📚 블록체인 Social Buzz 데이터 분석 및 암호화폐 거래량 예측

📌 프로젝트 개요
| 분석 목적 | - 5개 암호화폐 거래소의 Social Buzz 데이터 분석 - 거래소 Social Buzz 데이터와 암호화폐 거래량의 인과관계 파악 - Social Buzz 데이터를 이용한 암호화폐 거래량 예측 모델 |
| 사용 데이터 | 블록체인 Social Buzz 데이터, 암호화폐 거래 데이터 |
| 분석기간 | 2022.09.01~2022.12.19 |
| 역할 | 모델링, 결과 발표 |
| 사용언어 및 Tool | 태블로(시각화), R, Python |
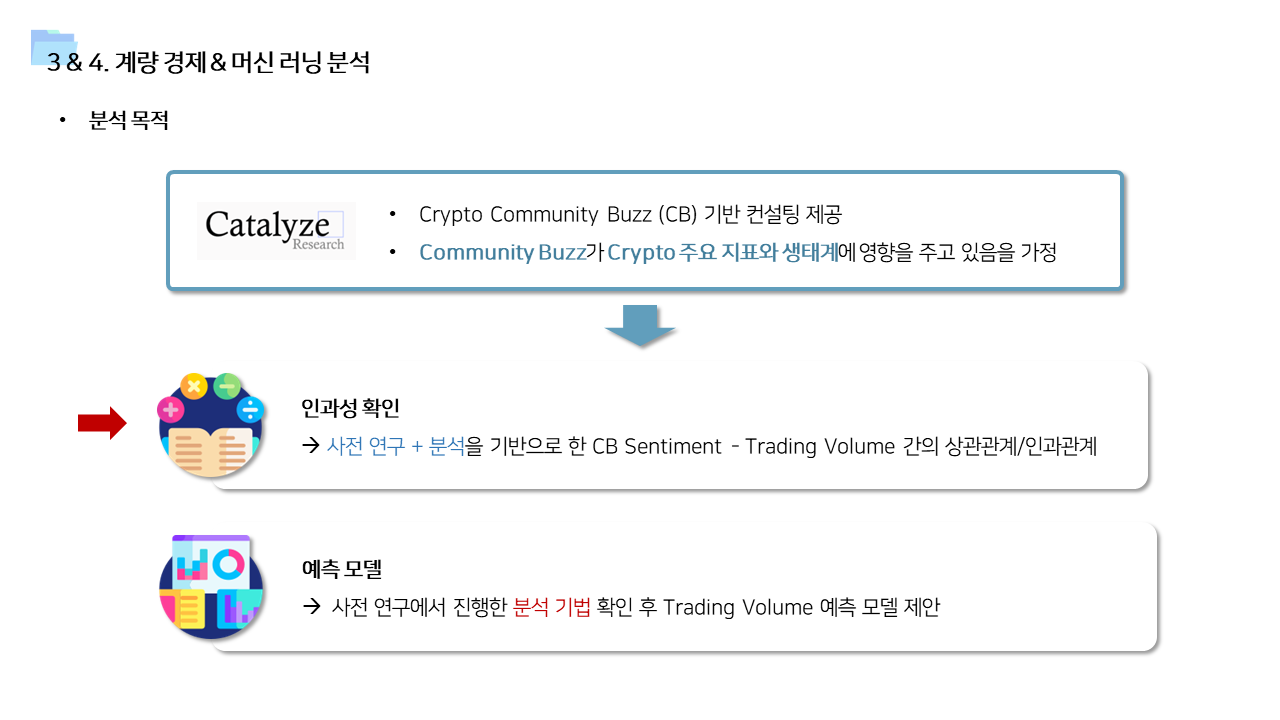
좋은 기회를 얻어서 블록체인 데이터 분석 기업인 카탈라이즈 리서치(Catalyze Research)와의 산학협력 프로젝트를 진행하였다. 카탈라이즈 리서치는 Web3 업계의 회원사들을 대상으로 투자, 컨설팅, 분석 서비스를 제공하는 기업으로, 블록체인과 관련된 전문적인 지식 및 인사이트를 제공하고 있다. 최근에는 리플과 파트너쉽을 체결하고 전략 컨설팅을 수행하고 있다(2023.07.26).
https://catalyze-research.com/
Catalyze Research - Home
Catalyze Research is the trailblazer in Web3 and blockchain consulting, crafting bespoke strategies and delivering valuable insights to help businesses dominate the digital frontier.
catalyze-research.com
프로젝트 수행을 위해서 카탈라이즈 리서치에서 Social Listening 스킬을 기반으로 수집한 거래소별 Social Buzz 데이터를 제공받았다. 사실상 이 데이터 자체가 유니크하고 퀄리티가 좋아서 프로젝트에서 매우 큰 비중을 차지했다고 생각한다. 상당한 수집 스킬과 노하우가 반영된 데이터라는 생각이 들었고, 아마 내가 직접 수집했으면 기간 내에 프로젝트 마무리를 못 했을 것이다.. 덕분에 분석에 집중해서 다양한 시도를 할 수 있었고, 흥미로운 점들을 발견할 수 있었다 (좋은 데이터가 있어서 욕심을 내다보니 분량은 매우 길어졌다...)
분석은 크게 3가지 파트이며 목차의 순서대로 다음과 같이 구성하였다
→ (2) 데이터 분석, (3) 계량경제 분석, (4) 머신러닝 예측


📌 분석 배경 및 기초 설명

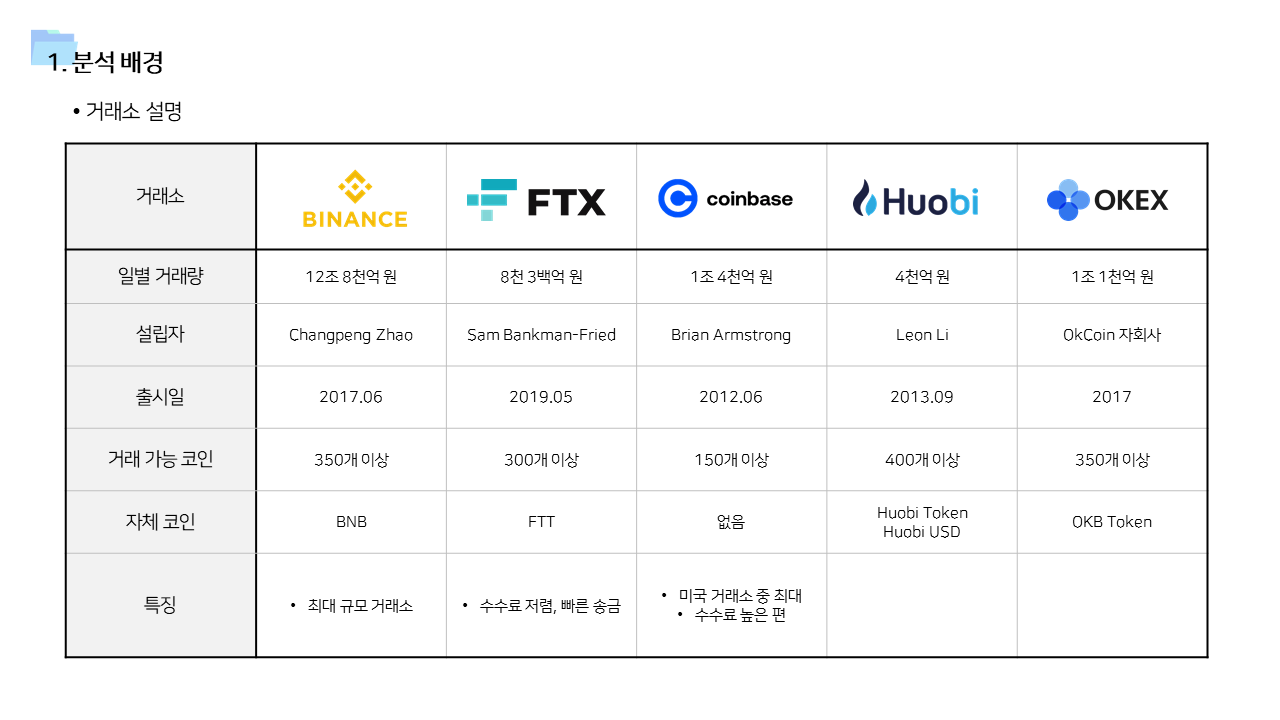
사용 데이터 중 주요 변수는 5개 거래소에 대해서 일별 거래량, 총 멘션, 긍/부정/중립 멘션 변수이다. 여기서 각 mention 변수의 값은 카탈라이즈의 수집 방식 및 로직에 의해서 집계된 값이다.
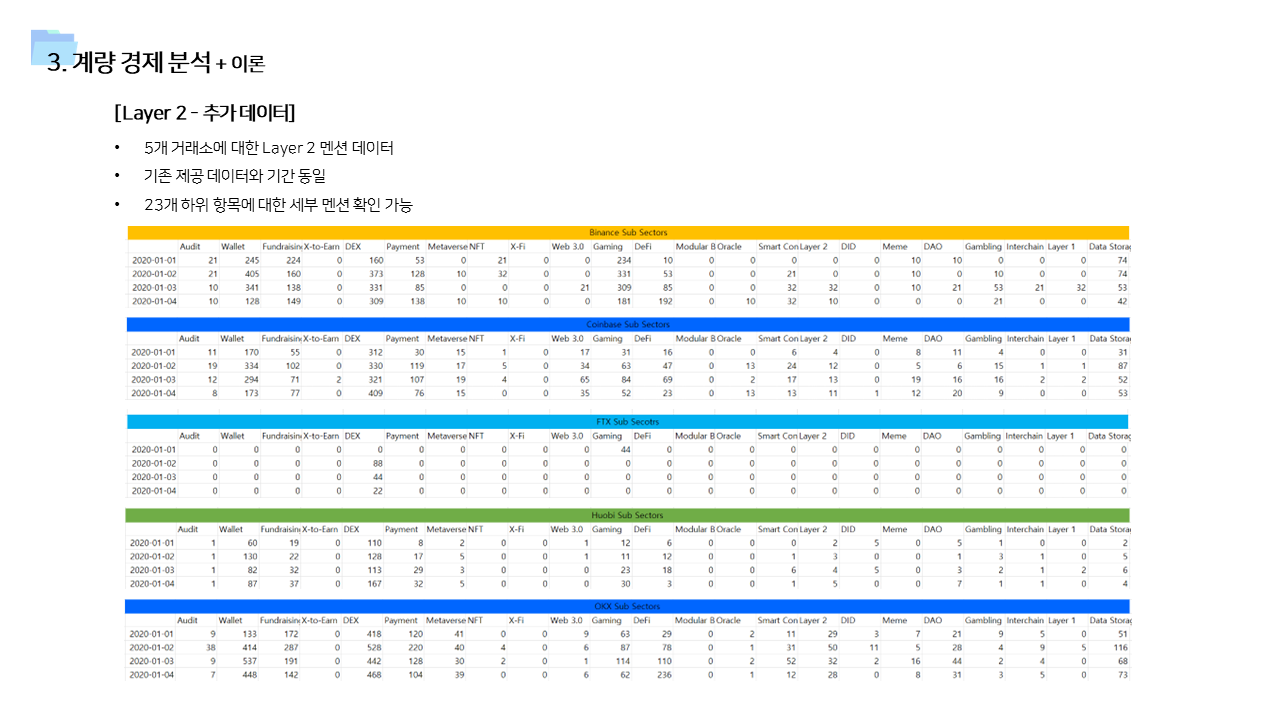
또한 이 데이터에 추가로, 각 블록체인의 Layer 2 데이터도 사용하였다. Layer 2란 블록체인의 각 세부 분야를 의미한다.
블록체인 및 암호화폐가 생소한 팀원들도 있었기 때문에, 본격적인 분석을 시작하기 전에 도메인 지식을 쌓기 위해서 3회 정도 미팅을 하면서 스터디를 진행하였다. 확실히 이때 기초 지식을 함께 쌓아둔 것이 이후 분석을 진행하면서 도움이 많이 되었다. 또한 이 분야 자체가 워낙 빠르게 변화하고 이슈가 많이 발생해서, 분석을 진행하는 동안에도 드라마틱한 사건들이 많이 발생했었다(ex. FTX 사태 등등) 데분은 역시 도메인이다...
📌 데이터 탐색(EDA)
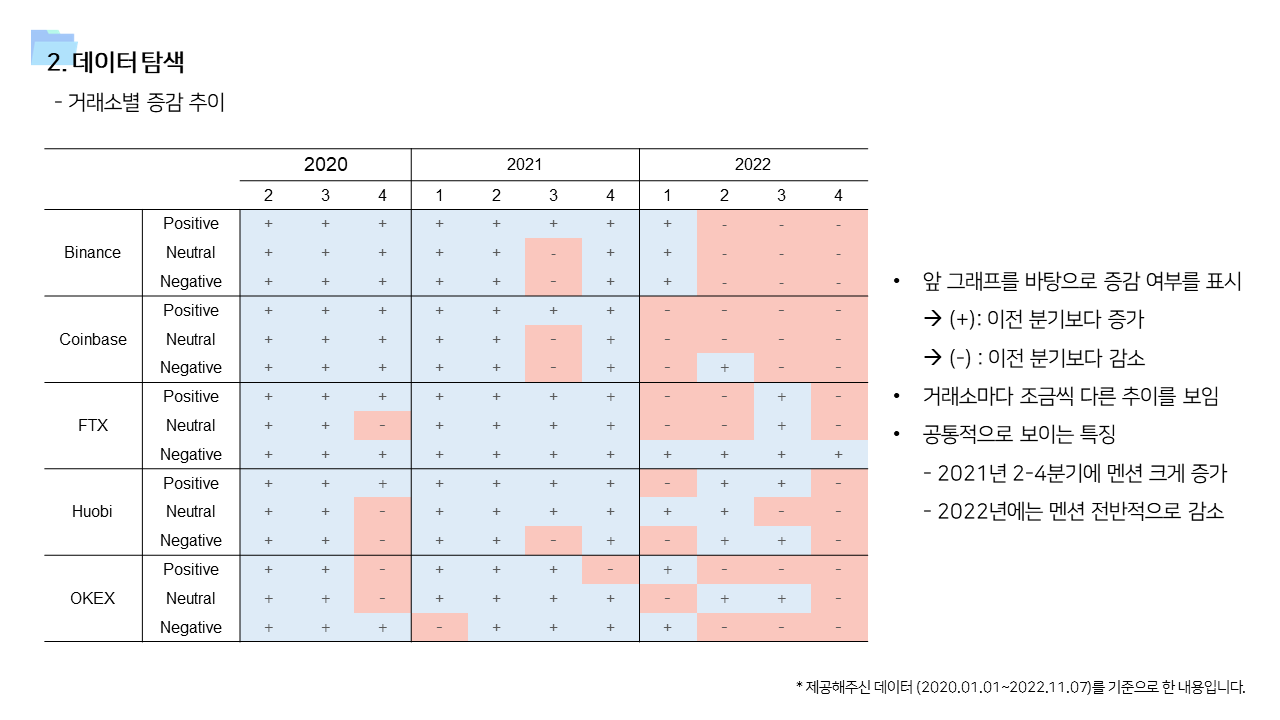
- 다방면으로 데이터를 탐색하는 기간을 가졌다. 직관적인 정보 공유를 위해서 태블로를 이용한 시각화 자료를 많이 만들었다.

