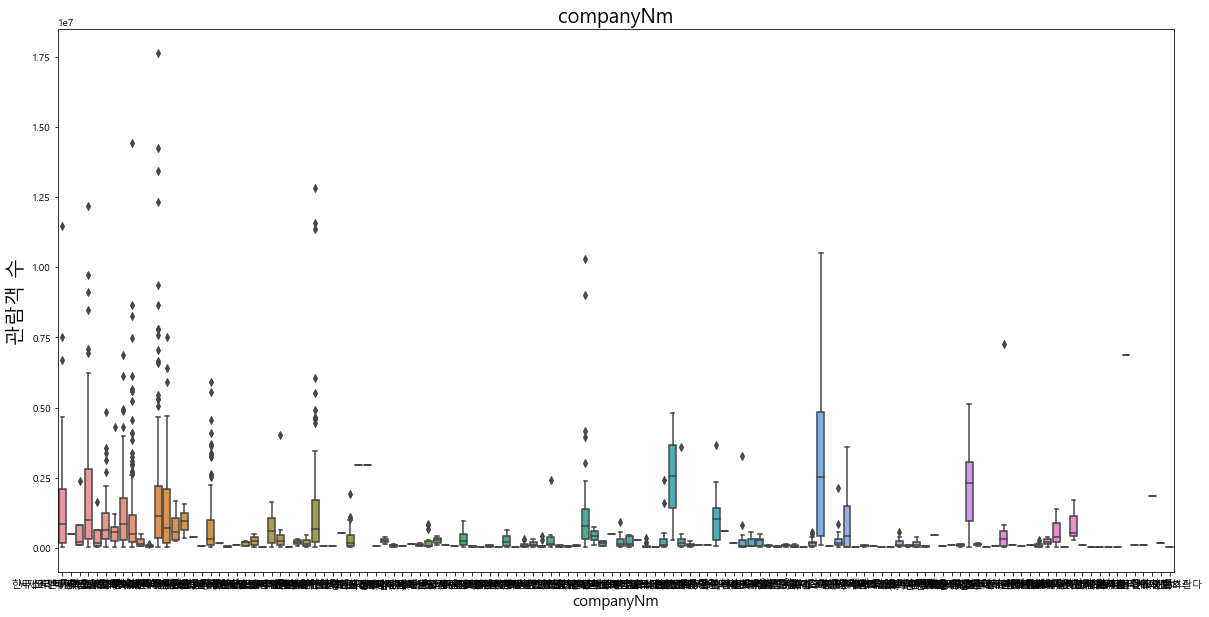
각 범주형 변수와 관람객 수 사이의 이상치를 파악해 보았을 때 단순 시각화 결과만으로 패턴을 파악하기는 어려웠다. 단, 전반적으로 다양한 항목에 걸쳐서 흥행한 영화가 분포해 있음을 알 수 있다.
✅ 2.2.2 연속형 변수 시각화
#연속형 변수 선택
df_con = df[['running_time','netizen_ratings','num_reviews','num_article','released_year','released_month']]
df_con.head()
#seaborn의 distplot 사용
for col in df_con.columns:
plt.figure(figsize=(8,4))
sns.distplot(df_con.loc[df_con[col].notnull(), col])
#plt.title(col, fontsize=20)
plt.xlabel(col, fontsize=15)
plt.ylabel('Density', fontsize=15)
plt.show()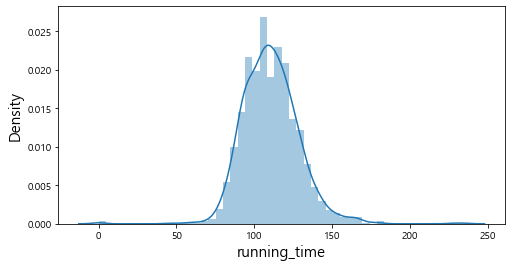
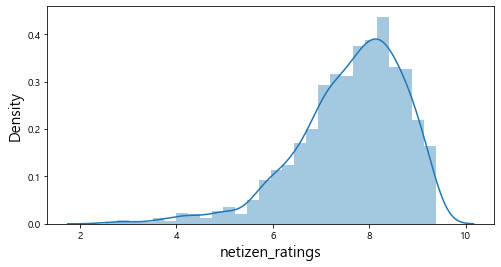
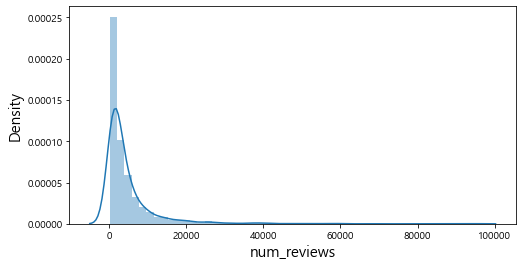
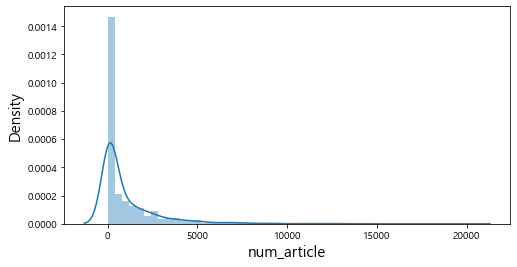
히스토그램으로 연속형 변수들의 전반적인 분포를 살펴보았다. num_reviews, num_article 같은 변수의 경우 상대적으로 분포가 불균형 함을 알 수 있다. 또한, 대부분의 영화에 대한 리뷰가 20,000건 이하이고 기사의 수도 5,000건 이하인 것을 확인할 수 있다.
