📚 신경망 기본 구조 및 용어 설명
✅ 입력층, 은닉층, 출력층

| 설명 | |
| ① 입력층(Input Layer) | - feature에 대한 정보(독립변수)를 입력받고 다음 층으로 전달한다. - 입력층 노드의 수 = 독립변수의 수 |
| ② 은닉층(Hidden Layer) | - 종속변수를 예측하는데 중요한 특성이나 패턴을 추출한다. - 입력 받은 데이터를 활성화 함수(activation function)를 거쳐서 변환해서 전달함 - 은닉층 노드의 수 = 사용자가 설정 |
| ③ 출력층(Output Layer) | - 종속변수의 예측치를 출력한다. 회귀의 경우 종속변수의 값을 그대로 출력하고 분류는 각 종속변수 클래스의 확률을 출력함 회귀문제 : 출력 노드의 수 = 1 분류문제 : 출력 노드의 수 = 종속변수의 클래스 수 |
• 입력층과 출력층의 수는 1개로 고정이고, 그 사이에 존재하는 여러 개의 은닉층의 수는 분석가가 직접 결정한다.
• 각 레이어는 노드로 구성되어 있고, 각 노드들의 연결은 weight connection으로 불린다. 한 신경망에 존재하는 파라미터의 개수는 weight connection의 수와 같다.
• 경사하강법을 사용해서 비용함수를 최소화하는 방향으로 각 파라미터들을 최적화한다.
• 딥러닝 알고리즘은 일반적으로 비정형 데이터(텍스트, 오디오, 이미지 등)를 다루는 도메인에서 머신러닝 알고리즘보다 성능이 좋다. 이는 딥러닝이 은닉층을 가지고 있기 때문인데 보다 중요한 특징들을 잘 추출할 수 있기 때문이다.
• 위와 같이 기본적인 입력,은닉,출력층 구조를 가지고 있는 신경망을 FNN(Feed Forward Network), ANN, MLP라고 부른다.
✅ 편향 노드(Bias Node)
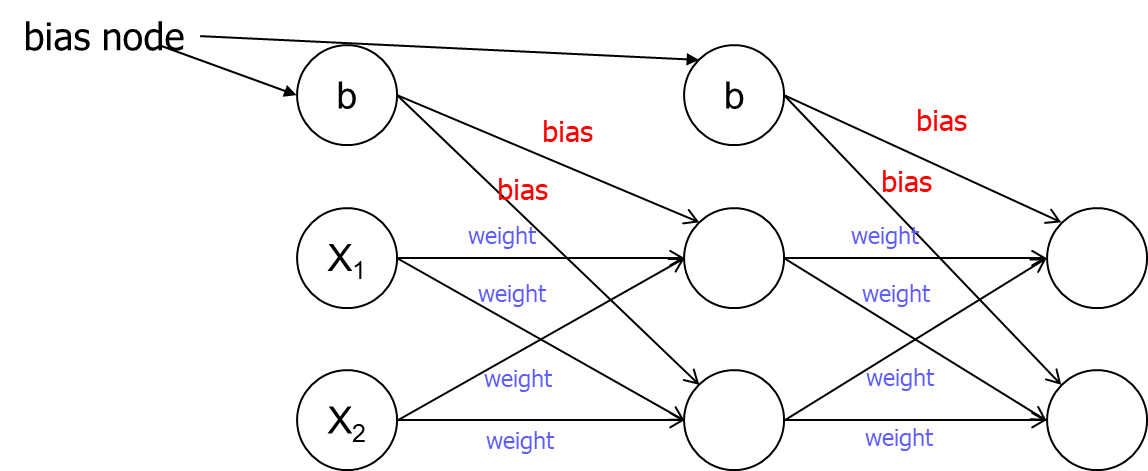
• 편향 노드는 입력층과 은닉층(layer)에 하나씩 존재하는데 출력층에는 존재하지 않는다.
• 선형회귀 모델의 intercept와 비슷한 역할을 함. 값을 입력받지 않고 1의 값을 출력한다. 편항 노드의 값에 weight가 곱해져서 다음 층으로 전달됨
✅ 신경망의 비용함수
• 회귀문제는 MSE를 사용하고, 분류문제는 교차엔트로피(Cross Entropy)를 사용함