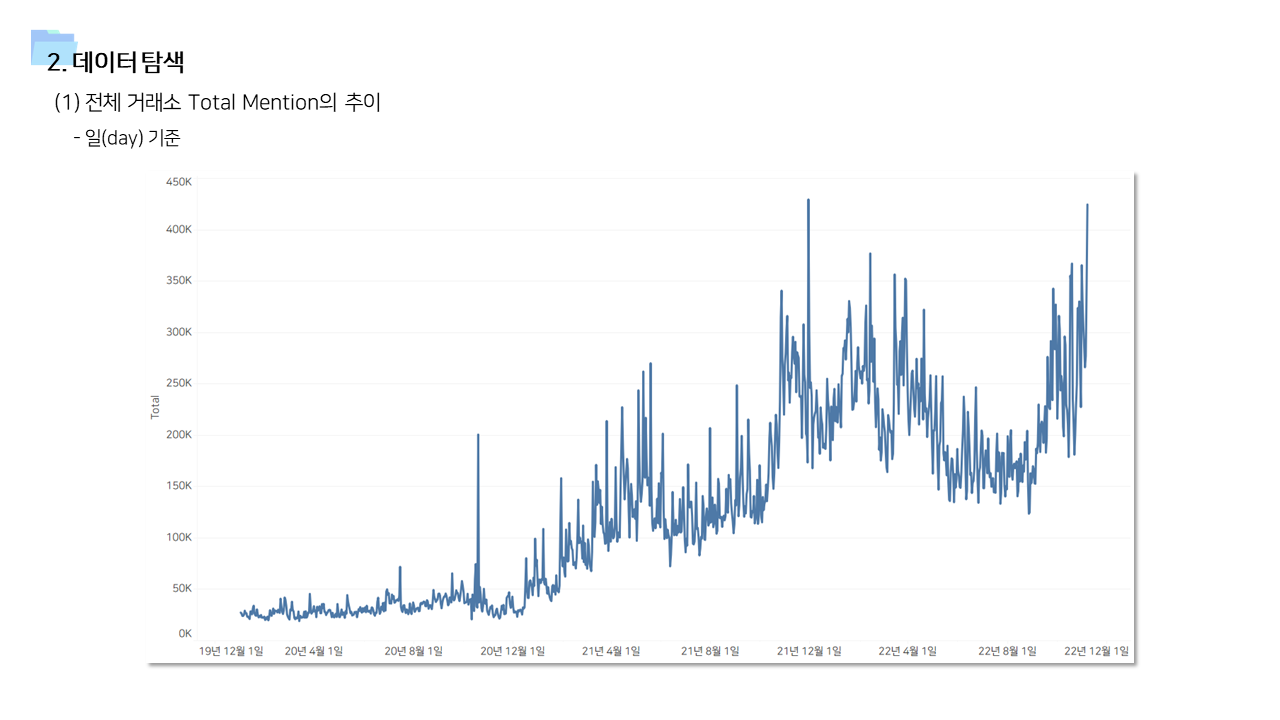

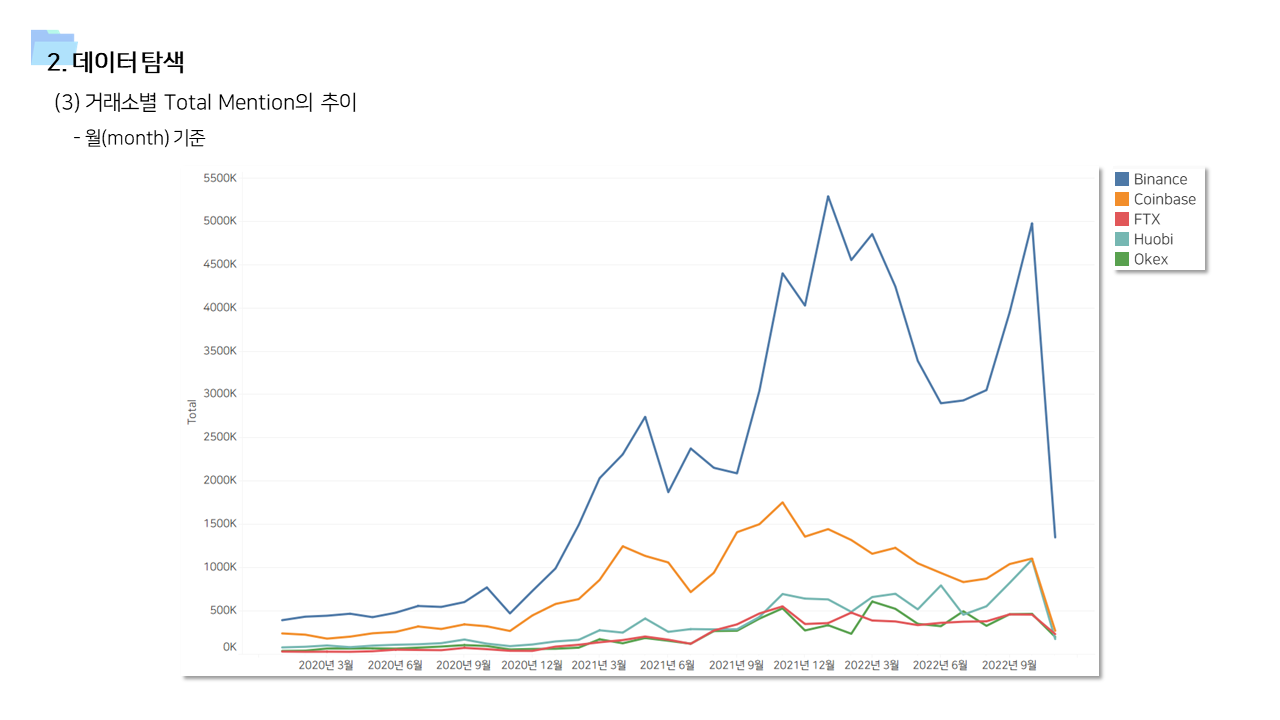
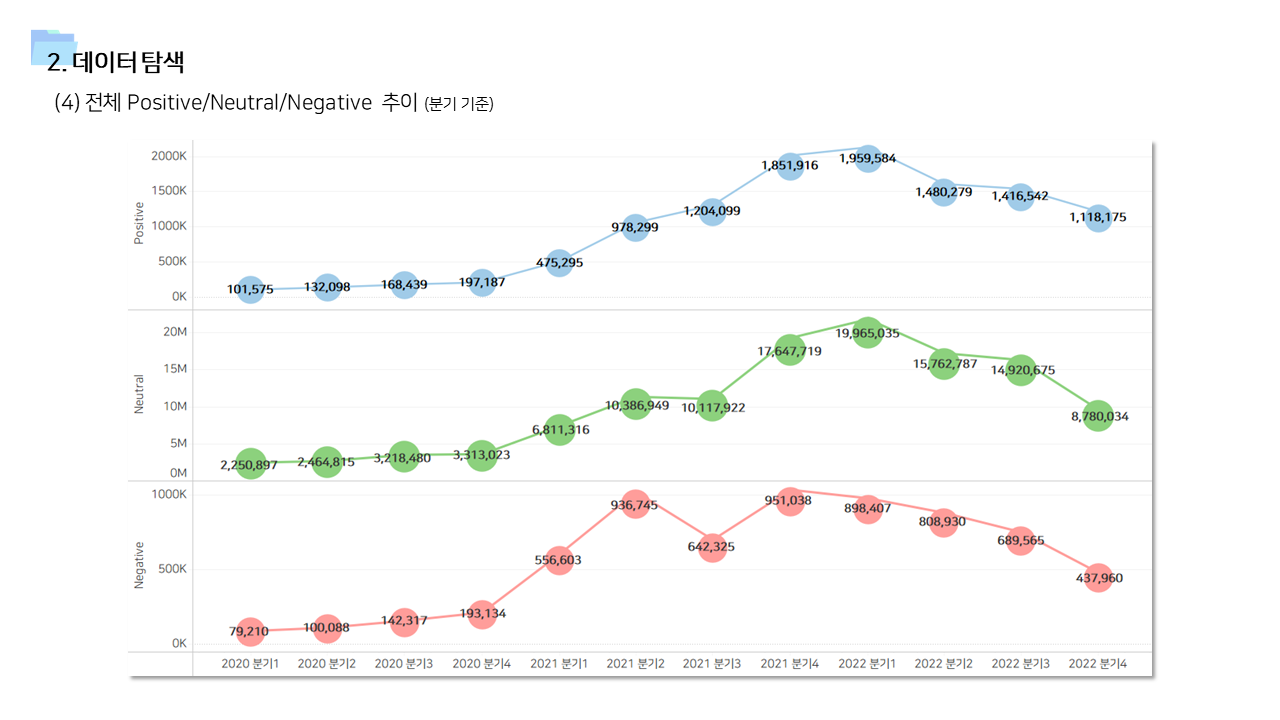
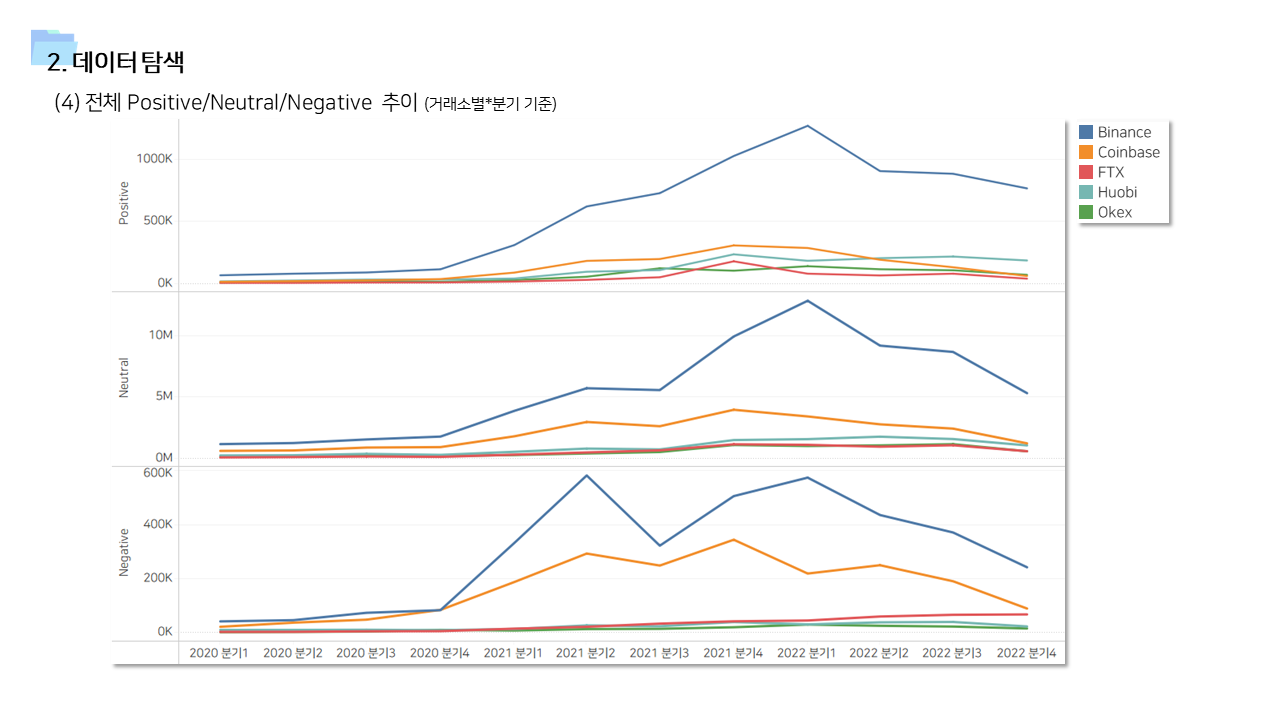
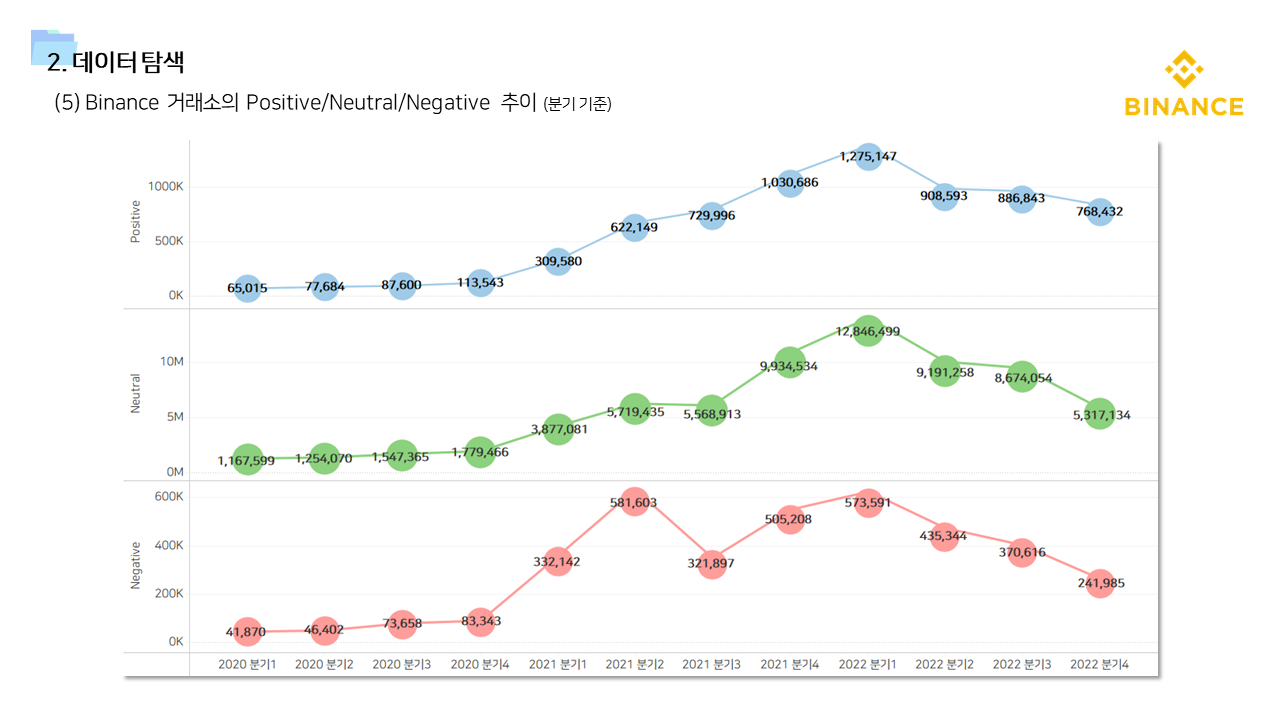
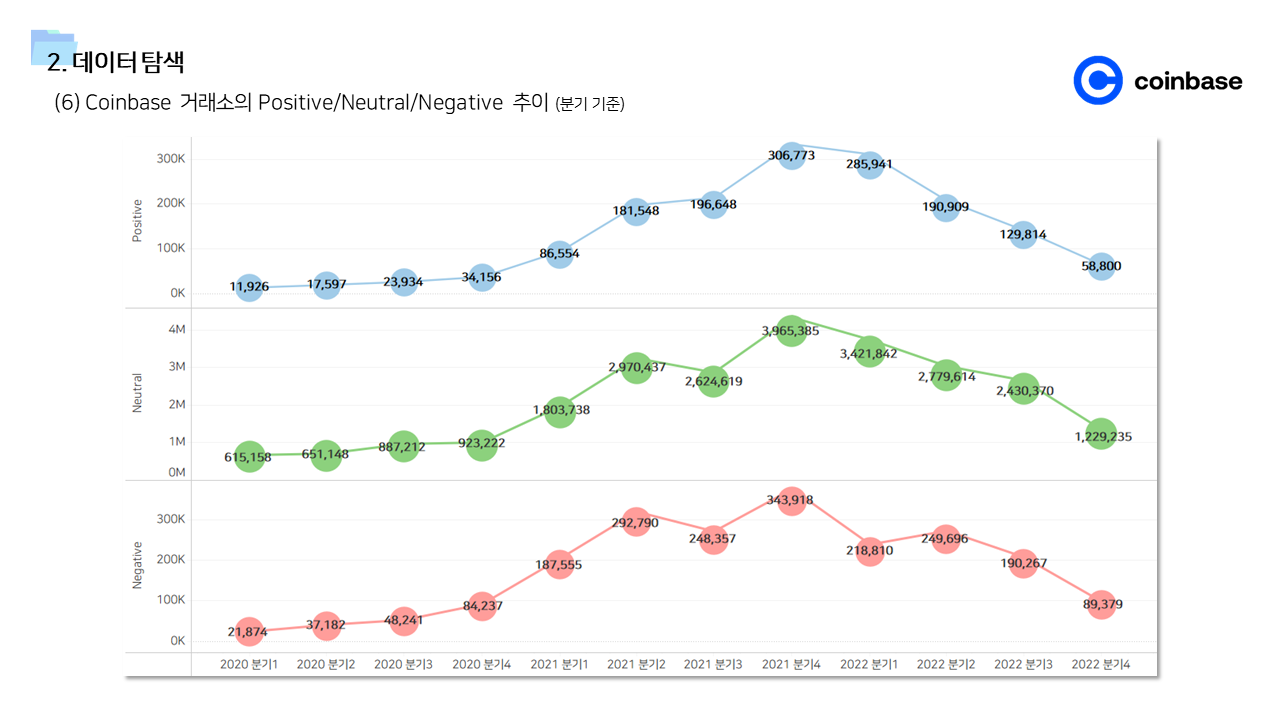
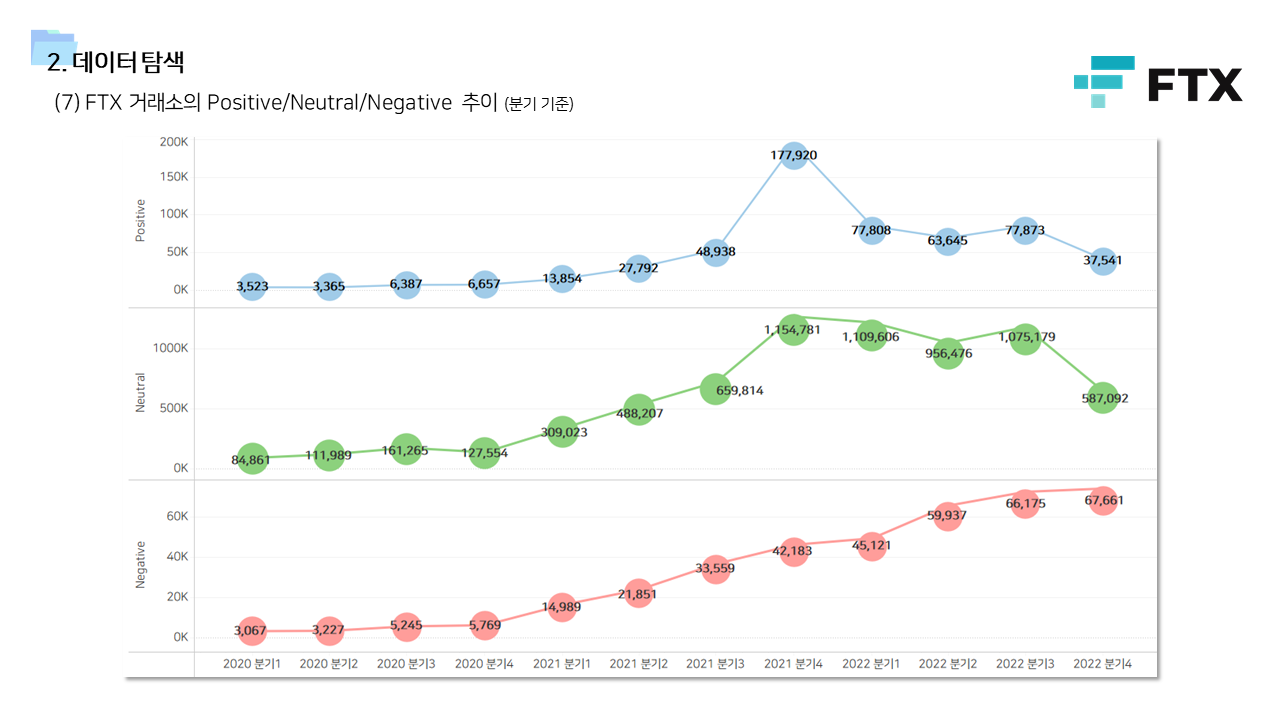
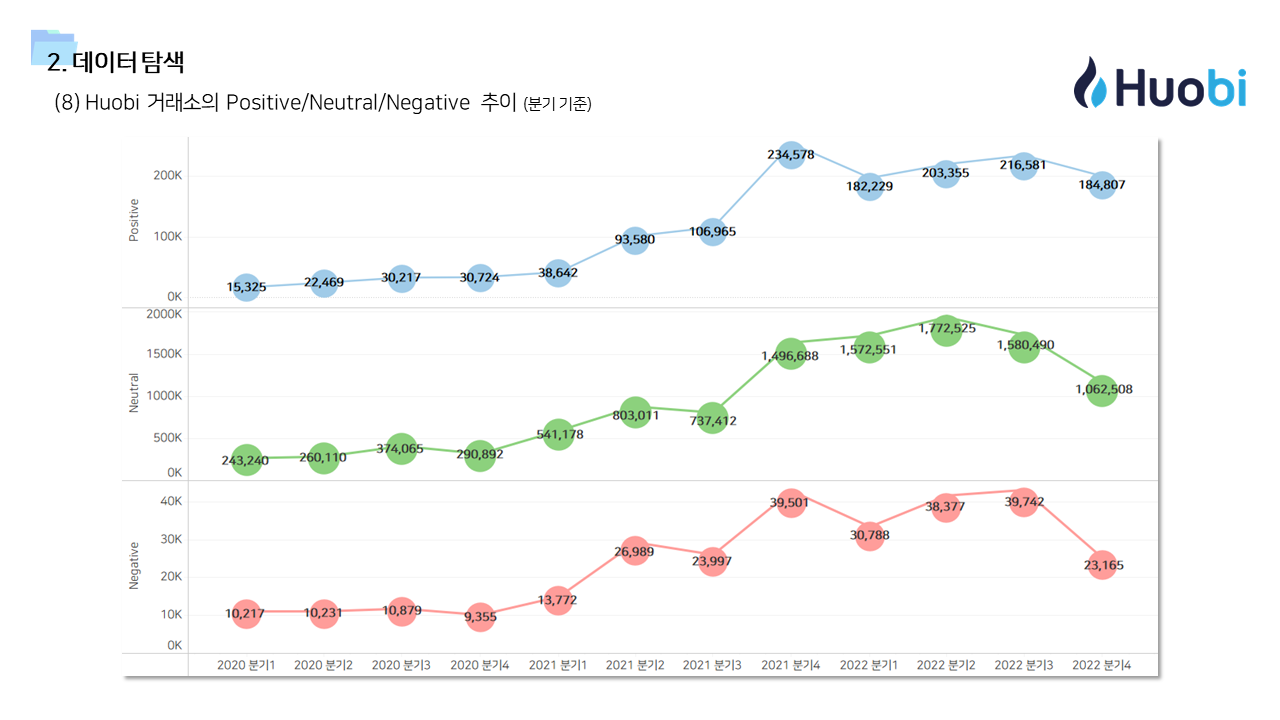