#연속형 변수 선택 (종속변수 포함)
df_con2 = df[['running_time','netizen_ratings','num_reviews','num_article','released_year','released_month','num_viewers']]
df_con2.head()
#seaborn의 distplot 사용
for col in df_con.columns:
plt.figure(figsize=(8,4))
#sns.distplot(df_con2.loc[df_con2[col].notnull(), col])
sns.scatterplot(x=col, y='num_viewers', data=df_con2)
#plt.title(col, fontsize=20)
plt.xlabel(col, fontsize=15)
plt.ylabel('num_reviews', fontsize=15)
plt.show()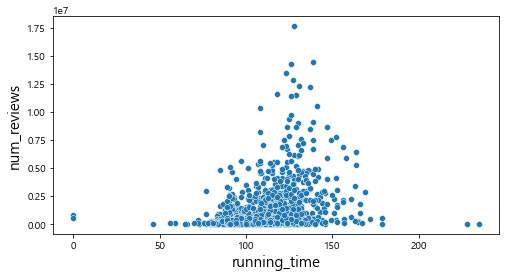
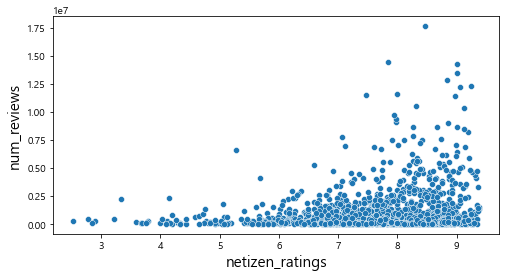
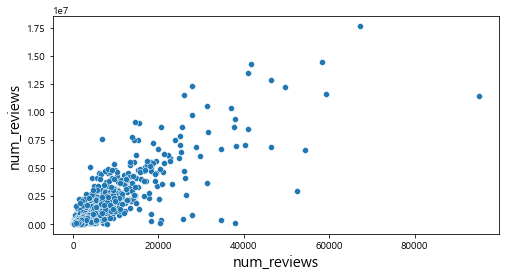
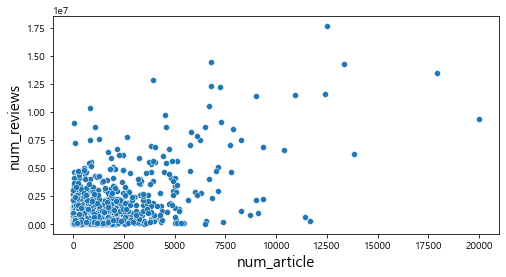
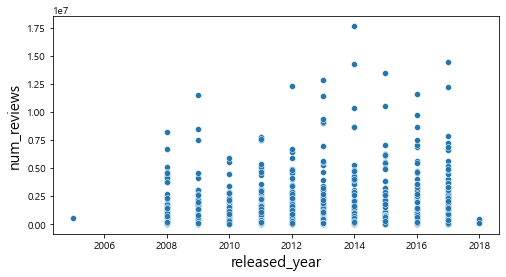
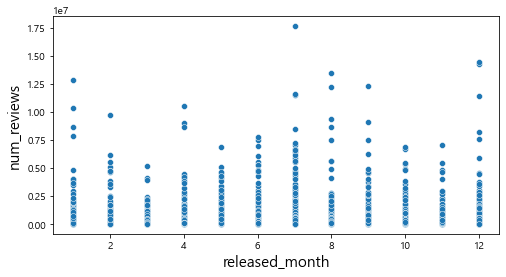
산점도를 통해서 관람객 수와의 관계를 살펴보았을 때, num_reviews, num_article변수와는 어느 정도 선형적인 관계를 파악할 수 있었다. 하지만 그 외의 변수에서는 특정한 패턴이 존재하지 않는다는 것을 확인할 수 있다.