yi는 각 관측치의 실제 종속변수 값이며, 0 또는 1이다. p(yi=1), p(yi=0) 부분은 분류 신경망 모델을 통해서 추출되는 확률 값이 들어간다.
📚 예시 : 회귀 문제
• 종속변수 : 연속형 변수 Y / 독립변수 : X1, X2
은닉층 1개, 은닉 노드 2개
은닉 노드 활성화 함수 : sigmoid function으로 설정


| 샘플 | X1 | X2 | y |
| 1 | 34 | 5 | 5 |
| 2 | 25 | 5 | 2.5 |
| 3 | 30 | 2 | 4 |
| 4 | 38 | 20 | 3 |
| 5 | 44 | 12 | 3.3 |
위와 같은 샘플 데이터가 있다고 할 때, 처음 입력되는 값은 X1=34, X2=5이다.

H1, H2가 입력받는 값을 계산하면 아래와 같다.

은닉 노드는 입력받은 값을 활성화 함수를 거쳐서 변환해서 출력한다.

따라서, H1과 H2 노드가 활성화 함수를 거쳐서 출력하는 값은 아래와 같음

최종 출력 노드인 O1이 입력받는 값은 다음과 같다.
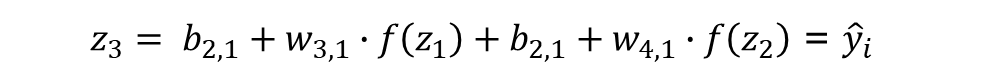
이 문제는 회귀 문제이기 때문에, 출력 노드는 입력받은 값을 그대로 출력해서 예측값을 도출한다.
그리고 이 예측값을 실제 값과 비교하면서 MSE를 최소화하는 모형의 파라미터(bias, weight)를 탐색한다.
📚 예시 : 분류 문제
종속변수 : 범주형 변수 Y / 독립변수 : X1, X2, X3
은닉층 1개, 은닉 노드 2개인 모델로 설정

출력층의 i 번째 출력 노드에서 최종적으로 출력되는 값은 아래와 같이 표현할 수 있음

Zi는 i 번째 출력 노드에 입력되는 값이고, S(Zi)는 i 클래스로 분류될 최종 확률을 의미함. 여기서 e는 자연로그를 의미함.

📚 활성화 함수 (Activation Function)

📌 은닉노드에서 비선형 활성화함수를 사용하는 이유
① 선형 함수로는 독립변수와 종속변수 사이의 다양한 관계를 파악하기가 어렵다.
선형 함수는 입력에 따라서 출력이 상수배만큼 변하는 함수를 나타낸다. f(x) = Wx + b 와 같이 나타낼 수 있다.
인공신경망은 성능 향상을 위해서 은닉층을 계속 추가하는데, 선형함수를 은닉층에 계속해서 쌓게 되면 비선형 관계를 파악하기 어렵다. f(x)=Wx 라는 선형 함수가 있을 때, 은닉 층을 두개 더 추가하면 y(x)=f(f(f(x)))로 나타내는데 이를 식으로 표현하면 W3x이고 여기서 W3은 상수이기 때문에 결국 선형 식과 동일하다. 즉, 선형 함수는 아무리 겹치더라도 은닉층을 1회 추가한 것과 차이가 없다.
② 경사하강법을 사용해서 최적 파라미터를 구하는 과정에서 활성화 함수를 미분이 쉬워야 더 경사 계산이 빠르다.
딥러닝은 학습 속도가 중요하기 때문에 미분 편의성이 중요하다.
• 같은 층에 존재하는 노드들은 같은 형태의 활성화 함수를 사용해야 한다.
• 출력 노드에는 종속변수 형태에 따라서 활성화 함수 존재 여부가 달라진다.
회귀 문제는 활성화함수가 존재하지 않고, 입력받은 값을 그대로 출력한다. z3 = f(z3)
분류문제는 주로 softmax 함수를 사용한다.
✅ 활성화 함수의 종류
📌 Sigmoid 함수 (=Logistic 함수)
• 0~1 사이의 값을 출력한다.
• sigmoid 함수는 은닉층에는 잘 사용하지 않는다. 아래그림에서 시그모이드 함수의 출력값이 0 or 1에 가까워지면 그래프의 기울기가 완만해지는 것을 알 수 있다(주황색 구간). 따라서 신경망의 레이어가 많아질 경우 vanishing gradient 문제를 발생한다. 즉, 역전파 과정에서 앞쪽 파라미터에 기울기가 제대로 전파되지 않는다.
• sigmoid함수는 출력값이 원점 중심이 아니라 0.5를 중심이며, 항상 양수 값을 출력한다. 따라서 입력 가중치보다 출력 가중치의 합이 커질 가능성이 있다. 이를 편향 이동(bias shift)라고 하며, 각 레이어에서 전파가 될 때 마다 분산이 계속 커져서 활성화 함수의 출력이 0이나 1로 수렴하게 되어 기울기 소실 문제가 나타난다.