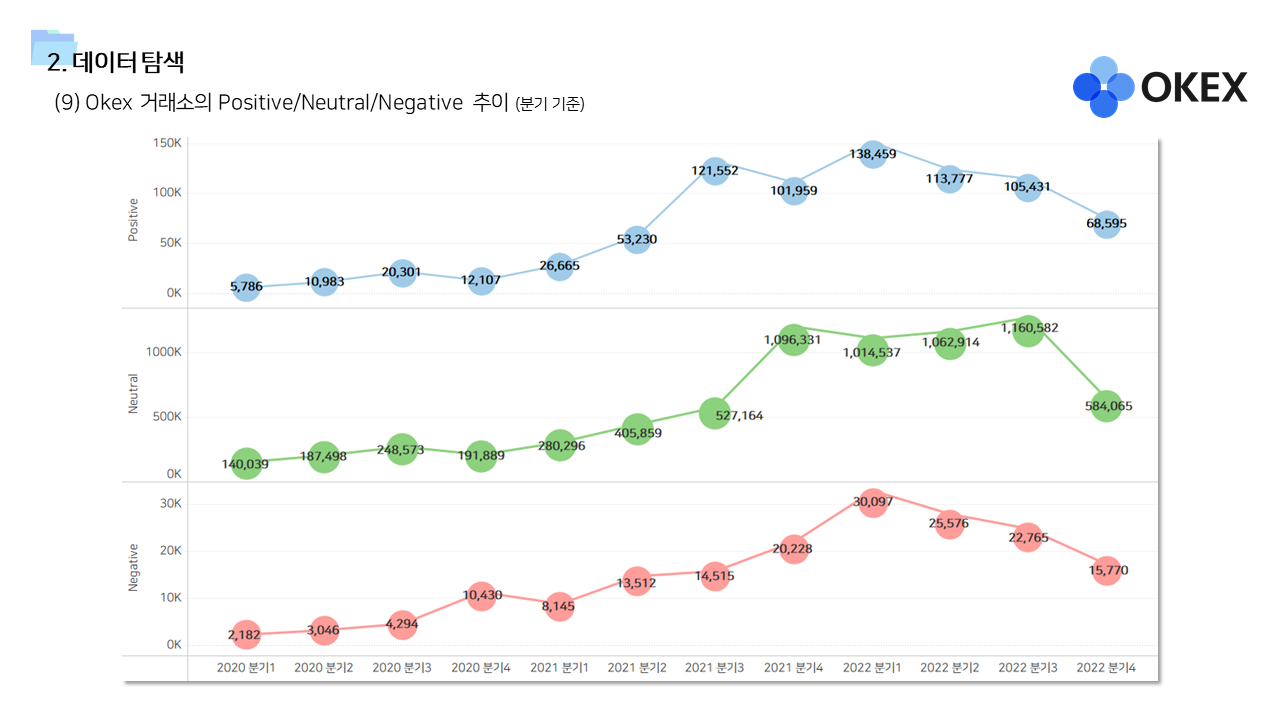
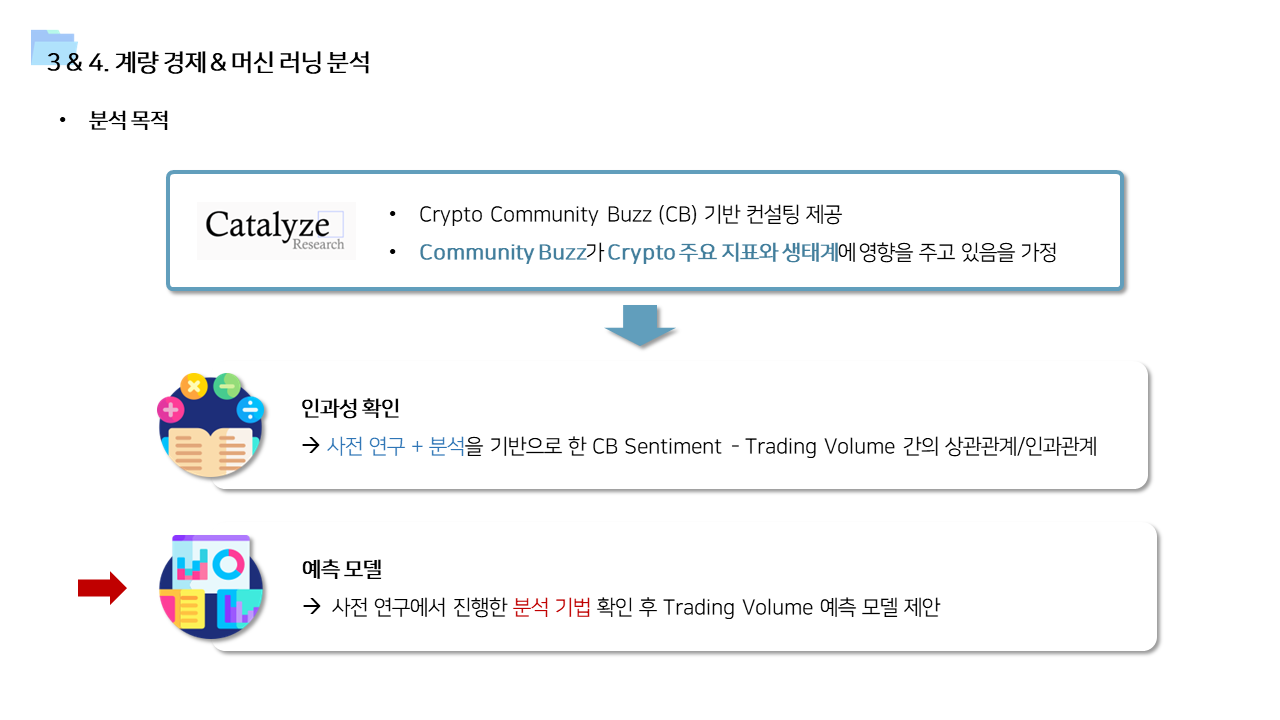
📌 계량경제 분석 (인과추론)
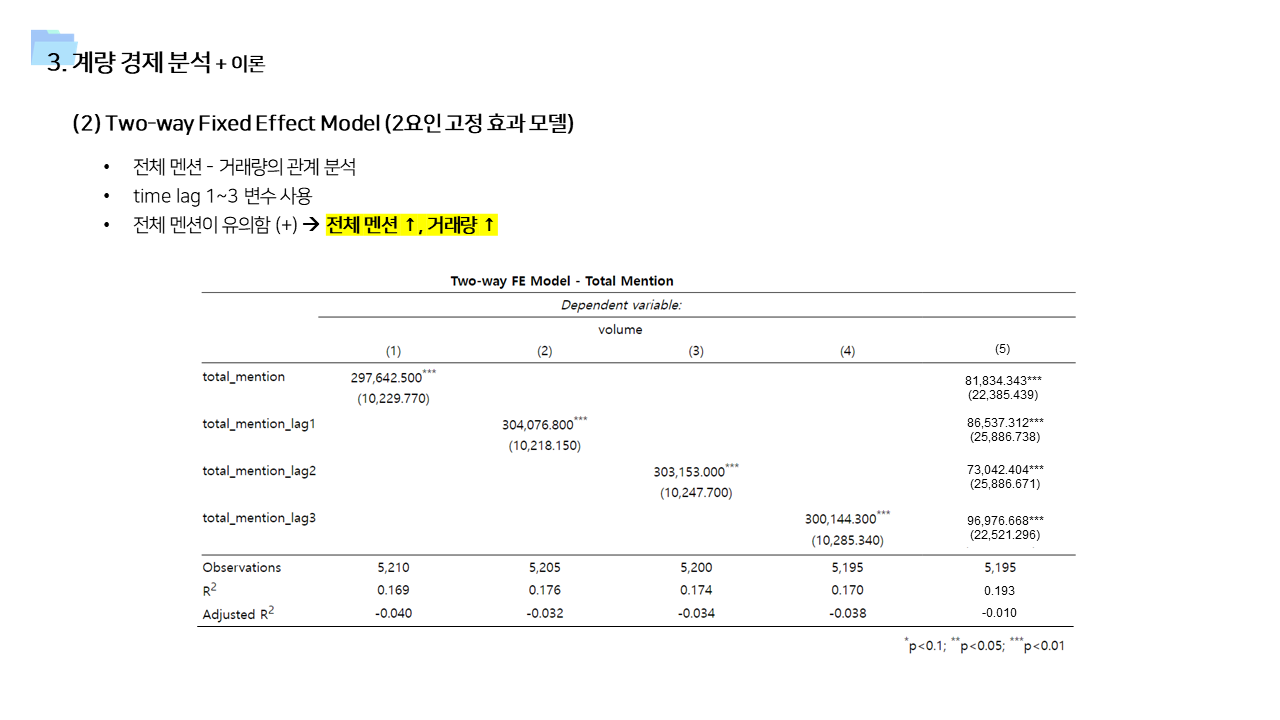
- 커뮤니티 소셜 버즈 데이터 → 암호화폐 거래소의 거래량 간의 인과관계 분석 - daily data이기 때문에 Cross Corrleation 사용 - Two-way Fixed Effect Model 분석 - Panel VAR 분석 (Panel Vector Auto Regressive Model)

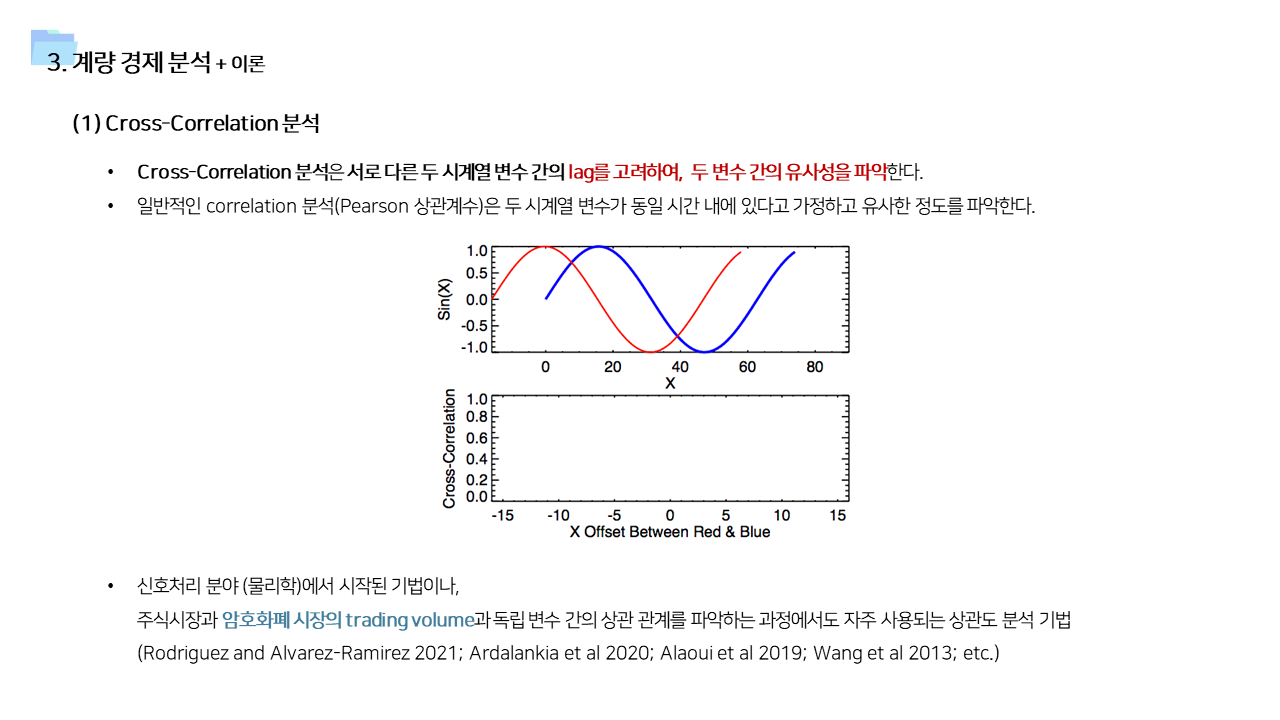
