📚 도구변수 개념
*Korea Summer Workshop on Causal Inference 2022의 부트캠프 내용과 기타 구글링 결과를 참고하여 작성하였습니다.
✅ 독립변수와 Error Term의 관계 (feat. selection bias)
• 회귀분석의 기본 가정 : conditional independence
→ 통제변수가 있는 상황에서 독립변수(X)와 error term의 상관관계가 없어야 한다.
(하지만 완벽하게 통제된 실험 연구가 아니라, 2차 데이터를 수집해서 분석하는 경우에는 이러한 조건을 충족시키기 어렵다)
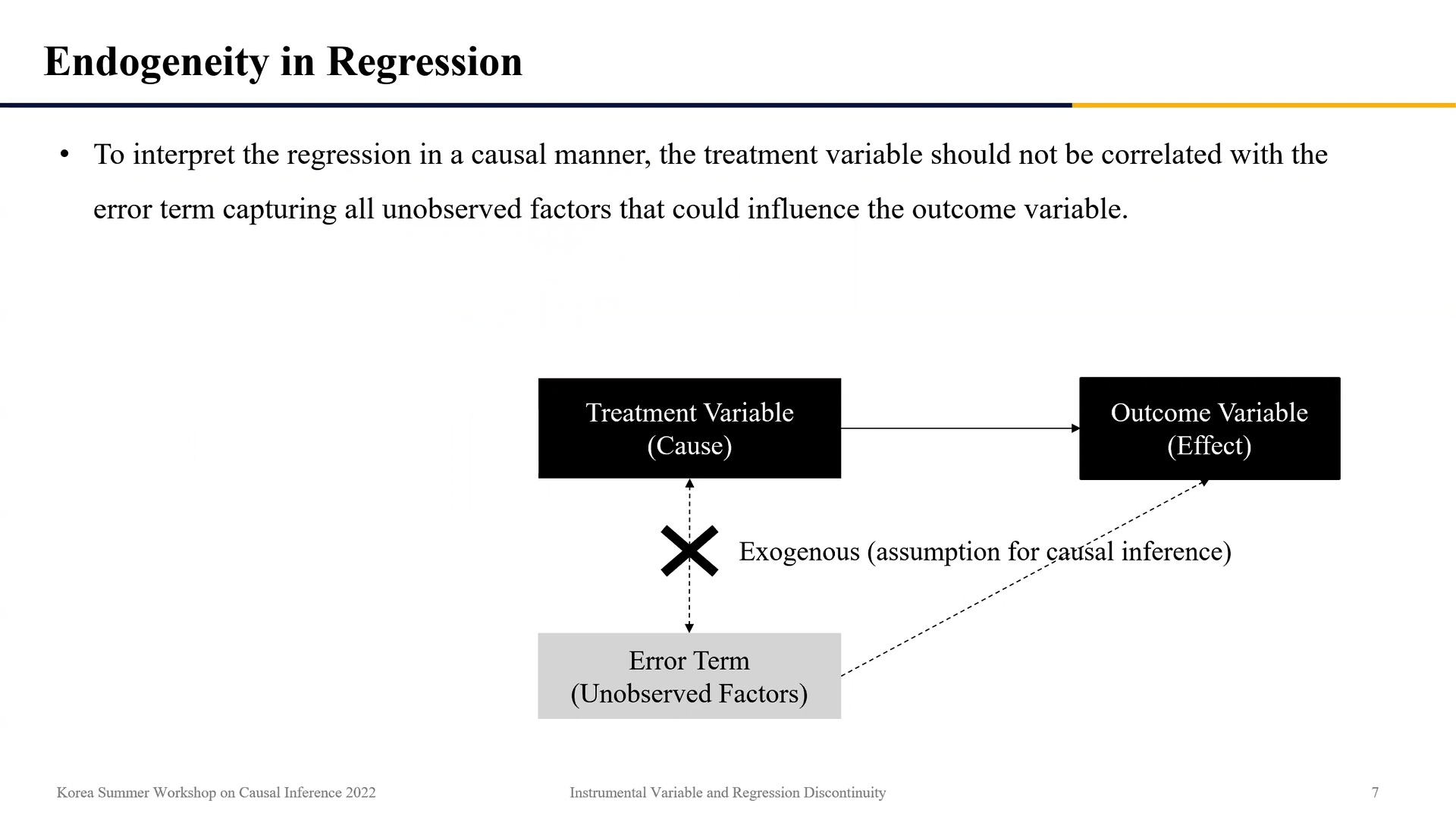
treatment group에서 treatment가 없었을 때를 의미하는 counteractual와 control group의 차이를 selection bias라고 한다. 관찰되지 않은 요인에 의한 selection bias는 모두 회귀식의 ε(=error term)에 담긴다. 즉, error term은 종속변수에는 영향을 미치지만 분석에서 관찰하지 못한 요인들이 모두 포함하는 부분이다. selection bias가 error term에 포함되어 있기 때문에 error term은 treatment와 상관관계를 가진다. 즉, 독립변수와 error term이 상관관계가 있다는 것은 selection bias가 있음을 의미한다. 이러한 상관관계가 없어야 회귀 분석의 결과를 인과관계로 해석할 수 있다.
위의 그림에서 독립변수(treatment variable)와 error term이 exogenous(외생적) 한 관계여야 인과관계를 보장할 수 있다. 하지만 실제로 저 사이에는 indogenous 한 요소와 exogenous 한 요소가 섞여있는데, 명확한 인과 추론을 위해서는 indogenous 한 부분을 추려내야 한다.