def sigmoid(x):
return 1/(1+np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.plot([0,0],[1.0,0.0], ':')
plt.title('Sigmoid Function')
plt.show()
📌 Hyperbolic Tangent (tanh)
• 시그모이드 함수와 형태는 유사하지만 -1~1 사이의 값을 출력한다.
• 시그모이드 함수와 달리 0을 중심으로 하고, 0 부분에서 기울기가 가파르다. sigmoid 보다는 경사 소실 문제가 적기 때문에 은닉층에서 더 많이 사용된다.
• 텍스트나 시퀀스 데이터 다룰 때 많이 사용됨
• sigmoid 함수와 달리 원점 중심이기 때문에 편향 이동은 일어나지 않지만, 입력의 절대값이 크면 -1이나 1로 수렴하게 되어 기울기 소실 문제가 발생할 수 있다.


x = np.arange(-5.0, 5.0, 0.1) # -5.0부터 5.0까지 0.1 간격 생성
y = np.tanh(x)
plt.plot(x, y)
plt.plot([0,0],[1.0,-1.0], ':')
plt.axhline(y=0, color='orange', linestyle='--')
plt.title('Tanh Function')
plt.show()
📌Relu (Rectified Linear Unit)
• 두 개의 선형 함수인 직선 두개를 결합한 비선형 함수이다. 별도의 연산이 필요하지 않은(max(0,z)로 단순함) 선형 함수 두개의 결합 형태이기 때문에 계산과 미분이 쉽고 빠르다. 선형적 성질은 모델 최적화에 유용하기 때문에, 현재 가장 널리 사용되고 성능도 좋다.
• 0보다 작으면 0으로 출력하고, 0보다 크면 입력값인 z를 그대로 출력한다.
• 주로 이미지 데이터 다룰 때 많이 사용됨.
• 일반적으로 ReLU를 먼저 시도해보고, 그 뒤에 ReakyReLu, ELU같은 변형 함수를 사용하는 것을 권고
• 문제점 : 입력값이 음수이면 기울기가 0이 되고, 이 뉴런은 회생이 어렵다. 이를 dying ReLU라고 한다.


def relu(x):
return np.maximum(0, x)
x = np.arange(-5.0, 5.0, 0.1)
y = relu(x)
plt.plot(x, y)
plt.plot([0,0],[5.0,0.0], ':')
plt.title('Relu Function')
plt.show()
📌 Leaky Relu
• z > 0이면 z를 반환하고, z < 0이면 ε를 곱한 z를 반환한다.
• ReLU와 달리 입력값이 음수이면 0을 반환하는 것이 아니라 0.001과 같은 매우 작은 수를 반환해서 기울기가 0이 되는 것을 방지한다.