- 사용한 데이터가 일단위 거래량 및 멘션량을 집계한 데이터이기 때문에, 단순히 상관관계를 보기보다는 time lag을 고려한 시계열 상관관계를 살펴보았다.
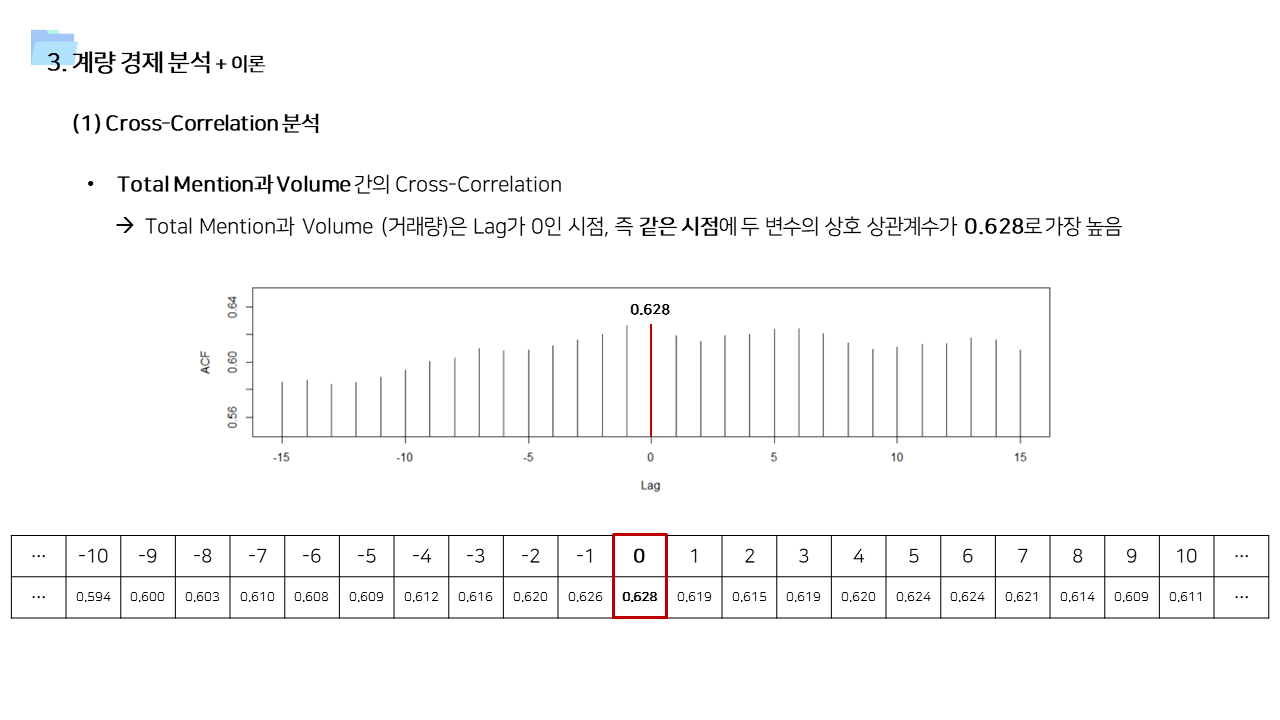
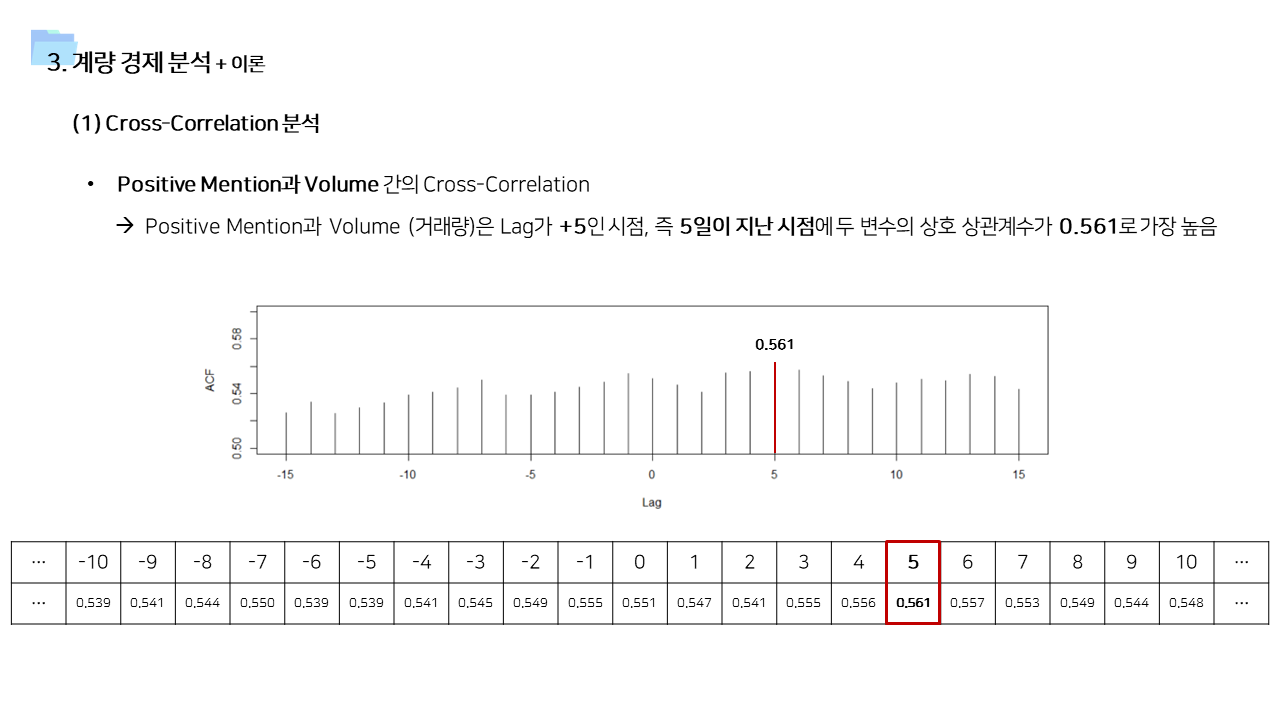
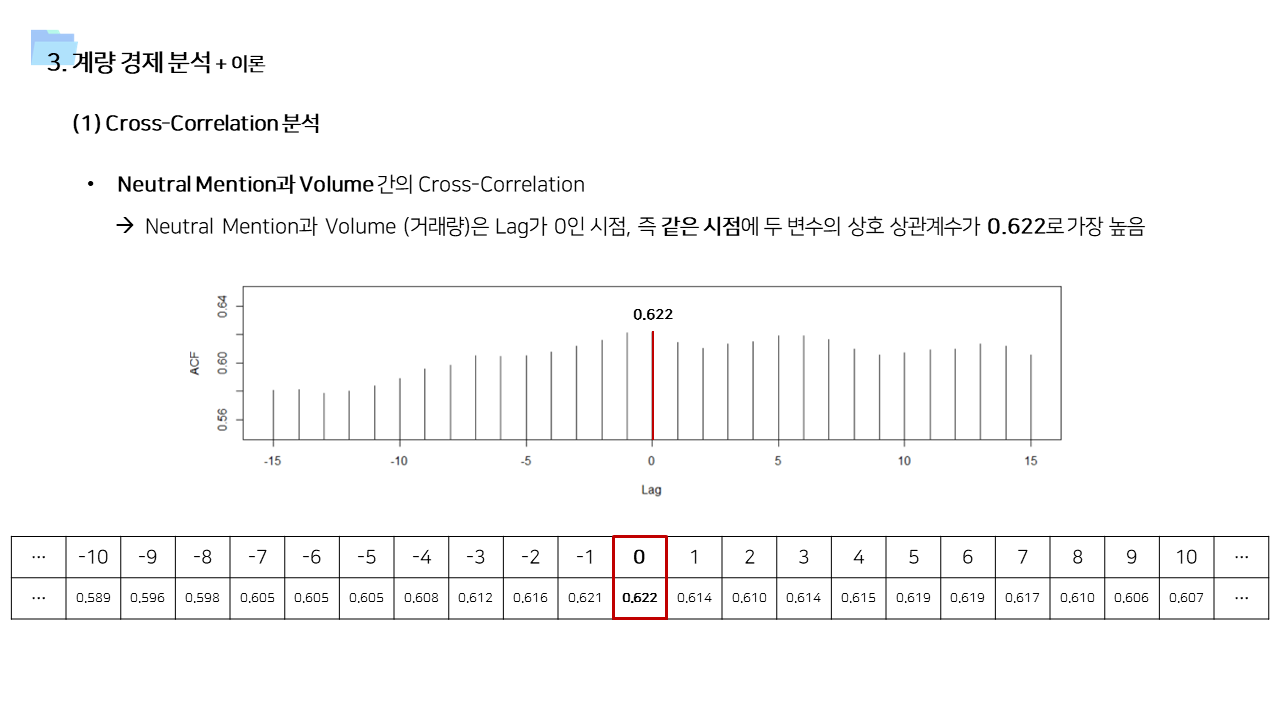
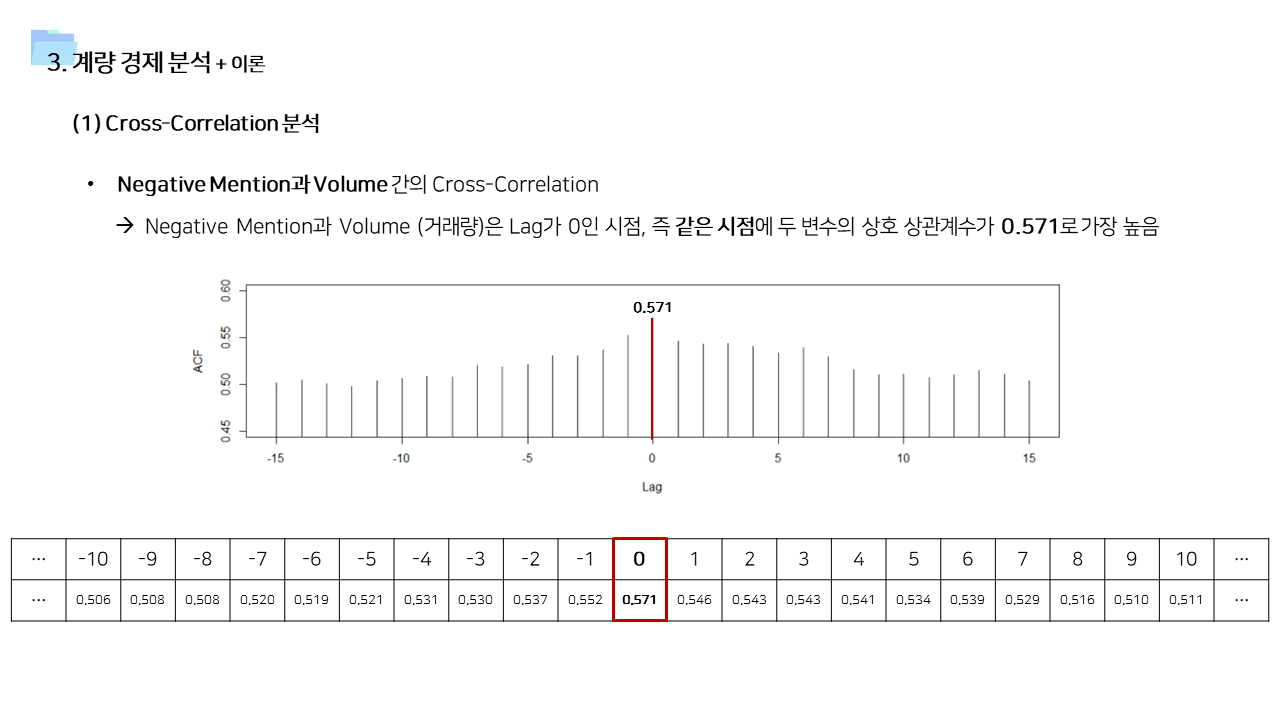
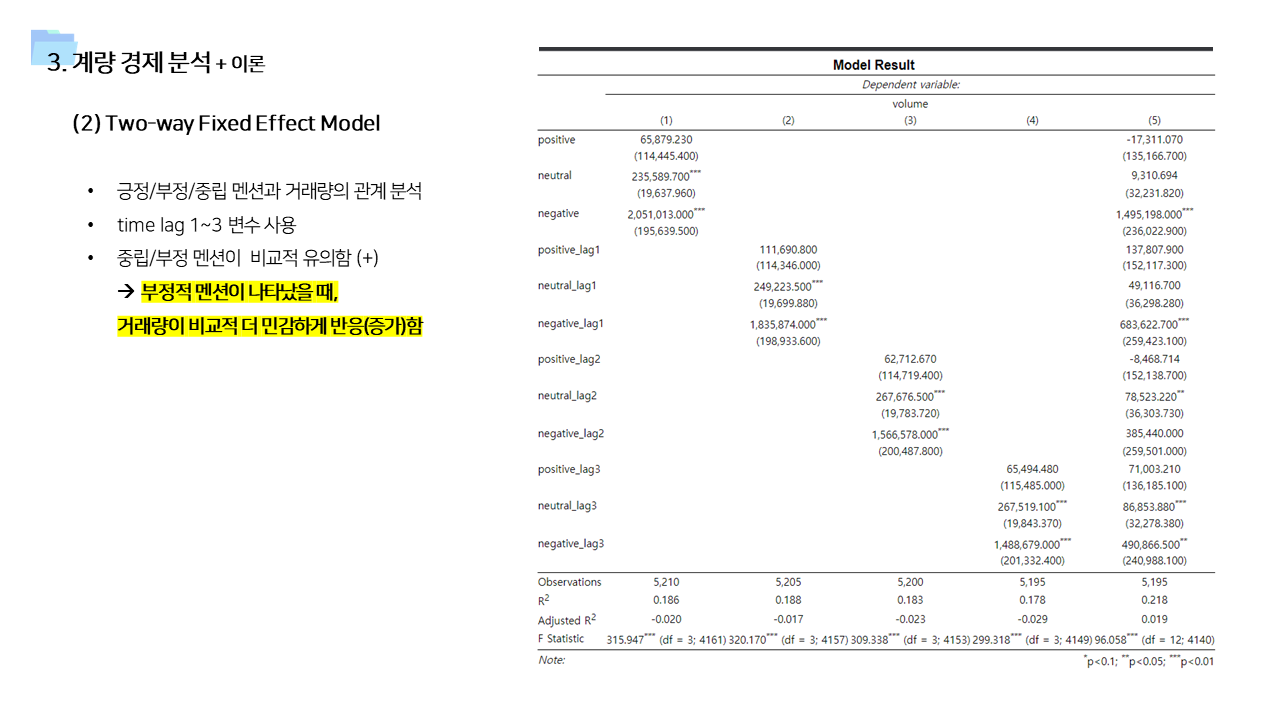
