📚 DID
✅ 개요
DID는 시간의 흐름에 따른 treatment 그룹의 변화를 conterfactual인 control 그룹의 변화와 비교해서 파악한다.

위의 potential outcome framework 플로우 상에서 DID를 사용하는 조건을 살펴보면 다음과 같다.
• 완전 무작위 실험이 불가능할 때
• treatment와 control 그룹이 둘 다 관찰 가능할 때
• longitudinal data 일 때
• parallel trend 가정을 만족할 때

위 그림에는 1,2,3,4 subject에 대해서 각각의 두 개의 행은 시간의 흐름에 따른 변화를 나타낸다. 1,2는 treatment 이고 3,4는 control에 해당한다. 통제 집단에서 시간의 흐름에 따라서 1과 0씩 값이 증가했으며 이는 평균 0,5가 증가했음을 의미한다. 따라서 처치 집단인 1,2에 대해서도 통제집단의 평균 추세와 동일하게 0.5씩 시간의 흐름에 따라서 값이 증가한다고 가정한다. 이것을 Parallel tren assuption 이라고 한다. 이 가정을 위해서는 treatment와 control의 모든 변수가 동일할 필요는 없고 시간의 흐름에 따른 변화만 동일하면 된다. 만약 이 가정이 만족되지 않으면 매칭을 통해서 두 집단을 유사하게 만들어서 분석을 진행할 수도 있다.
DID에서 구하는 것은 treatment 집단 내의 효과인 ATET(Average Treatment Effect in Treatment group)이다. 데이터 전체에서의 treatment의 효과인 ATE(Average Treatment Effect)를 계산하기 위해서는 parallel trend 가정보다 강한 가정이 필요하다. 즉 treatment와 control 그룹이 모든 면에서 동일해서, control 그룹에 대해서 treatment가 이루어졌을 때에도 동일한 결과가 관측되었을 것이라는 가정이 필요하다. 연구에 따라서 ATET만으로도 결론 도출에 충분한 경우도 있다. 따라서 ATET와 ATE를 명확하게 구분하는 것이 중요하다.
📚 Synthetic Control