a = 0.01
def leaky_relu(x):
return np.maximum(a*x, x)
x = np.arange(-5.0, 5.0, 0.1)
y = leaky_relu(x)
plt.plot(x, y)
plt.plot([0,0],[5.0,0.0], ':')
plt.title('Leaky ReLU Function')
plt.show()
📌 Softmax 함수
소프트맥스 함수는 주로 다중분류 문제에서 출력층의 활성화 함수로 자주 사용된다.
x = np.arange(-5.0, 5.0, 0.1) # -5.0부터 5.0까지 0.1 간격 생성
y = np.exp(x) / np.sum(np.exp(x))
plt.plot(x, y)
plt.title('Softmax Function')
plt.show()
📚 신경망의 경사하강법 (Gradient descent)
경사하강법은 업데이트할 때 사용되는 데이터 포인트의 양에 따라서 세 가지로 나눌 수 있다.
✅ 1. Batch Gradient Descent
• 한 번 파라미터를 업데이트 할 때, 학습 데이터에 존재하는 모든 데이터를 다 사용하는 방법
• 모든 관측치를 사용하면 시간이 오래 걸리고 많은 메모리가 필요하다.

✅ 2. Stochastic Gradient Descent
• 한 번 파라미터를 업데이트할 때, 학습 데이터에 존재하는 하나의 관측치를 랜덤하게 선택해서 업데이트 함
• 업데이트에 소요되는 시간은 짧지만, 선택한 하나의 관측치가 다른 관측치의 특성을 잘 반영하지 못한다는 단점이 있다.
따라서 업데이트 할 때마다 방향이 달라지기 때문에 비용함수의 최저 지점까지 시간이 오래 걸린다.

✅ 3. Mini-batch Gradient Descent
• 위의 두 방법을 보완하여 만든 방법이 미니배치 방식으로, 대부분의 신경망에서 사용된다.
한 번 업데이트할 때 전체 학습 데이터의 일부(mini-batch)를 사용한다. 다음 업데이트 시에는 또 다른 mini-batch를 사용해서 비용함수의 값을 구한다. 여기서 일부는 1~n까지의 범위.
• 미니배치의 수도 하나의 하이퍼 파라미터이고, 2의 제곱수인 32, 64, 256 등을 주로 사용한다.

📚 Optimizer (옵티마이저)
일반적인 경사하강법을 이용한 가중치 업데이트 식은 아래와 같이 표현할 수 있다.

하지만 실제 신경망에서는 이러한 방식으로 경사하강을 하지 않는데 우선은 속도가 매우 느리기 때문이다. 앞서도 언급했던 것처럼 딥러닝에서는 학습 속도가 매우 중요한 요소 중 하나이다. 또한, Saddle point(안장)을 벗어나기가 어렵다.


일반적인 딥러닝 모델의 비용함수는 위와 같은 입체적인 형태로 나타나는데, 위 그림의 Saddle point(빨간 점)에서의 기울기는 0 이다. 따라서 위의 기본 업데이트 식을 사용할 경우 맨 우측 항이 0이 돼서 업데이트가 이루어지지 않는다.
이렇게 새들 포인트를 벗어나지 못하는 이유는 다음과 같다.
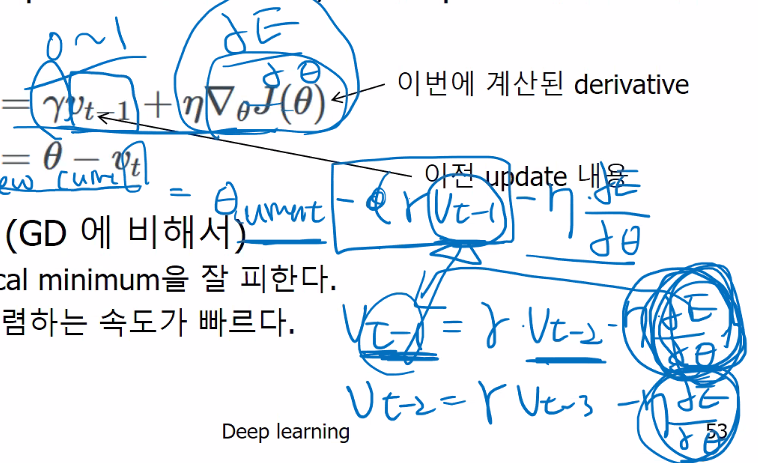
① 이전 단계들의 업데이트 내용을 반영하지 않는다. 즉, t단계를 업데이트 할 때, t-1 시점부터의 정보만 사용하고 t-2 이전의 정보는 사용되지 않는다.
② learning rate의 값이 업데이트 횟수와 상관없이 고정되어 있다. 아래의 그림에서 우측에서 경사하강을 시작할 때, 초기 단계에서는 학습률이 높은것이 유리하고 갈수록 학습률이 낮아지는게 유리함.