- 긍정적 멘션과 달리 중립 및 부정적 멘션은 즉각저인 상관관계가 나타났다. 상대적으로 정보성 소식과 부정적인 이슈에는 시장이 빠르게 반응한다고 볼 수 있다.

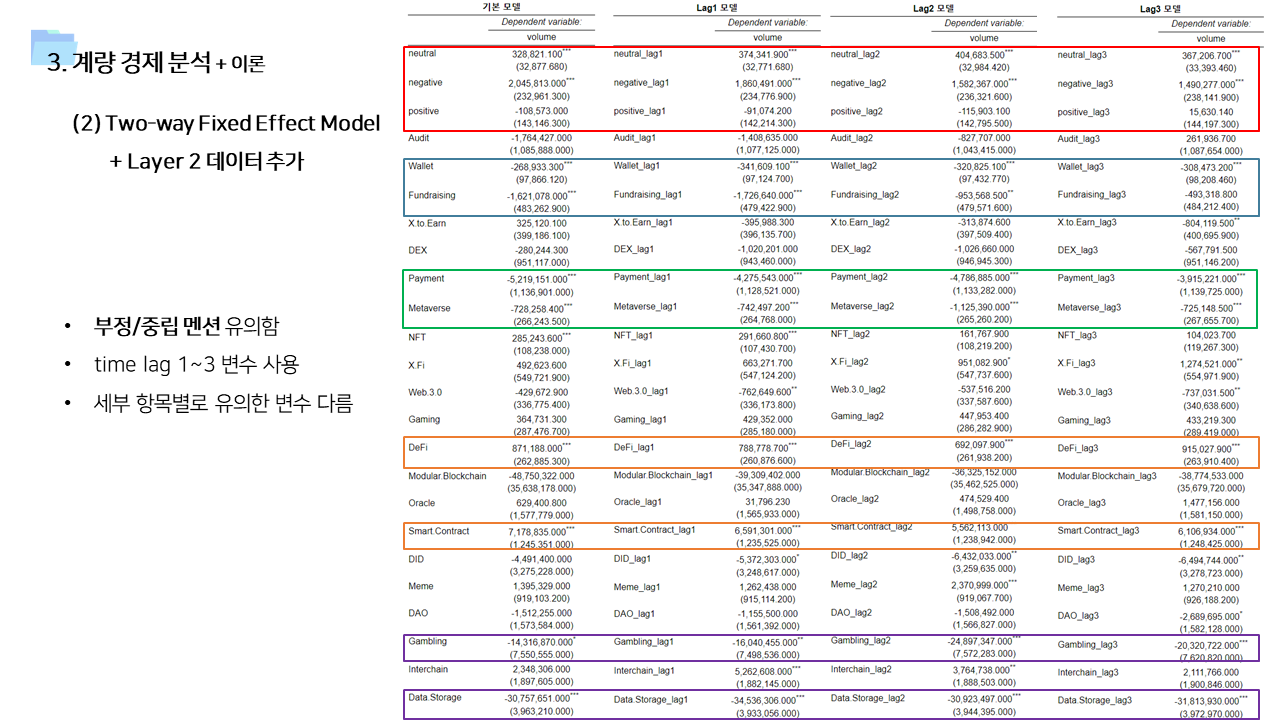
- 각 거래소별 및 일자별로 관측되지 않은 특성을 배제하기 위해서 Two way fixed effect 모델을 사용하였다.
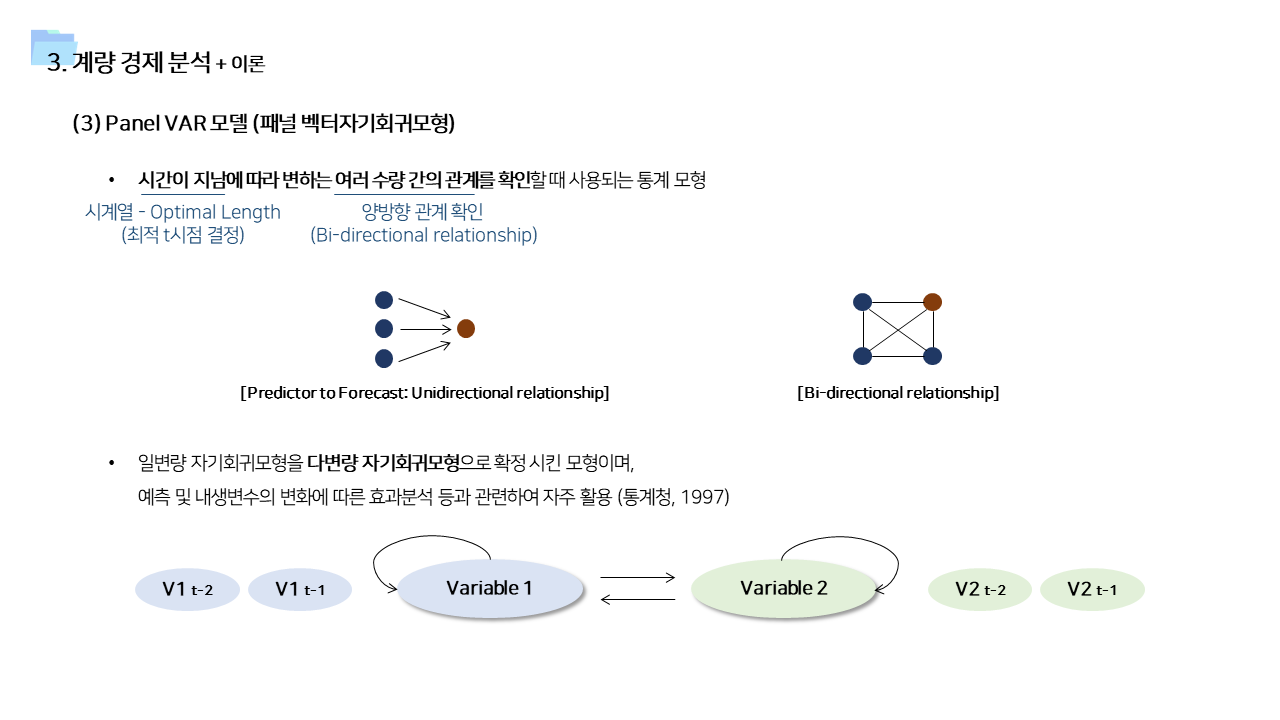
- two way fixed 모델에서 나아가서, 데이터를 패널 형태로 구성하고 VAR 모델을 사용함
- 오늘의 멘션량이 내일, 모레의 멘선량에도 영향을 준다는 가정