✅ 2.3 상관계수(correlation) 확인
df_corr=df.iloc[:,2:].drop(['country','rating','companyNm'], axis =1)
df_corr.head()
colormap = plt.cm.PuBu
plt.figure(figsize=(10, 8))
sns.heatmap(df_corr.astype(float).corr(), linewidths = 0.1, vmax = 1.0, square = True, cmap = colormap, linecolor = "white", annot = True, annot_kws = {"size" : 16})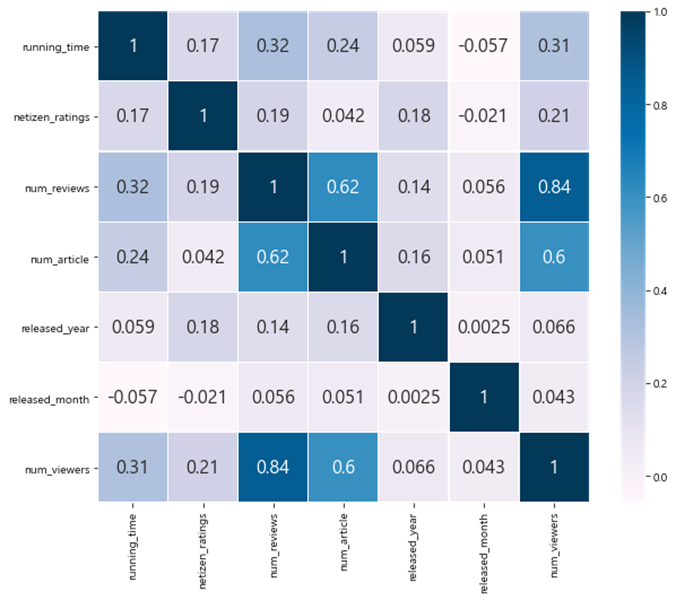
각 변수들의 상관계수를 살펴봤을 때, scatterplot의 결과와 유사하게 num_reviews, num_article 변수가 종 속변수인 num_viewers와 상관계수가 높다는 것을 확인할 수 있다.
📚 3. 추가 외부변수 수집
앞서 상관계수를 살펴보았을 때 종속변수와 상관계수가 높은 변수가 부족하다는 것을 알 수 있다. 따라서 회귀 모델의 예측 성능 향상을 위해서 추가 외부 변수를 수집하였다. 수집 대상 변수는 영화의 ‘스크린 수’ 변수이다. 데이터는 KOBIS(영화관 입장권 통합전산망) 데이터베이스에서 2005~2018 기간의 '스크린 수' 데이터를 다운받아서 사용하였다.
#영화관 스크린 데이터 불러오기
df_screen = pd.read_excel('KOBIS_screen.xlsx')
df_screen.head()
#불필요한 변수 삭제
df_screen = df_screen.drop(['director','companyNm','date'], axis=1)
#movie title 기준으로 merge
df_merged = pd.merge(df, df_screen, how='left', on = 'title')
df_merged.shape새로 수집한 데이터프레임에서 불필요한 변수를 삭제하고 ‘영화 제목’을 기준으로 기존 데이터와 merge를 진행하였다. 스크린 수에 대한 정보가 없는 영화는 추후 전처리 과정에서 중위수로 대체하여 사용하였다.
#시각화 : 종속변수와의 관계 파악
plt.figure(figsize=(8,4))
sns.scatterplot(x='num_screen',y='num_viewers', data=df_merged)
plt.xlabel('num_screen', fontsize=15)
plt.ylabel('num_viewers', fontsize=15)
plt.show()
#상관관계 확인 : 기존 변수에 비해서 상당히 높음
df_merged['num_viewers'].corr(df_merged['num_screen'])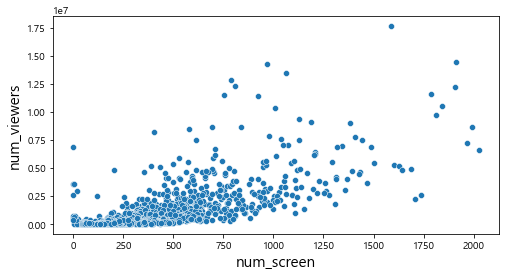
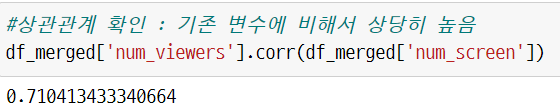
종속변수와의 산점도에서 유의미한 패턴을 확인할 수 있었고, 상관계수도 0.71로 높게 나타났다.