도구변수는 말 그대로 exogenous와 indogenous 요소를 분리하는 도구적인 역할을 수행한다. 도구 변수를 이용하여 treatment var에 대해서 exogenous한 부분만 예측한다면, 나머지 부분을 treatment var가 종속변수에 미치는 인과관계를 해석할 수 있다. 독립변수에서 도구 변수로 설명되지 않는 부분이 selection bias에 해당된다.
✅ 도구변수의 조건

1. Relevance Condition :
도구변수는 독립변수에서 exogenous한 부분만 예측하고 indogenous 한 부분을 발라내는 것이기 때문에, 기본적으로 도구변수는 독립변수를 설명할 수 있어야 한다. 즉 first-stage에서 도구변수의 계수가 유의해야 한다.
2. Exclusion restriction :
도구변수가 종속변수에 영향을 미치지만, 반드시 독립변수를 통해서만 종속변수에 영향을 미친다. 즉, 도구변수는 original equation의 y에는 영향을 미치지만, 오차항인 u와는 상관관계가 없어야 한다. 가장 중요한 가정사항이면서 검증하기가 까다롭다.
3. Exogeneity of IV :
도구변수가 종속변수에 대해서 어떠한 교란요인(confounder)도 가지고 있지 않아야 한다. 다른 외부 변수가 IV와 종속변수에 영향을 미친다면 교란요인이 있는 것. 즉, first-stage에서 도구변수와 error term의 상관관계가 없어야 한다.
📚2SLS : 2 Stage Least Squares
• 2SLS : 도구 변수를 통해서 exogenous 한 부분만 예측하고, 이 부분만을 이용해서 종속변수를 예측하는 방식. 즉 endogenous 한 부분은 버려서 selection bias를 없앤다.
수식으로 살펴보면 다음과 같다.

[1]에서 X(독립변수)와 u(에러 텀)이 상관관계가 있는 상태이다.
[2] z(도구변수)를 이용하여 X를 예측한다. 이를 통해서 X에서 exogenous 한 부분만 예측할 수 있다. 이 식에서 v는 error term에 해당하고 독립 변수에 대해서 설명 불가능한 부분이므로 endogenous 부분을 의미한다. 반면 a0 + a1z는 독립 변수에 대해서 설명 가능한 부분이라서 exogenous 한 부분을 의미한다.
[3] x^은 도구변수로 설명 가능한 부분을 의미한다. 즉 설명이 안 되는 부분인 residual을 제외하고 exogenous 한 부분만을 의미한다.
[4] x^을 독립변수로 이용하여 종속변수에 대해서 다시 예측을 진행한다. 도구변수의 기본 사항들을 만족한다면 x^ 변수는 외생적인 변수이므로 내생성 문제가 없다. 따라서 x^ 과 u(error term)은 상관관계가 0이어야 한다. 이를 식으로 풀어서 증명하자면 아래와 같다.
second stage에서 x^은 외생 변수이기 때문에 error term과 상관관계가 없어야 한다. [3]에서의 식을 이용하여 x^을 나타내면 아래와 같다.