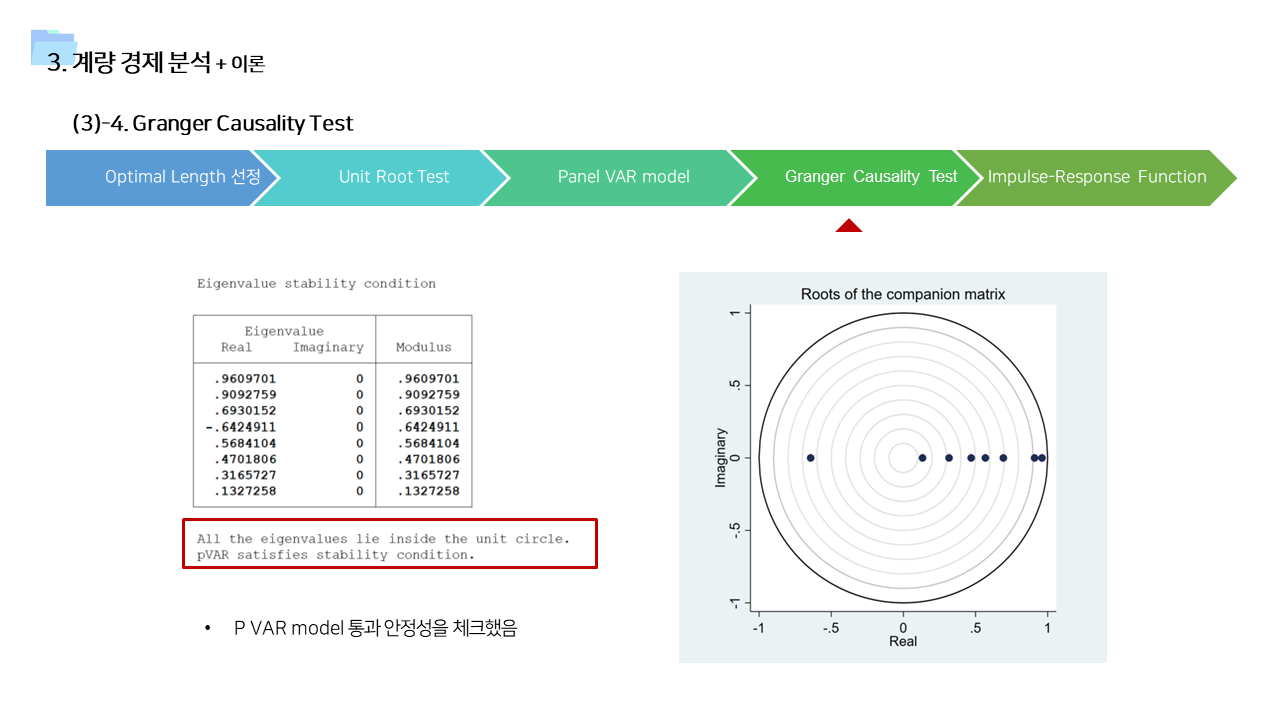
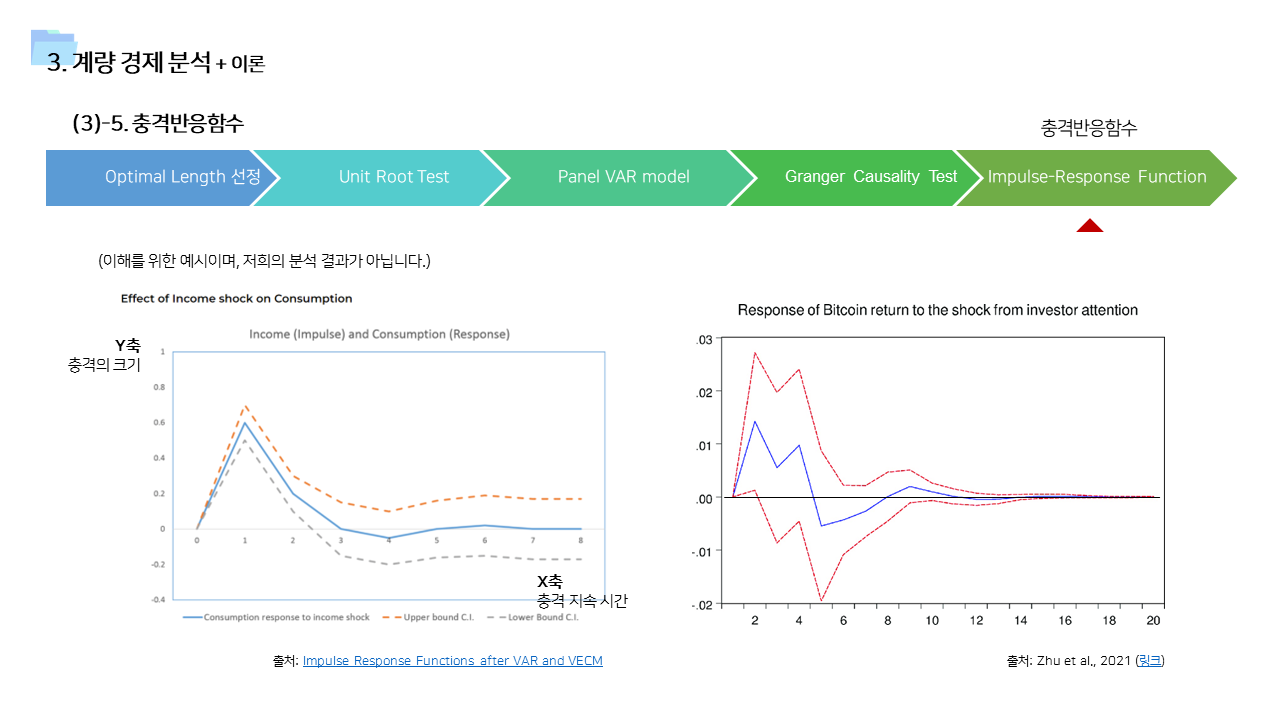
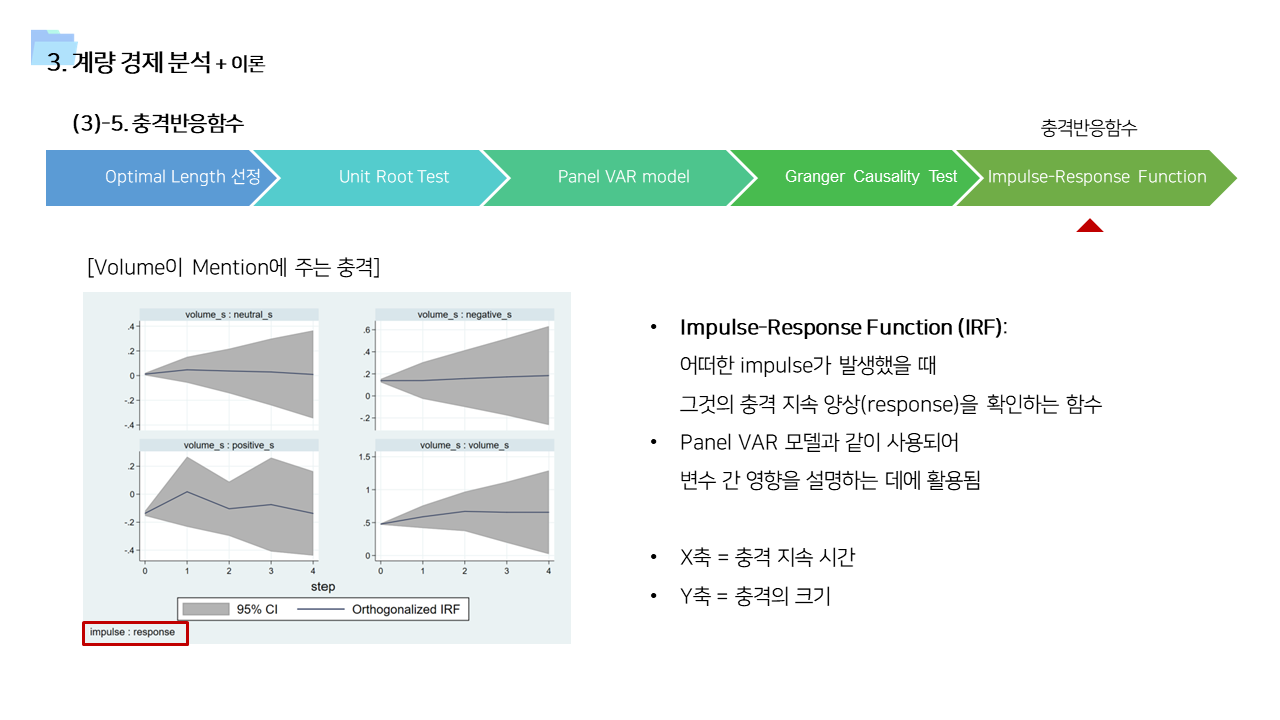
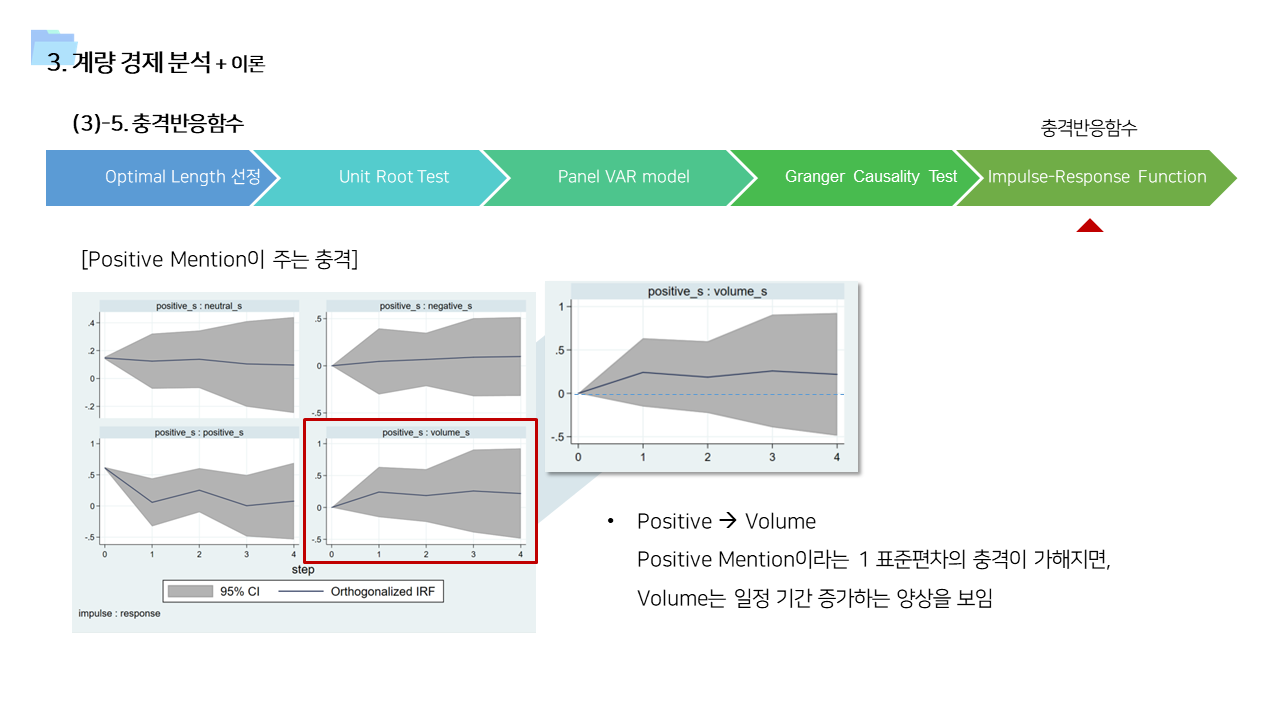
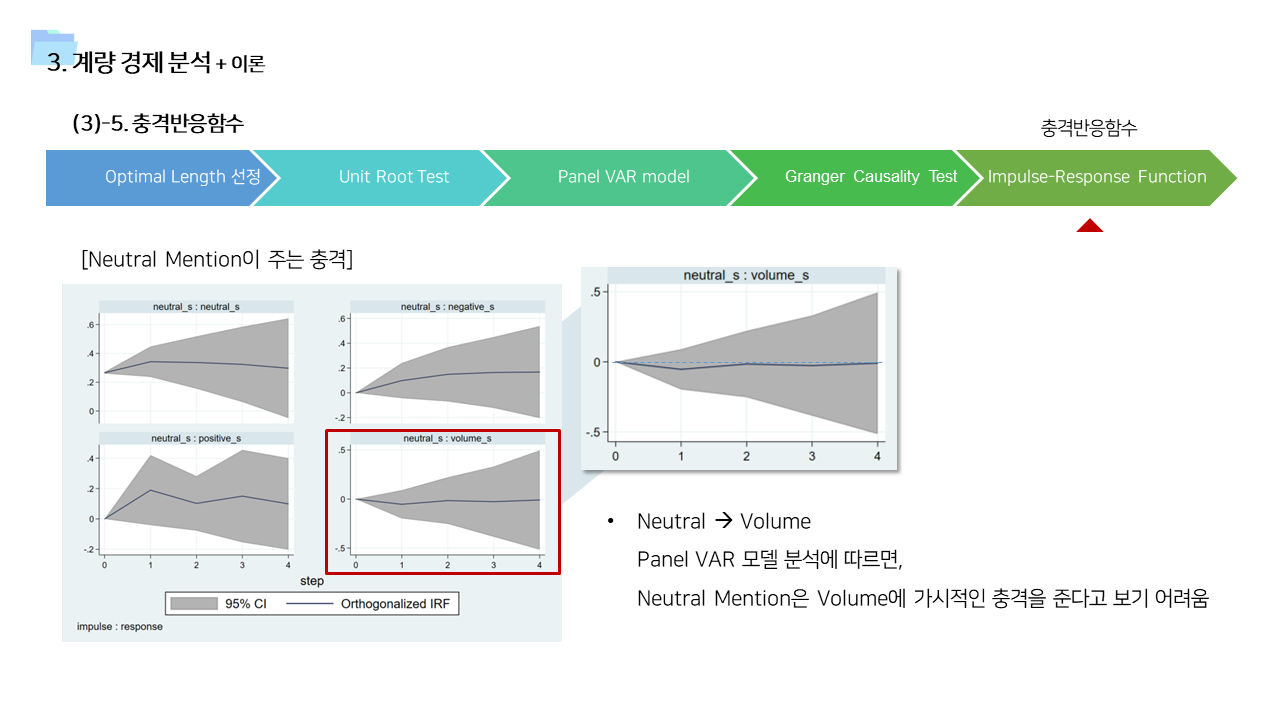
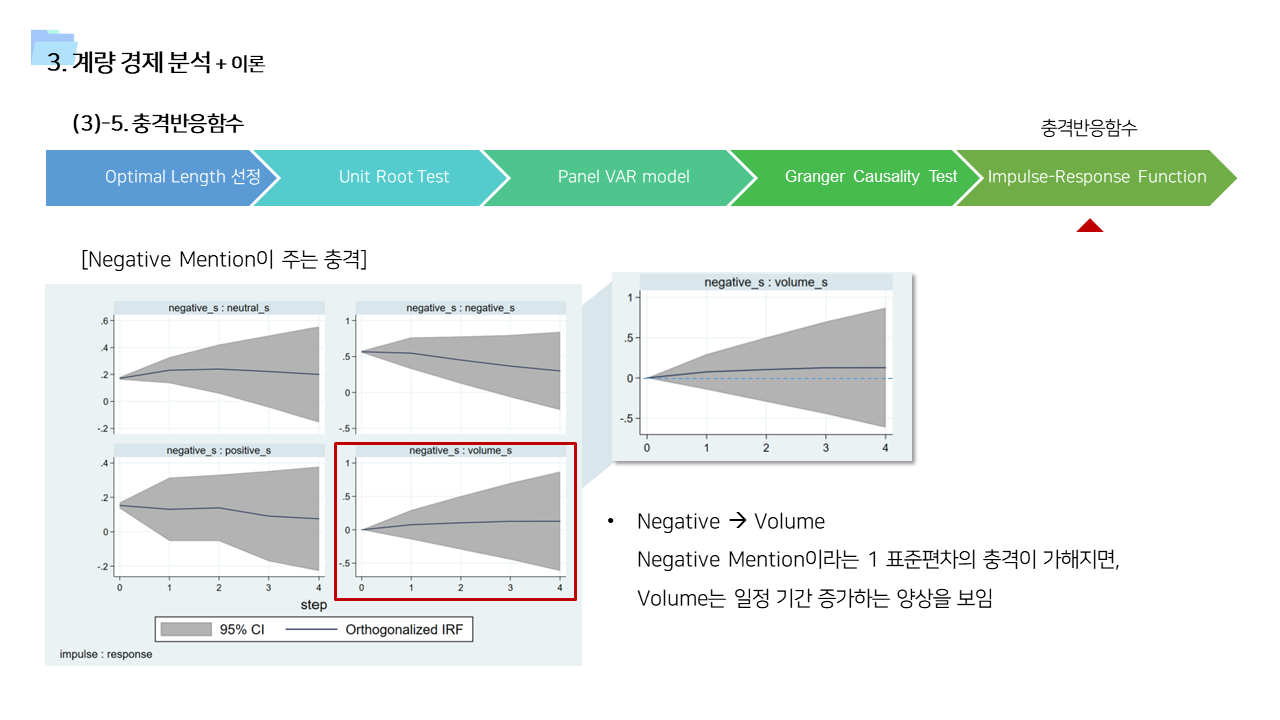




- 위의 분석 기법의 결과를 뒷받침할 수 있는 근거 이론들을 기존 연구에서 찾아보았다. 여러 분야에서 이러한 행동을 설명하기 위한 이론들이 존재한다는 것을 확인할 수 있었다.