📚 4. 데이터 전처리
모델 학습에 앞서 데이터 전처리를 진행하였다. 결측치 처리, 이상치 처리, 더미변수화, 학습/테스트 데이터 분리 순서로 전처리를 진행하였다.
✅ 4.1 결측치 처리
#결측치 파악
df_merged.isnull().sum().to_frame('nan')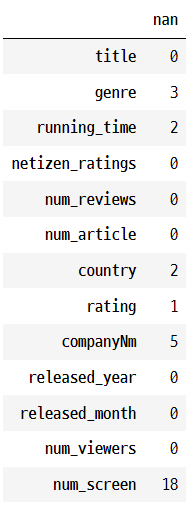
일부 변수에 존재하는 결측치 처리를 진행하였다. 일반적으로 데이터가 큰 경우에는 결측치가 존재하는 데이터 샘플을 삭제하는 것이 효과적일 수 있다. 하지만, 이 분석에서 주어진 데이터셋은 샘플 수가 많지 않기 때문에 단순히 해당 행을 삭제하기 보다 최대한 정보를 보완하는 것이 학습에 효과적이라고 판단했다. 따라서, genre, running_time, country, rating 변수에 존재하는 결측치의 경우 데이터 수집과정에서 오류가 있었다고 판단하여 KOBIS (영화관 입장권 통합전산망)에서 해당 영화에 대한 정보를 찾아서 분석자가 직접 결측치 데이터의 값을 수정하였다
📌genre 변수
df_merged[df_merged['genre'].isnull()]
df_merged.loc[1364,'genre'] = '액션'
df_merged.loc[1370,'genre'] = '애니메이션'
df_merged.loc[1371,'genre'] = '스릴러'
📌running_time 변수
df_merged[df_merged['running_time'].isnull()]
df_merged.loc[1372,'running_time'] = 118
df_merged.loc[1385,'running_time'] = 109
📌country 변수
df_merged[df_merged['country'].isnull()]
df_merged.loc[1385,'country'] = '미국'
df_merged.loc[1403,'country'] = '프랑스'
📌rating 변수
df_merged[df_merged['rating'].isnull()]
df_merged.loc[1424,'rating'] = '15세이상관람가'
📌companyNm 변수
df_merged[df_merged['companyNm'].isnull()]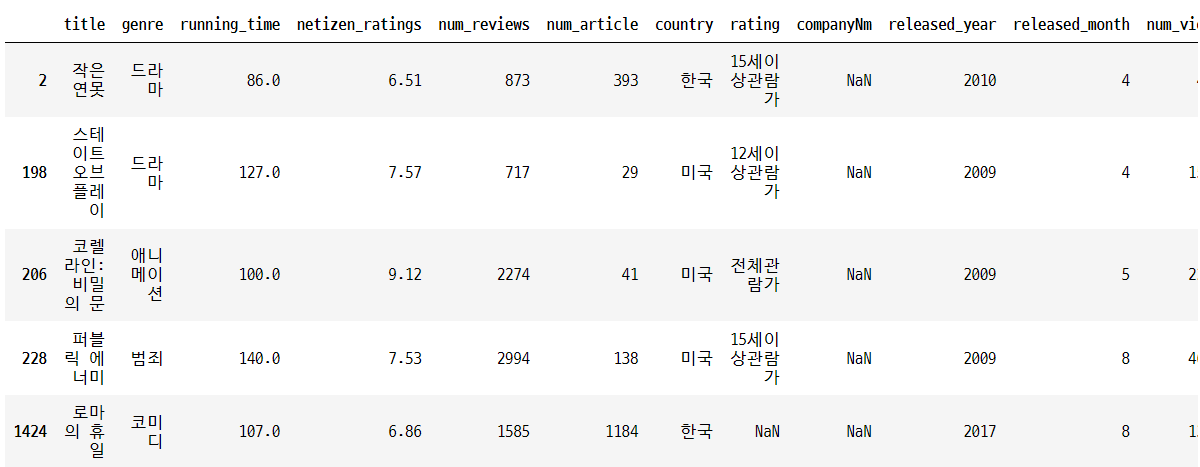
#companyNm 변수는 이후 모델 학습 과정에서 상위 등장빈도 7개만 사용하기 때문에 '없음'으로 표기
df_merged.loc[2,'companyNm'] = '없음'
df_merged.loc[198,'companyNm'] = '없음'
df_merged.loc[206,'companyNm'] = '없음'
df_merged.loc[228,'companyNm'] = '없음'
df_merged.loc[1424,'companyNm'] = '없음'companyNm 변수는 결측치를 ‘없음’ 이라는 텍스트로 대체하였고, 이 값은 최종적으로 모델 학습에 사용하지 않았다. 이에 대해서는 4.3 더미변수화 부분에 추가 설명을 작성하였다.