여기서 cov(a0, u) 와 cov(a1z, u)를 분리해서 계산하면

첫 번째 항의 경우 상수 특정 상수와 error term의 상관관계 이므로 0이 된다. 두 번째 항은 [2]에서 도구변수의 기본 요건이 만족했기 때문에 0 이 된다. (도구변수의 기본 가정 사항을 만족시키는 것이 중요하다)
따라서 second stage에서 x^의 영향은 온전히 인과관계로 볼 수 있다.
📚도구변수 사용 사례
도구변수는 개념적으로는 명확하지만 실제로 연구에서 사용하기에는 쉽지 않다.
지리적인 요소를 고려하면 도구 변수 사용이 좀 더 용이함.
독립변수보다 조금 더 상위 레벨(macro level) 또는 동일한 레벨의 개념/트렌드를 이용함
📌1. 사유재산제도와 계약제도가 GDP에 미치는 영향
Acemoglu, D., Johnson, S., & Robinson, J. A. (2001). The colonial origins of comparative development: An empirical investigation. American economic review, 91(5), 1369-1401.

• 독립변수 : 사유재산권 & 계약 제도
• 종속변수 : GDP
• 도구변수 :
(1) 식민지 시기 해당 지역의 정착 인구의 사망률 / 식민지 시기 해당 지역 원주민의 인구
→ 정착인의 사망률이 높고 원주민 인구가 높으면 상대적으로 제도의 발전보다는 단순 자원 착취에 중점을 뒀을 것이라는 사회경제학적 가정에 기반
(2) 영국의 식민지배 여부
→ 영국의 식민 지배에 따라서 법 제도 형성에 영향을 받음
📌2. 인터넷 보급이 혐오범죄에 미치는 영향
Chan, J., Ghose, A., & Seamans, R. (2016). The Internet and Racial Hate Crime. Mis Quarterly, 40(2), 381-404.

• 독립변수 : 인터넷 보급
• 종속변수 : 혐오범죄
• 도구변수 : 해당 지역 지형의 기울기(slope)
→ 지형이 험할수록 인터넷 보급률이 상대적으로 떨어짐. 지형의 기울기가 인터넷 보급률에는 영향을 미치지만, 혐오범죄에는 직접적인 영향을 미치지 않는다.
📌3. 모바일 앱 사용이 온라인 구매에 미치는 영향
Narang, U., & Shankar, V. (2019). Mobile app introduction and online and offline purchases and product returns. Marketing Science, 38(5), 756-772.

• 독립변수 : 모바일 앱 사용
• 종속변수 : 온라인 구매
• 도구변수 : 해당 지역의 기지국 숫자.
→ 그 지역의 기지국 숫자는 모바일 앱 사용에는 영향을 미치지만, 온라인 구매에는 직접 영향을 미치지 않음
📌4. ERP 도입이 통제 범위에 미치는 영향
Bloom, N., Garicano, L., Sadun, R., & Van Reenen, J. (2014). The distinct effects of information technology and communication technology on firm organization. Management Science, 60(12), 2859-2885.

• 독립변수 : ERP 도입 여부
• 종속변수 : 매니저의 통제 범위
• 도구변수 : ERP 기업인 SAP 본사와의 거리
→ 본사와의 지리적 거리가 가까울수록 지원/인맥 등등에 의해서 ERP 도입 가능성이 높다. 하지만 본사와의 거리가 통제 범위 확장에는 영향을 미치지 않는다.
📌5. 상위 레벨(macro level)의 개념을 도구변수로 사용한 사례

📌6. 동일 레벨(cohort)의 개념을 도구변수로 사용한 사례

📚 가정사항 확인
📌식별(identification) 문제
• 2SLS에서 일반적으로 도구변수는 내생변수의 수보다 많아야 하며, 식별 문제를 확인해야 한다. 도구변수 개수 = 내생변수 개수인 적도 식별(just identification)이거나, 도구변수 > 내생변수인 과다 식별(over identification)인 경우에만 2SLS를 사용할 수 있다.
• 아래 링크에서 R에서 가정사항 확인하는 법 참고
https://www.econometrics-with-r.org/12-3-civ.html
http://eclr.humanities.manchester.ac.uk/index.php/IV_in_R
📚 도구변수 사용 시 통제변수의 역할
• Reference : Korea Summer Workshop on Causal Inference 2022 - 도구변수 추정에서 통제변수의 역할 (https://www.youtube.com/watch?v=r-A7vNMoDfI)
2SLS 분석 시 first stage에서도 통제변수를 포함시켜야 한다. 우선 original equation과 내생성 조건을 아래와 같이 나타낼 수 있다.