📌 머신러닝 예측 모델
- 각 거래소의 멘션량 및 Layer 2 데이터를 이용해서 암호화폐 거래소별 거래량 예측하는 모델 구축
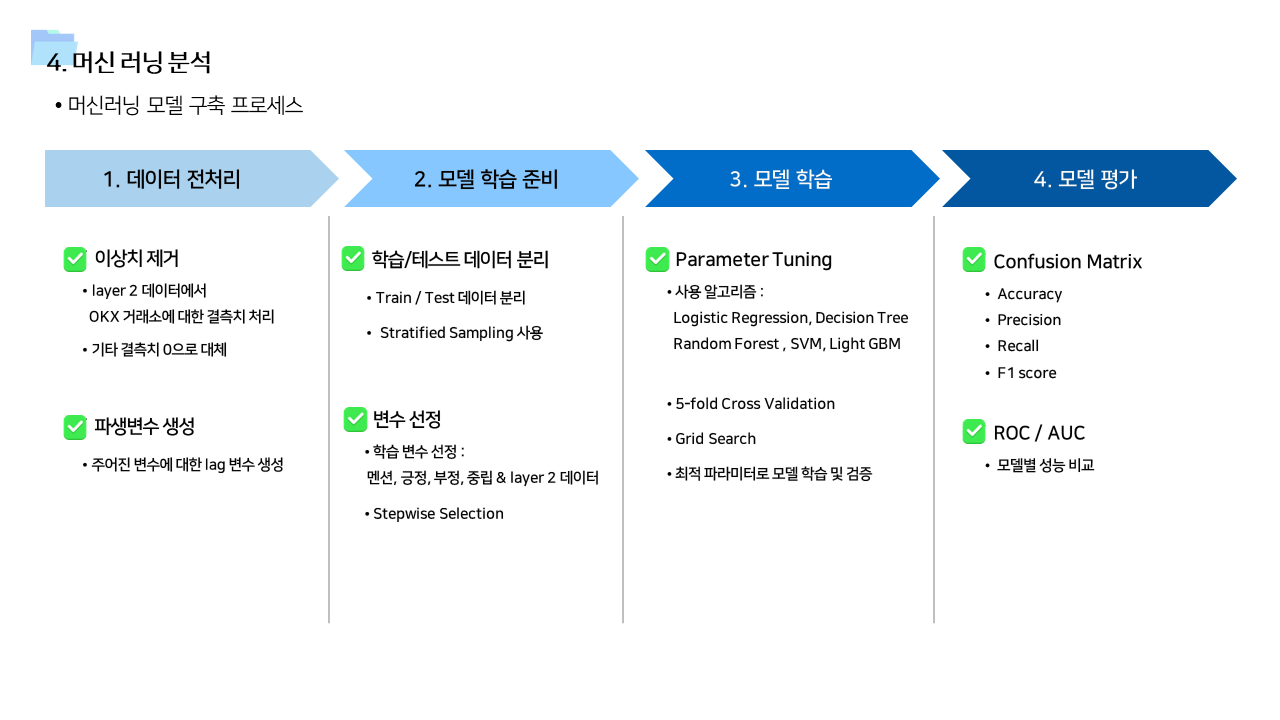
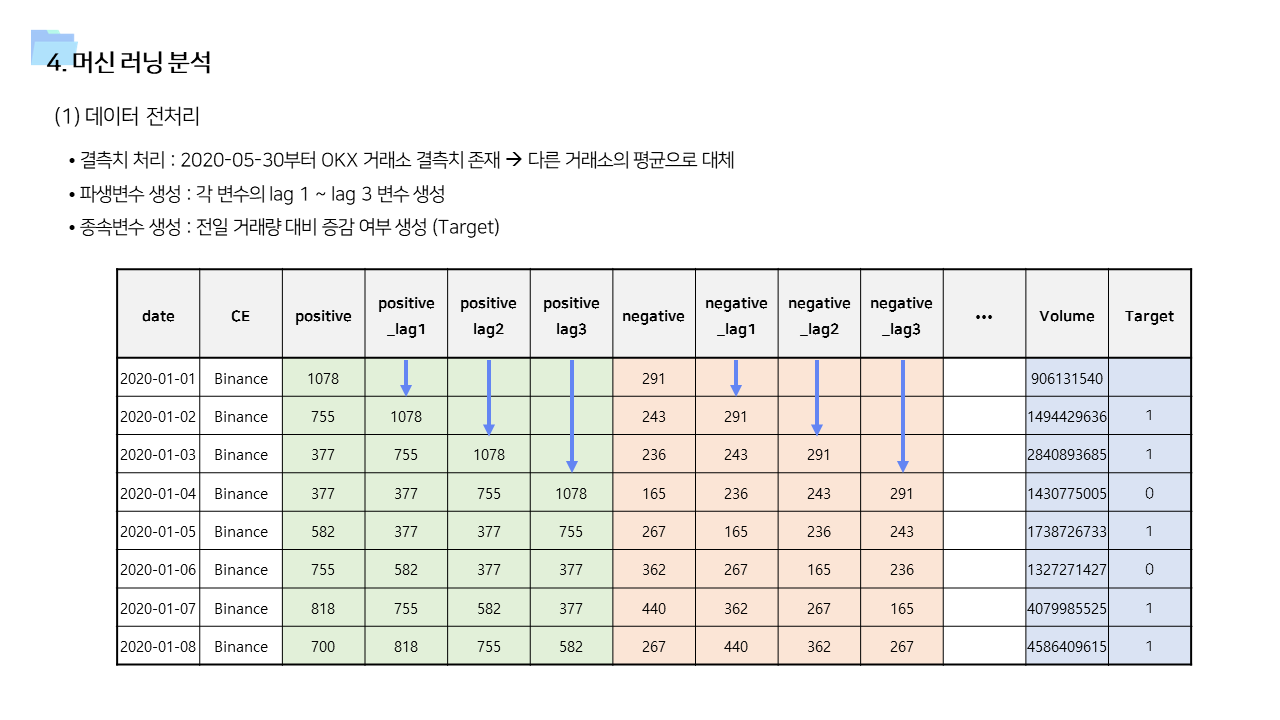
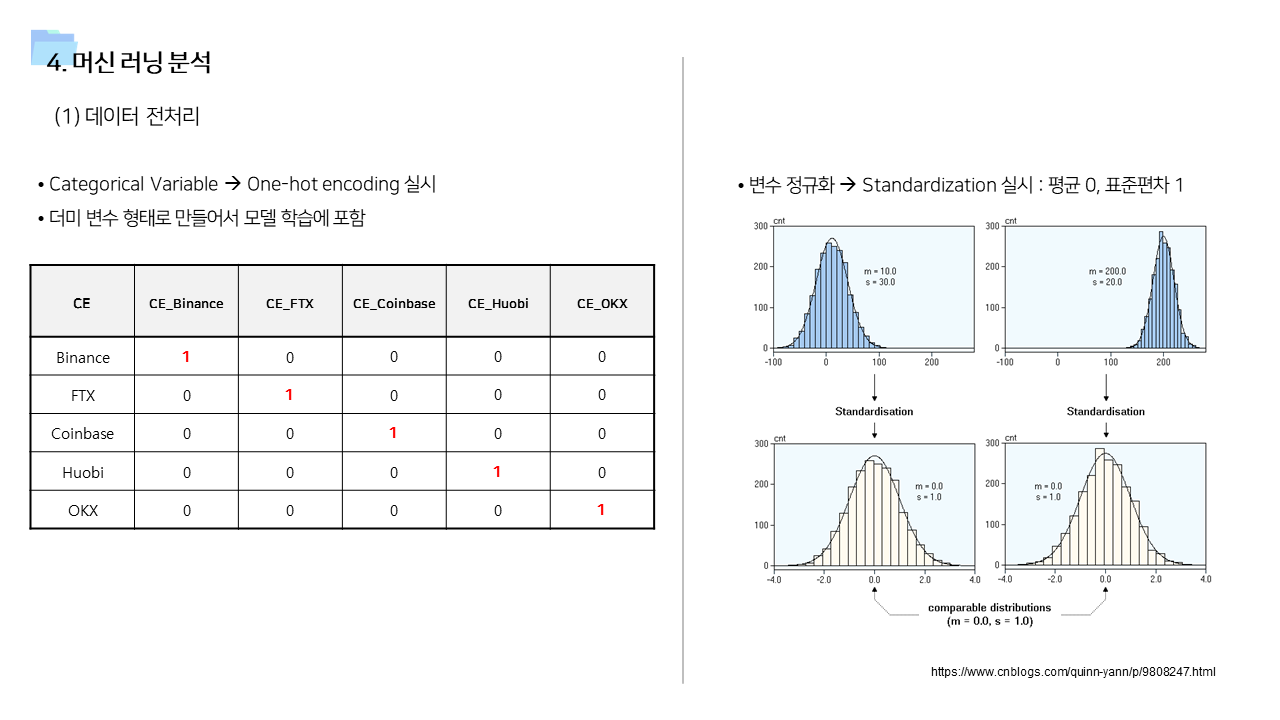
- cross correlation 및 Panel VAR 분석 결과를 기반으로 time lag 변수도 추가하여 학습 진행

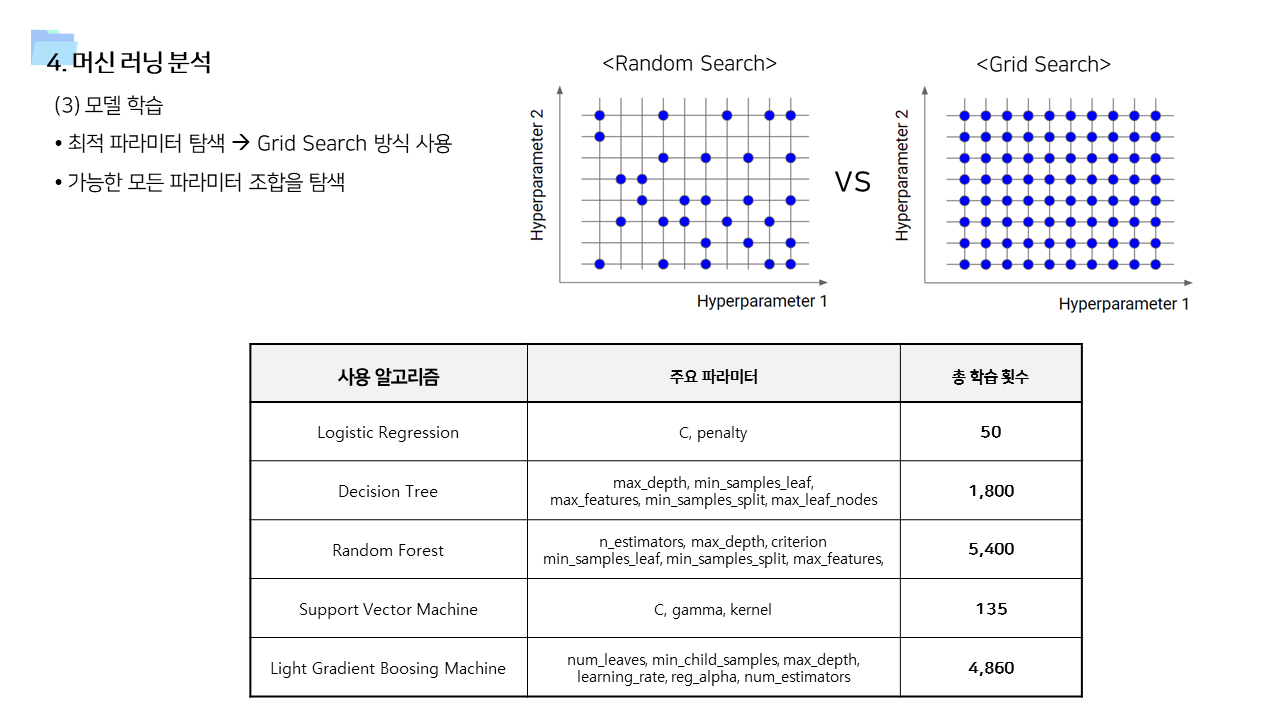
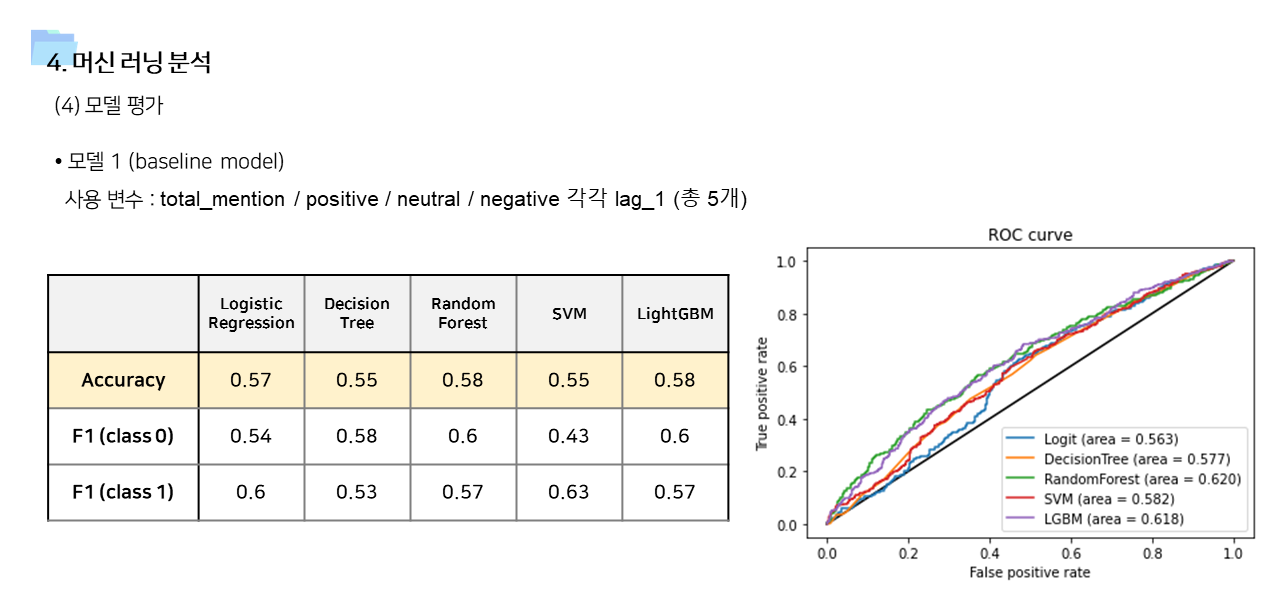
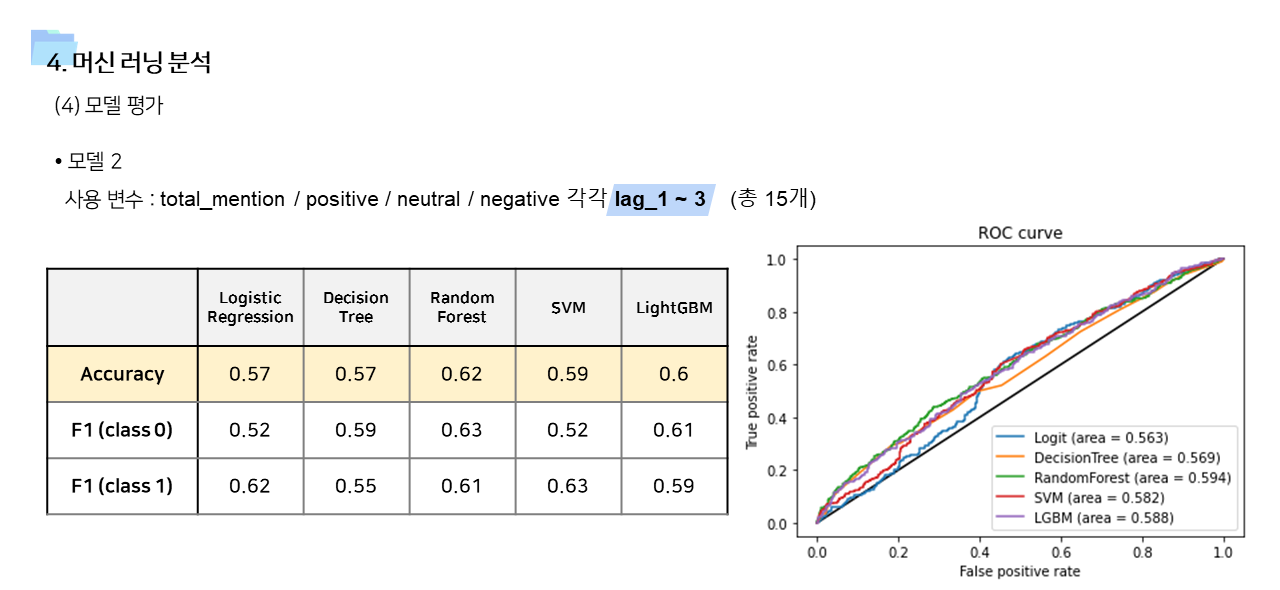
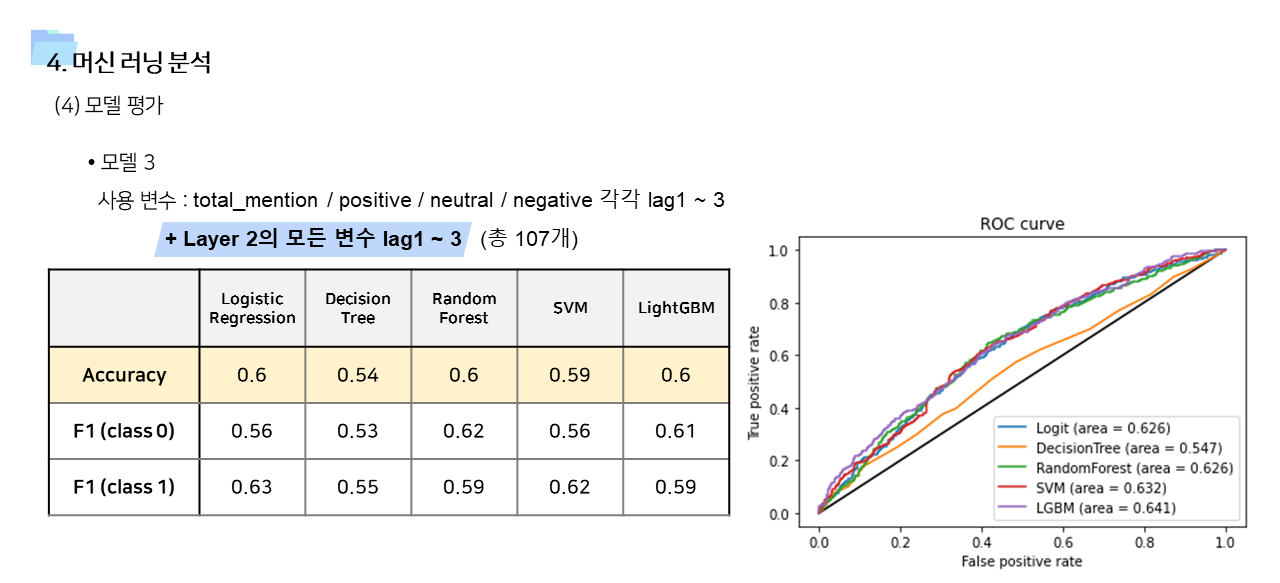
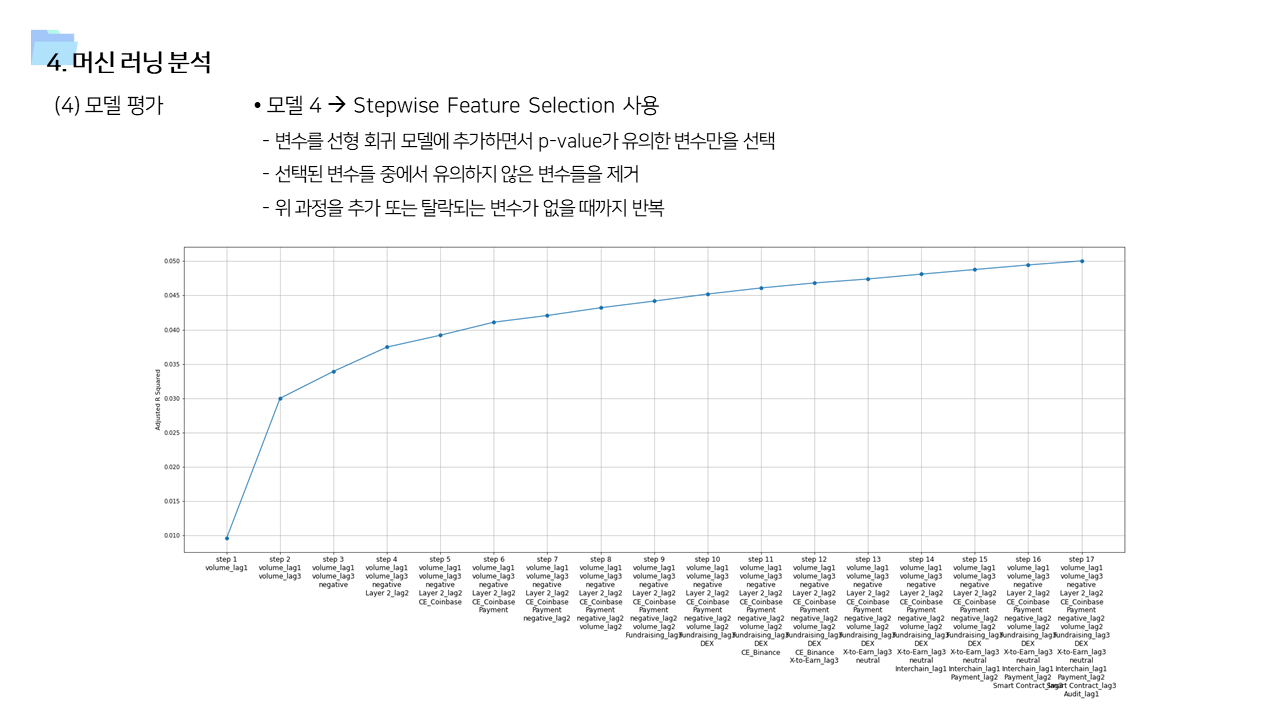
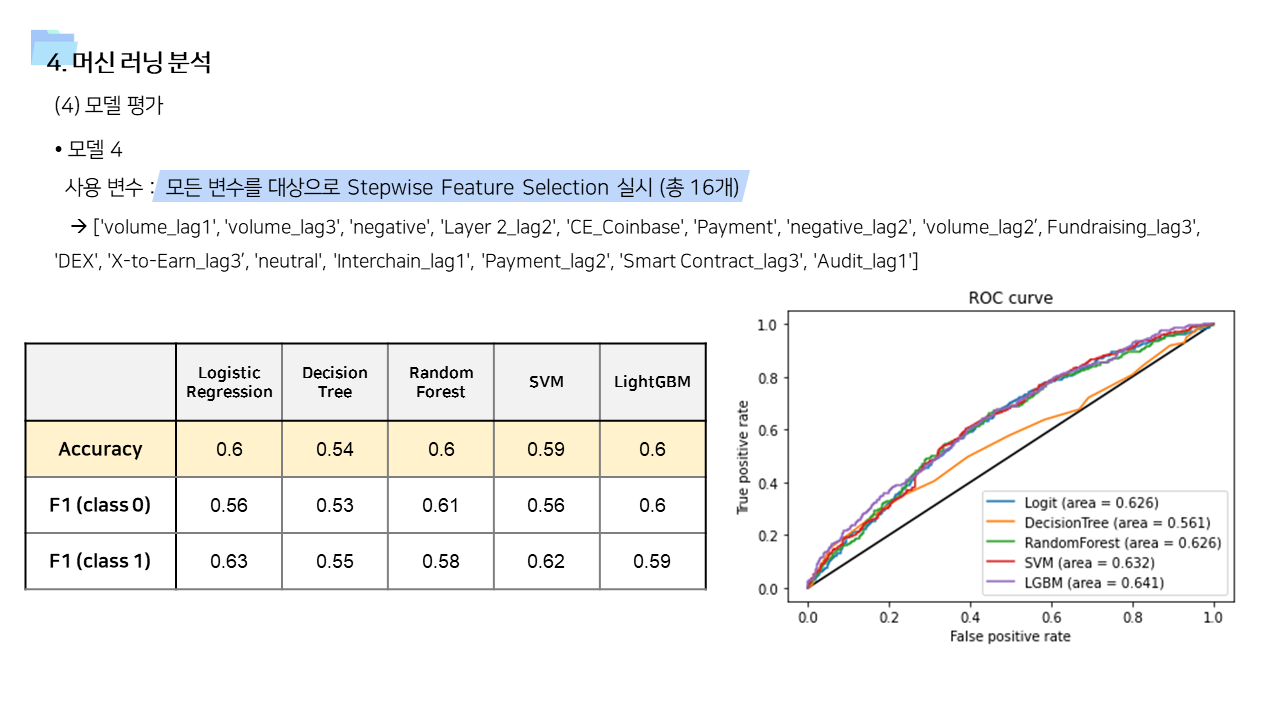
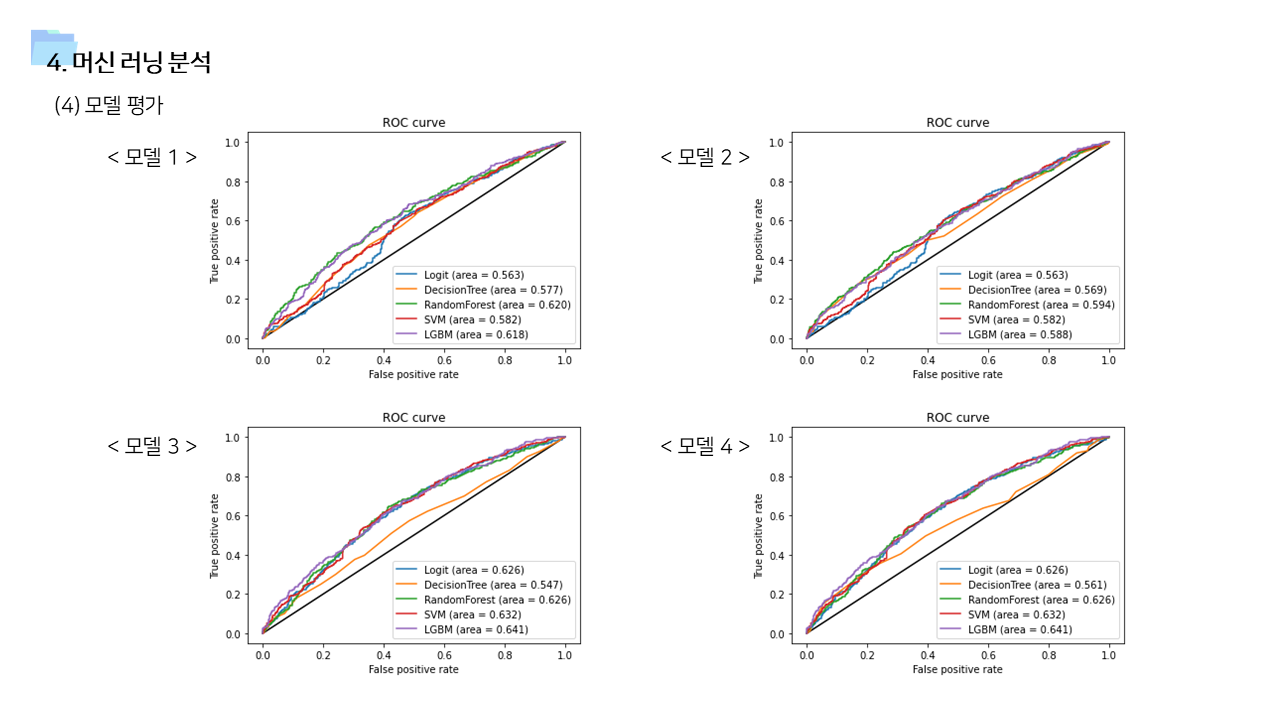
- 사용 변수에 따라서 모델1 ~ 모델 4 를 만들고 결과를 비교하였다. 사용 알고리즘은 Logistic Regression, Decision Tree, Random Forest, Support Vector Machine, Light GBM 으로 모두 동일했다.