📌num_screen 변수
#중위수로 변경
df_merged.fillna(df_merged['num_screen'].median(), inplace = True)num_screen(상영관 수) 변수의 경우 새로 수집한 데이터셋과 기존 데이터셋을 매칭했을 때 18개의 결측치가 발견되었다. 이 결측치들은 추가 정보를 찾을 수 없었기 때문에 중위수로 대체하여 사용하였다.
#결측치 제거 확인
df_merged.isnull().sum().to_frame('nan')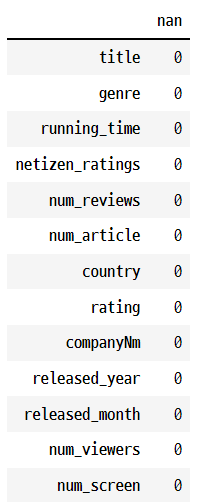
✅ 4.2 이상치 처리
pd.set_option('display.float_format', lambda x: '%.3f' % x)
#box plot 확인
plt.figure(figsize = (15,8))
sns.boxplot(x = "num_viewers", orient = "v", data = df_merged)
plt.show()
df_merged['num_viewers'].describe()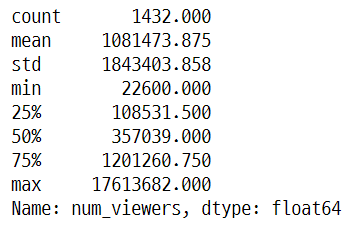
#1천3백만 이상 관객 유치한 영화 확인
df_merged[df_merged['num_viewers'] > 13000000]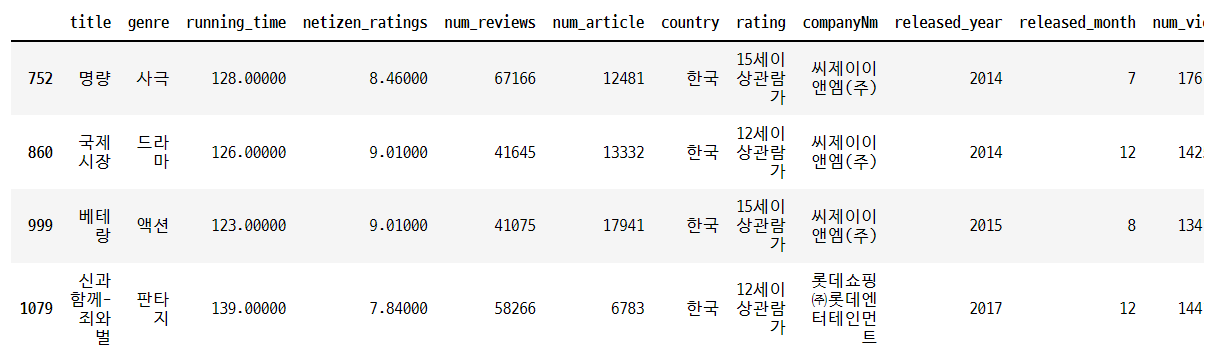
종속변수인 num_viewers에 대한 boxplot에서 이상치로 판단할 수 있는 샘플이 다수 존재한다는 것을 확인할 수 있다. 일반적인 IQR 기준 이상치 제거 방식으로는 정보 손실이 많이 발생하게 된다. 또한, 사전에 큰 흥행을 할 수 있는 영화를 예측하는 것도 중요하기 때문에, 이상치 그 자체로도 중요한 정보를 포함하고 있다고 볼 수 있다. 따라서 이 분석에서는 분석자의 판단에 따라서 1천 3백만 이상의 관람객을 동원한 영화만을 이상치로 보고 제외하였다.
