📚 논문 정보

📚 요약
모델 구조 설명
Embedding Layer
유저들의 시퀀스가 각기 다르기 때문에 시퀀스 s의 길이를 n으로 통일하였다. n은 모델이 다룰 수 있는 최대 길이이다. 시퀀스가 짧은 경우는 왼쪽부터(가장 과거부터) zero padding을 실시한다. 만약 시퀀스가 n 보다 클 경우에는 가장 최근의 데이터만 사용한다. lookup layer를 사용해서 원핫 벡터 형태인 action sequence : s 와 category sequence : c 를 dense vector 형태로 변경한다. 카테고리 외에 브랜드, 판매자 등 해당 상품과 관련이 있는 변수들은 동일하게 시퀀스로 처리하였다. 또한 제품 설명, 제목 등의 텍스트 데이터에 대해서는 토픽모델링으로 5개의 토픽을 추출하고 Word2Vec으로 벡터로 변환하였다.
Vanilla Attention Layer
입력하는 피쳐들의 특성이 모두 다르기 때문에 어떤 피쳐가 영향을 줄 지 파악하기는 쉽지 않다. 따라서 다양한 특성에서 나타나는 유저의 행동을 캡쳐하기 위해서 vanilla attention을 사용한다. 카테고리/브랜드/텍스트 벡터를 모아서 Ai라는 집합으로 표현하고 아래와 같이 attention 레이어에 통과시킨다.
그리고 아이템 i의 feqture representation은 attention score의 가중치를 바탕으로 아래와 같이 계산한다.
이를 통해서 feature sequence 인 f={f1,f2,f3....,fn} 을 얻을 수 있다.
Feature-based self-attention block
셀프 어텐션은 positional embedding을 사용한다. 여기서도 positional matrix인 P 를 input embedding에 추가한다.
원래 논문의 scaled dot production attention 계산은 아래 식과 같은데, 여기서는 포지셔널 매트릭스인 F와 곱해서 이것에 대한 SDPA를 실행한다. WQ, WK, WV는 각각
multihead attention은 원래 트랜스포머 논문과 동일하게 아래와 같이 정리할 수 있다. 이 논문에서는 수식 단순화를 위해서 가장 아래와 같이 Of로 정리하였다.
여러 정보를 반영하기 위해서 아래와 같이 셀프어텐션 블락을 쌓는다.

Item-based self-attention block
피쳐 기반 셀프어텐션 블록과 동일하게 계산을 진행한다.

Fully connected layer
아이템 시퀀스와 피쳐 시퀀스의 결과를 덴스 레이어를 통해서 결합한다. 그리고 최종적으로 dot production을 통해서 선호도를 계산한다.

성능 평가는 Hit Ratio, Normalized Discounted Cumulative Gain을 이용하여 진행하였다. 사용 데이터로는 Amazon의 Toy & Games 카테고리의 제품 데이터와 Tmall 데이터를 사용했다.
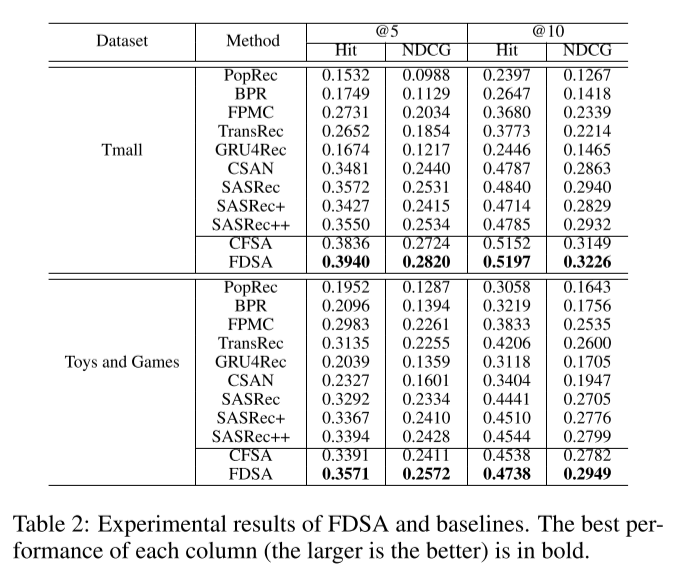
이 연구에서 제안한 FDSA 모델의 성능이 가장 좋게 나타난 것을 확인할 수 있다.
'논문 리뷰 > 추천시스템' 카테고리의 다른 글
| [추천시스템] 딥러닝을 이용한 온라인 리뷰 기반 다속성별 추천 모형 개발 (0) | 2022.03.12 |
|---|---|
| [추천시스템] 개인화 추천시스템에서 고객 제품 리뷰가 사회적 실재감에 미치는 영향 (0) | 2022.03.07 |
| [추천시스템] 양방향 인재매칭을 위한 BERT 기반의 전이학습 모델 (1) | 2022.02.25 |
| [추천시스템] 추천 수량과 재 추천을 고려한 사용자 기반 협업필터링 추천시스템 (0) | 2022.02.21 |
| [추천시스템] 추천시스템 기법 연구동향 분석 (0) | 2022.02.09 |




댓글