따라서 이러한 기본 업데이트 방식의 문제를 해결하기 위해 여러 형태의 optimizer가 제안되었다. 여기서 optimizer는 경사하강법으로 비용함수를 최소화하는 가중치(파라미터)의 값을 찾는 역할을 하는 것으로, 기본적인 경사하강법 업데이트 방법을 수정 또는 보완한 방식을 의미하는 용어이다. 대표적인 optimizer의 종류는 다음과 같다.
✅ 옵티마이저 종류
📌 Momentum
• 이전 업데이트 정보를 현재 단계 업데이트에 사용한다. 이를 통해서 saddle point를 더 잘 벗어날 수 있고 속도가 빨라진다.
• 최근에는 모멘텀 외 다른 방식을 더 많이 사용함

📌 Adagrad (Adaptive Gradient)
• 기본 경사하강법은 업데이트 횟수와 상관 없이 학습률이 고정되어 있음. Adagrad는 지금까지 업데이트 된 정도를 고려하고, 지금까지 업데이트가 많이 이루어진 파라미터는 학습률을 작게 가져간다.(learning rate decay)

원래 업데이트식에서 아래 초록색 부분만 분모로 추가됨. 입실론은 상수로 분모가 0이 되는것을 방지하기 위한 smmothing term이다.
gt 는 현재 단계에서의 경사값을 의미한다.


분모에 있는 Gt,ii 부분은
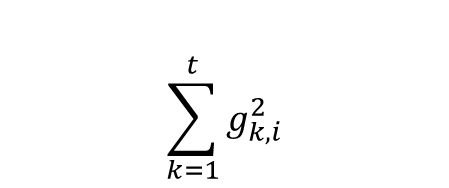
를 의미한다. 즉 현재까지 경사값들의 제곱의 합을 의미함
제곱해서 더하기 떄문에 분모가 계속 증가하기 때문에 곱해지는 전체 텀의 값은 작아져서 특정 값으로 수렴하기가 쉬워진다.
📌 RMSprop (Root Mean Square Propagation)
• Adagrad는 곱해지는 텀이 갈수록 0에 가까워지기 때문에 수렴지점 근처에서 업데이트가 일어나지 않는 현상이 발생할 수 있다.
이러한 단점은 분모의 값이 경사를 제곱해서 더한 값이기 때문에 발생한다. 따라서 합계가 아니라 이동평균으로 분모를 계산한것이 RMSprop 이다.
📌 Adam
• 모멘텀과 RMSprop을 결합한 방식
📚 Back Propagation : 역전파
유튜브 테디노트 TeddyNote 님이 설명해주신 내용을 첨부합니다. 기본적인 머신러닝에 대한 설명이 상세하게 잘 되어 있어서 많이 참고하는 유튜브입니다. 해당 채널에서 자세한 영상 확인하실 수 있습니다.
✔ Back Propagation
✔ 경사 소실 : Gradient Vanishing
📚 Reference
• 연세대학교 디지털사회과학센터(CDSS) 파이썬을 활용한 딥러닝 기초 워크숍, 이상엽 교수님
• 유튜브 테디노트 TeddyNote 님 채널 (https://www.youtube.com/channel/UCt2wAAXgm87ACiQnDHQEW6Q)
'머신러닝, 딥러닝 > 딥러닝' 카테고리의 다른 글
| CNN 사전학습 모델 - LeNet / AlexNet / VGGNet / InceptionNet / ResNet / DenseNet / MobileNet / EfficientNet (0) | 2022.01.17 |
|---|---|
| RNN(순환신경망) 기본 (0) | 2022.01.14 |
| CNN(합성곱 신경망) 기본 (0) | 2022.01.13 |
| 딥러닝 기본 개념 - 비용함수, 경사하강법, 규제 (1) | 2022.01.10 |
| 딥러닝 기본 용어 정리 (0) | 2021.10.25 |




댓글