✅ 4.3 더미변수화
#data type 별로 변수 따로 처리
#범주형 변수만 선택
df_ctg = df_merged[['genre','country','rating','companyNm']]
#연속형 변수만 선택
df_con = df_merged[['running_time','netizen_ratings','num_reviews','num_article','released_year','released_month','num_screen']]
#종속변수 선택
df_target = df_merged['num_viewers']genre, country, rating, companyNm 변수는 범주형 변수이기 때문에 더미 변수화를 실시하였다. 단, 모든 변수와 값에 대해서 더미변수를 생성한 것이 아니라 분석자의 판단에 따라 유의미한 변수만 선별하여 더미 변수로 생성하였다. 각 변수별 구체적인 처리 방식은 다음과 같다.
📌 genre

장르 변수의 경우 등장 빈도가 50회 이하인 ['미스터리','어드벤처','사극','판타지','다큐멘터리','가족','전쟁','뮤지컬','서부극(웨스턴)'] 장르인 경우 값을 ‘etc’로 변경하였다. 그리고 pandas의 pd.get_dummies 함수를 이용해서 더미 변수를 생성하고, ‘etc’에 해당하는 더미 변수는 삭제해서 해석 과정에서 기준이 되는 변수로 사용했다. 최종적으로 아래 변수에서 etc 변수를 제외한 장르들에 대한 더미 변수가 사용되었다.
etc_genre = ['미스터리','어드벤처','사극','판타지','다큐멘터리','가족','전쟁','뮤지컬','서부극(웨스턴)']
for i in range(len(df_ctg)):
#print(df_ctg.index[i])
if df_ctg.iloc[i,0] in etc_genre:
df_ctg.iloc[i,0] = 'etc'
else:
pass
'''
df_ctg.loc[df_ctg['genre'] =='전쟁', 'genre'] = 'etc'
df_ctg.loc[df_ctg['genre'] =='뮤지컬', 'genre'] = 'etc'
df_ctg.loc[df_ctg['genre'] =='서부극(웨스턴)', 'genre'] = 'etc'
''''''
#더미변수 생성
cat_tmp_1 = pd.get_dummies(df_ctg['genre']).drop('etc', axis=1) #etc 변수를 기준으로 사용하기 위해서 삭제
cat_tmp_1.head()
📌 rating
관람 등급 변수의 경우 모두 더미변수로 만들어서 학습에 사용하였다. 모델 학습 후 더미변수 해석을 위해서 '19세 이상 관람가'를 기준 열로 사용하기 위해서 삭제하였다.
cat_tmp_2 = pd.get_dummies(df_ctg['rating']).drop('청소년관람불가', axis=1) #청소년관람불가 값을 기준으로 사용하기 위해서 삭제
cat_tmp_2.head()
cat_tmp_2 = pd.get_dummies(df_ctg['rating']).drop('청소년관람불가', axis=1) #청소년관람불가 값을 기준으로 사용하기 위해서 삭제
cat_tmp_2.head()
📌 country
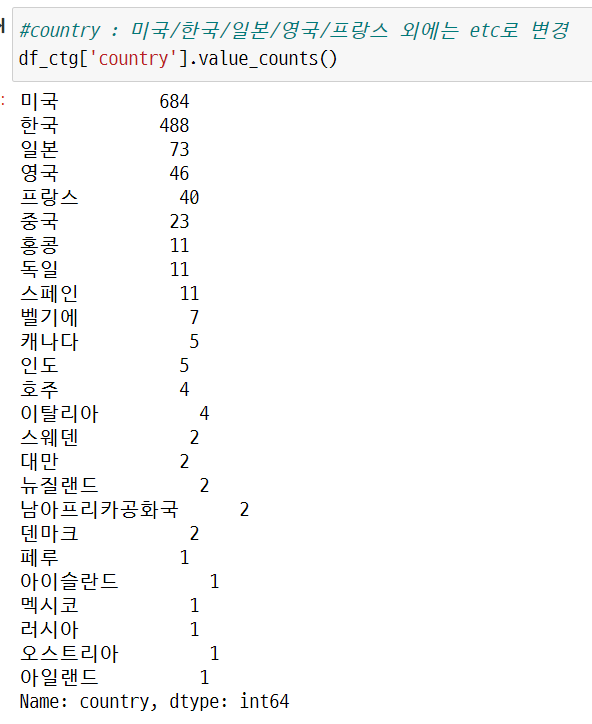
앞선 EDA 결과에서도 알 수 있듯이 대부분의 영화가 미국, 한국, 중국, 일본 영화이다. 따라서 genre 변수와 동일하게 해당 국가들을 제외한 모든 국가들의 값을 ‘etc’로 변경하고, 미국/한국/중국/일본에 대한 더미 변수만 생성하여 학습에 사용하였다.