컨트롤 그룹의 데이터를 재조합(=combination)해서 treatment 그룹의 conterfactual 데이터를 예측하는 방법. treatment 그룹의 데이터(빨간색)을 생성하는 방법은 다음과 같다.
(1) control 그룹에서 treatment 이전 시점의 데이터로(각각 1,0), treatment 그룹에서 treatment 이전 시점의 데이터를 계산하는 식을 구한다. 우측 가장 위의 식처럼 식을 유도할 수 있다.
(2) 앞에서 구한 식을 이용해서,
control 그룹에서 treatment 이후 시점의 데이터로, treatment 그룹에서 treatment 이후 시점의 데이터를 계산한다.
synthetic control 방식은 DID와 다르게 parallel trend 가정이 만족되지 않더라도 통제 변수의 샘플을 잘 조합하면 treatment의 샘플을 잘 예측할 수 있다.
📚 DID vs Synthetic Control
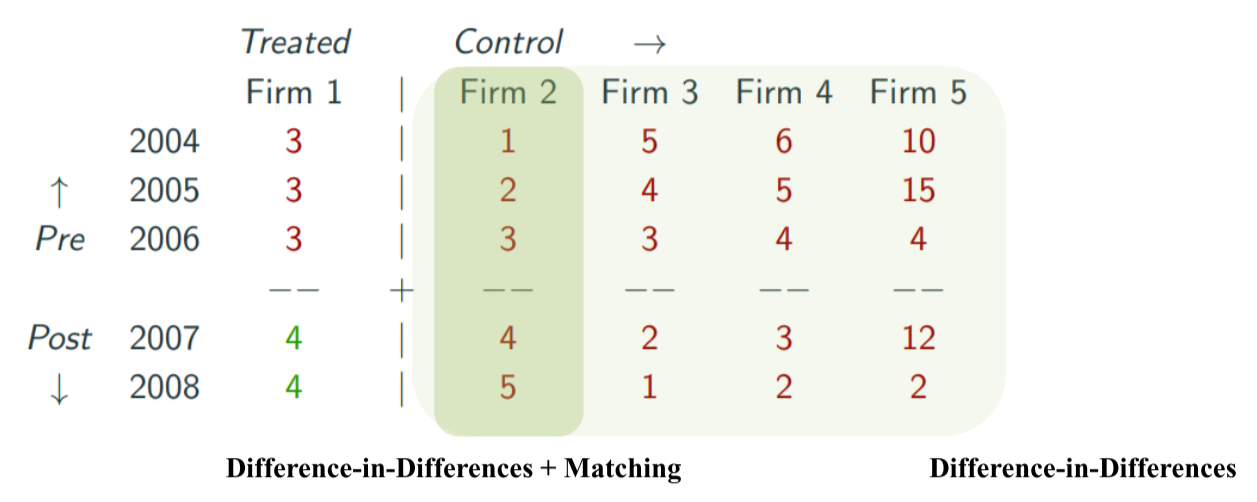
위와 같이 처치 집단과 통제 집단이 있을 때 DID는 4가지 통제집단의 샘플을 모두 활용한다. 하지만 paralle trend 가정이 만족되지 않는 경우에는 가장 가정을 만족할만한 firm2의 데이터만 선택해서 매칭을 한 후에 분석을 진행한다.
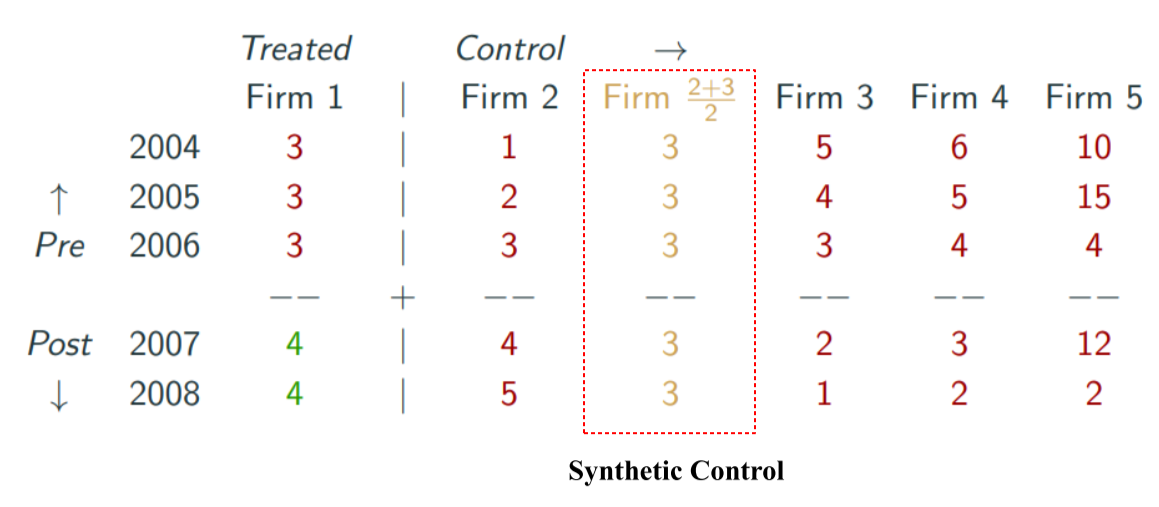
synthetic control은 적절한 통제집단의 샘플이 없을 경우에 새로운 샘플을 생성한다. 위의 예시 데이터의 경우에는 firm2, firm3를 적절하게 조합(combination)하면 treatment 집단과 유사한 가상의 통제집단을 만들 수 있다.
📚 Reference
• Korea Summer Workshop on Causal Inference 2022, Boot Camp for Beginners, 준실험 분석방법론
'데이터 분석 > 인과 추론' 카테고리의 다른 글
| Fixed Effect vs Random Effect (1) | 2022.07.03 |
|---|---|
| Difference-in-Differences (이중차분법) (1) | 2022.06.27 |
| 무작위 실험 (Random Assignment), 준실험 ( Quasi-experiment) (0) | 2022.06.27 |
| Matching & Weighting (0) | 2022.06.27 |
| 회귀 분석 (Regression) (0) | 2022.06.26 |




댓글