📚 논문 정보

이륜경, 정남호, & 홍태호. (2019). 딥러닝을 이용한 온라인 리뷰 기반 다속성별 추천 모형 개발. 정보시스템연구, 28(1), 97-114.
📚 요약
본 연구의 전체 프레임워크는 아래와 같다.
데이터 수집 :
트립어드바이저에서 한국,미국,프랑스,중국 주요 도시의 레스토랑의 리뷰 510,000건을 수집하여 사용하였다. 평점 데이터도 함께 수집하였는데, 이 연구에서는 평점이 3점인 경우는 grey sheep 문제 등으로 인해서 제외하였다. 전처리를 진행하고 최종적으로 260,000개가량의 리뷰를 사용하였다.
토픽의 갯수는 위 그래프와 같이 혼잡도를 고려해서 총 200개로 선정하였다. 200개 토픽 중에서 상위 5개 키워드를 이용해서 속성(=토픽)들의 명칭을 지정했다.
<표3>과 같이 각 속성(=토픽)의 키워드를 도출하고, 각 토픽의 키워드와 매칭 해서 사용자 리뷰를 분류한다. 전체 리뷰를 속성별로 분류한 결과는 표 4와 같다. 위의 6개의 리뷰를 조합해서 총 63개의 쌍의 리뷰를 만들었는데, 일부는 해당 조합이 존재하지 않거나 리뷰의 수가 적은 문제가 발생한다.
따라서 분류한 그룹의 리뷰 수가 너무 적은 것들을 제외하고 분석을 진행하였다. 이 과정이 자의적일 수는 있지만 본 연구에서는 이 부분을 합리적으로 잘 설명하였다.
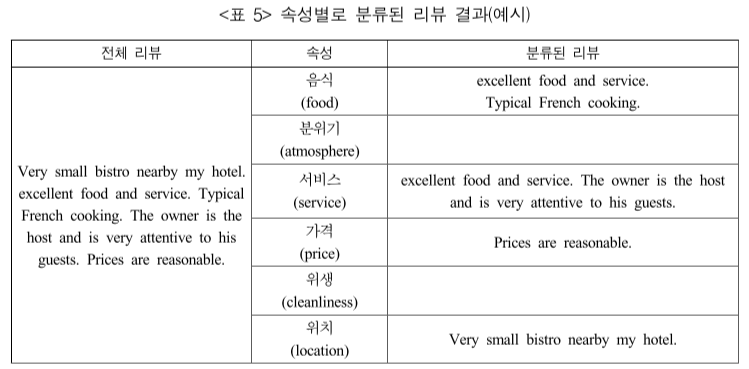
위의 예시 리뷰와 같이 4가지 속성에 대한 키워드만 있는 경우, 4개의 속성에 대해서만 분류를 수행한다.
예측 과정에서는 KNN, SVD, Restricted Boltzmann Machines을 사용했다. 실험 결과 전반적으로 딥러닝 기반 PBM 모형의 오차가 적게 나타났다.
📚 장점 및 의의
• LDA 분석은 대규모 텍스트에서 주제를 뽑아낼 수 있다는 점에서 매우 유용한 기법이지만, 분석 과정에서 연구자의 판단이 많이 개입되기 때문에 이에 대한 비판도 존재한다. 이 연구에서는 단순히 LDA를 descriptive 하게 사용하지 않고 적절하게 잘 활용하였으며 분석 과정에 대한 설명도 합리적으로 제시했다고 생각한다.
• 추천시스템 개발 과정에서 여러 가지의 속성을 고려하는 연구는 쉽게 찾을 수 있다. 이런 연구에서는 주로 주어진 정형 데이터를 사용하여 이를 평점과 함께 반영하여 성능을 개선시킨다. 하지만, 연구에서는 변수로 사용할 여러 속성을 비정형 텍스트 데이터에서 추출하였는데, 이 아이디어가 굉장히 참신하다고 생각했다. LDA와 다속성 고려 추천 시스템은 모두 기존에 알던 개념이었는데 이 연구에서는 이를 적절하게 융합하여 사용하였다는 점에서 배울 점이 많은 창의적인 연구라는 생각이 들었다.
📚 한계점 및 추가 연구 아이디어
• 이 연구에서는 평점 3점인 리뷰를 제외하고 분석을 진행하였다. 중립적인 평점을 남기는 경우 명확한 선호도를 측정하기 어렵고 grey sheep 유저인 경우일 수도 있어서 전체 추천시스템의 정확도를 떨어뜨릴 수 있기 때문이다. 이 연구에서는 이에 대한 설명을 충분히 제공하였으나, 보다 정교한 방식으로 평점 3점인 리뷰들을 추천 시스템에 포함시킬 수도 있었을 것이라는 아쉬움이 들었다. (ex. 평점 3점인 리뷰의 각 토픽에 대한 감성 지수 계산하여 추천)
• 이 연구에서는 다속성별 추천을 위해서 LDA를 실시한 각 특성을 사용하였다. 하지만 실제 트립어드바이저에는 해당 속성별 고객의 평점이 존재하지 않으며 전체 평점만 존재한다. 이 연구에서는 사용자 A가 평점 5점으로 작성한 리뷰가 위생, 서비스, 가격 특성을 가지고 있다면 각 요소에 대해서 모두 5점으로 점수를 부여한다. 하지만 리뷰 작성자들이 일반적으로 여러 요소를 고려해서 종합적인 평가를 내린다는 점을 고려할 때, 실제 사용자의 경험 및 의도에서 왜곡이 발생할 가능성이 있다. (논문 본문에서도 지적한 부분이다)
'논문 리뷰 > 추천시스템' 카테고리의 다른 글
| [추천시스템] Feature-level Deeper Self-Attention Network for Sequential Recommendation (0) | 2022.04.10 |
|---|---|
| [추천시스템] 개인화 추천시스템에서 고객 제품 리뷰가 사회적 실재감에 미치는 영향 (0) | 2022.03.07 |
| [추천시스템] 양방향 인재매칭을 위한 BERT 기반의 전이학습 모델 (1) | 2022.02.25 |
| [추천시스템] 추천 수량과 재 추천을 고려한 사용자 기반 협업필터링 추천시스템 (0) | 2022.02.21 |
| [추천시스템] 추천시스템 기법 연구동향 분석 (0) | 2022.02.09 |




댓글