etc_country = ['미국','한국','일본','영국','프랑스']
for i in range(len(df_ctg)):
#print(df_ctg.index[i])
if df_ctg.iloc[i,1] in etc_country:
pass
else:
df_ctg.iloc[i,1] = 'etc'
cat_tmp_3 = pd.get_dummies(df_ctg['country']).drop('etc', axis=1) #etc 값을 기준으로 사용하기 위해서 삭제
cat_tmp_3.head()
📌 compayNm(배급사 정보)

일반적으로 관람객들이 영화 관람 시에 배급사를 고려하지 않기 때문에, 배급사는 관람 의사결정에 영향을 미치는 결정적인 요소라고 보기 어렵다. 또한 이 변수는 값이 다양하기 때문에 학습을 위해서 더미변수화를 진행할 경우 feature가 지나치게 많아져서 모델이 복잡해질 수 있다. 따라서, 등장 빈도를 기준으로 상위 7개 배급사만 더미 변수로 생성하여 사용하였다. 결측치 처리 단계에서 companyNm변수에 결측치가 존재하는 경우 값을 ‘없음’으로 대체하였는데, 이 샘플들은 companyNm 더미변수들에 대한 값이 모두 0인 상태로 학습된다. 배급사 정보는 스크린의 상영관 수, 마케팅 방식 등 영화 외적인 요소와 관련이 있기 때문에, 관람객 수에 간접적인 영향을 미칠 수 있다.
etc_company = ['씨제이이앤엠(주)','유니버설픽쳐스인터내셔널 코리아(유)','워너브러더스 코리아(주)','이십세기폭스코리아(주)',
'(주)넥스트엔터테인먼트월드(NEW)','(주)쇼박스','씨제이엔터테인먼트']
for i in range(len(df_ctg)):
#print(df_ctg.index[i])
if df_ctg.iloc[i,3] in etc_company:
pass
else:
df_ctg.iloc[i,3] = 'etc'
cat_tmp_4 = pd.get_dummies(df_ctg['companyNm']).drop('etc', axis=1) #etc 값을 기준으로 사용하기 위해서 삭제
cat_tmp_4.head()
📌더미 데이터프레임 결합
print(cat_tmp_1.shape)
print(cat_tmp_2.shape)
print(cat_tmp_3.shape)
print(cat_tmp_4.shape)
df_cat_new = pd.concat([cat_tmp_1, cat_tmp_2, cat_tmp_3, cat_tmp_4], axis=1)
print(df_cat_new.shape)
df_cat_new.head()
각 변수에 대한 더미변수를 생성한 후에, pd.concat을 이용해서 연속형 변수, 종속 변수와 결합해서 다시 하나의 데이터 프레임 형태로 정리하고 이후 전처리 과정을 진행하였다.
#더미변수화를 끝내고 다시 데이터 결합
df_fin = pd.concat([df_cat_new, df_con, df_target], axis=1)
df_fin.head()
✅ 4.4 Train/Test split
from sklearn.model_selection import train_test_split
y = df_fin.iloc[:,-1]
x = df_fin.iloc[:,:-1]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3)
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)모델 학습을 위해서 전체 데이터를 7(학습) : 3(테스트)로 분리하였다. 학습 데이터에는 총 999개의 데이터 샘플이 포함되어 있고, 테스트 셋에는 429개의 샘플이 포함되어 있다. 이후 모델 학습 과정에서 최적 모델을 선정하기 위해서 학습 데이터셋에 대해서 5-fold cross validation을 추가로 진행하였다.
✅ 4.5 Feature Scaling
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x_train_std = scaler.fit_transform(x_train)
x_test_std = scaler.transform(x_test)모델 성능 향상을 위해서 피쳐 스케일링을 실시하였다. 이 분석에서는 Min Max Scaler를 사용해서 모든 변수의 값을 0~1 사이의 범위로 조정하였다.