인과 추론에서는 독립 변수 외에 좌항에 들어가는 변수들은 모두 독립변수의 영향을 확인하기 위한 보조적인 역할을 수행한다. 또한 인과 추론에서 treatment에 의한 차이를 비교하기 위해서는 그 외에 다른 요소들은 모두 같다고 가정한다(ceteris paribus). 따라서 통제변수를 명시적으로 회귀식에 포함시킨다면, treatment 외에 잠재적으로 종속변수에 영향을 미칠 수 있는 요인 중에서 해당 변수의 영향을 분리할 수 있다. 즉, 원래는 treatment 여부를 제외하고 treatment group과 control group이 동일해야 하지만, 통제변수를 포함시킨다면 통제변수를 제외하고 treatment group과 control group이 동일하면 된다. (가정사항이 어느 정도 완화된다)
위의 식처럼 original equation에서 통제변수 C가 포함된 상태에서는 error term에서 통제변수에 의한 효과가 분리되어 있다.

따라서 내생성 확인을 위해서 first-stage에서 exclusion/exogneity condition을 확인할 때, 조건부 C 확률이 추가된다. 즉, C인 상황에서 x와 u의 상관관계를 확인한다는 의미이다. 이렇게 C에 대한 조건부 식을 사용하면 이점이 있는데, 우선 모든 경우에 대한 상관관계를 계산하는 것보다 유리한 결과를 얻을 확률이 높아진다. (= 도구 변수의 영향력을 증명하는 과정에서 통제변수의 영향력을 배제할 수 있다)

마지막 줄에서 첫 번째 항은 first stage의 exclusion condition을 만족할 경우 0이 된다. 또한 두 번쨰 항은 C 조건부 상황에서 C와 u의 상관관계 이기 때문에, 상관관계가 0으로 나타난다. 따라서 내생성 문제가 없음을 보장할 수 있게 된다. ( Cor(β_0, u)은 상수이므로 0 )
📌통제변수를 포함시키는 않을 경우
first stage에서 통제변수를 포함시키지 않은 경우, 아래와 같은 가정 사항들을 만족해야 한다. (상단의 "도구변수 조건" 부분의 식과 동일)

second stage에서만 통제변수를 사용하고, first stage에서는 통제변수를 사용하지 않을 경우의 식은 아래와 같이 나타낼 수 있다.

x^을 추정하는 식에는 통제변수가 포함되어 있지 않지만(first stage), y를 예측하는 second stage 식에는 통제변수가 포함되어 있다. 따라서 위와 같은 가정사항을 만족해야 한다. 여기서 문제가 발생하는데, 화살표 부분에서 볼 수 있듯이 first stage에서 얻은 Cov(z,u)=0이, second stage의 조건인 Cov(z,u | c)=0를 반드시 만족한다고 볼 수 없다(왼쪽이 0이더라도 오른쪽이 0이 아닐 수 있다). 즉, first stage에서 통제변수를 고려하지 않으면, second stage의 추정치가 인과관계를 파악하는데에 적절하지 않을 수도 있음을 의미한다.
📚 Reference
Korea Summer Workshop on Causal Inference 2022, Bootcamp 4-1
https://www.youtube.com/watch?v=fL_SBIg-bnY&list=PLKKkeayRo4PV_6-nbBgmUNOSpG1OO49M3&index=12
'데이터 분석 > 인과 추론' 카테고리의 다른 글
| [R] Plm vs lm 모델의 R square 값 차이 (0) | 2022.10.02 |
|---|---|
| Panel Data 분석 - Fixed Effect / Random Effect (1) | 2022.08.26 |
| Fixed Effect vs Random Effect (1) | 2022.07.03 |
| Difference-in-Differences (이중차분법) (1) | 2022.06.27 |
| DID와 Synthetic Control 비교 (0) | 2022.06.27 |



댓글