- 기본 변수만 포함한 모델1이 성능이 가장 낮게 나타났다.
- time lag 1~3 변수까지 포함한 모델3과, Layer 2 관련 변수를 모두 포함시켜서 stepwise selection을 실시한 모델 4의 경우 예측력이 향상된 것을 확인할 수 있었다. LGBM 을 사용했을 때 정확도가 0.6, ROC가 0.64 였는데, 모델1보다는 성능이 좋아졌지만 그럼에도 조금 아쉬움이 남는 값이긴 하다. 이 부분은 더 많은 기간의 데이터를 사용한다면 충분히 개선의 여지가 있다고 본다.


'프로젝트 및 공모전' 카테고리의 다른 글
| [팀 프로젝트] 이동통신사 고객 데이터 분석 및 이탈예측 모델 제안 (2) | 2023.05.07 |
|---|---|
| [공모전] 상품 키워드 사전을 이용한 홈쇼핑 매출액 예측 및 최적 편성표 제안 (0) | 2022.09.20 |
| [공모전] 단계적 군집화를 이용한 온라인학습 플랫폼 이용자 이탈방지 전략 제안 (0) | 2022.08.28 |
| [팀 프로젝트] 온라인 리뷰 토픽모델링을 이용한 스마트폰 브랜드 마케팅 전략 제안 (0) | 2022.08.25 |
| [팀 프로젝트] London Airbnb 데이터 분석 및 가격 예측모델 제안 (0) | 2022.05.12 |




댓글