📚 5. 모델학습
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from numpy import absolute
from numpy import mean
from numpy import std
from sklearn.linear_model import Lasso,ElasticNet,Ridge
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
✅ 5.1 Lasso Regression
model_lasso = Lasso(alpha=0.5) # alpha => regularization strength
model_lasso.fit(x_train, y_train)
model_lasso.score(x_test, y_test) #R2
# Cross validation 실시
cv = RepeatedKFold(n_splits=5, n_repeats=3, random_state=1)
scores = cross_val_score(model_lasso, x_train, y_train, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1)
scores = absolute(scores)
print('Mean MAE: %.3f (%.3f)' % (mean(scores), std(scores)))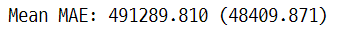
✅ 5.2 Ridge Regression
model_ridge = Ridge(alpha=0.5) # alpha => regularization strength
model_ridge.fit(x_train, y_train)
model_ridge.score(x_test, y_test) #R2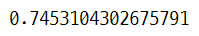
# Cross validation 실시
cv = RepeatedKFold(n_splits=5, n_repeats=3, random_state=1)
# evaluate model
scores = cross_val_score(model_ridge, x_train, y_train, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1)
scores = absolute(scores)
print('Mean MAE: %.3f (%.3f)' % (mean(scores), std(scores)))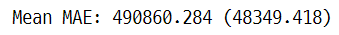
✅ 5.3 ElasticNet
model_elas = ElasticNet()
model_elas.fit(x_train, y_train)
model_ridge.score(x_test, y_test) #R2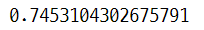
# Cross validation 실시
cv = RepeatedKFold(n_splits=5, n_repeats=3, random_state=1)
scores = cross_val_score(model_elas, x_train, y_train, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1)
scores = absolute(scores)
print('Mean MAE: %.3f (%.3f)' % (mean(scores), std(scores)))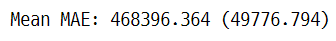
학습하는 피쳐의 수가 30개로 많기 때문에 Lasso, Ridge, ElasticNet을 사용하여 결과를 비교하고 최종 모델을 선택하였다. 사이킷런 라이브러리를 사용하였으며, train/test split 과정에서 데이터 샘플의 특성에 따른 결과의 왜곡을 방지하기 위해서 train set에 대해서 5-fold cross validation을 실시했다. 하이퍼 파라미터 튜닝은 random search 방식으로 분석자가 주어진 범위 내에서 변경해가면서 최적의 값을 탐색하였다.
| 사용 알고리즘 | MAE 평균 |
| Lasso | 491289.810 |
| Ridge | 490860.284 |
| Elasticnet | 468396.364 |
📚 6. 모델 성능 평가
y_pred = model_elas.predict(x_test)
mae_ = mean_absolute_error(y_test, y_pred)
print('MAE = {:.3f}'.format(mae_))
mse_ = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse_)
print('RMSE = {:.3f}'.format(rmse))
결과 학습 데이터에 대해서 elasticnet의 오차가 가정 작게 나타났다. 따라서 최종적으로 elasticnet 알고리즘한 모델을 채택하였으며, 테스트 데이터에 대해서 MAE, RMSE를 확인한 결과는 다음과 같다.

📚 7. 한계점 및 개선방안
① 실제 모델을 활용한다고 하면 사용할 수 없는 변수들이 존재한다. 예를 들어, num_article / num_reviews 등의 변수는 상영이 모두 끝난 후에 수집할 수 있는 변수이기 때문에 사전에 관람객 수를 예측하는 과정에서 사용하기에는 한계가 있다.
② 데이터의 수가 충분하지 않다. 따라서 과적합 오는 과소적합 가능성이 존재한다.
③ 다양한 추가 변수를 사용할 수도 있다. 최근에는 텍스트 데이터와 같이 비정형 데이터가 다방면으로 사용된다.
ex) 리뷰의 감성 지수, 영화의 plot 텍스트 데이터
'프로젝트 및 공모전' 카테고리의 다른 글
| [공모전] 단계적 군집화를 이용한 온라인학습 플랫폼 이용자 이탈방지 전략 제안 (0) | 2022.08.28 |
|---|---|
| [팀 프로젝트] 온라인 리뷰 토픽모델링을 이용한 스마트폰 브랜드 마케팅 전략 제안 (0) | 2022.08.25 |
| [팀 프로젝트] London Airbnb 데이터 분석 및 가격 예측모델 제안 (0) | 2022.05.12 |
| 제10회 DB 금융경제 공모전 - 입선 (1) | 2022.01.31 |
| 2019년 서울시 빅데이터 공모전 - 깔끔하게 실패한 첫 공모전 (0) | 2022.01.08 |




댓글