📚 논문 정보

Chau, M., Li, T. M., Wong, P. W., Xu, J. J., Yip, P. S., & Chen, H. (2020). Finding People with Emotional Distress in Online Social Media: A Design Combining Machine Learning and Rule-Based Classification. MIS Quarterly, 44(2).
📚 요약
온라인 상의 게시글은 작성자의 metal health를 파악하는 데에 유용한 정보를 제공한다. 이 연구는 이러한 아이디어를 바탕으로 온라인 상에서 정서적인 불안감을 표출하는 사람들을 탐색하는 시스템인 KAREN을 제안한다. KAREN은 블로그 크롤러, ML분류기, 규칙기반 분류기, 결과 통합의 네 가지 파트로 구성되며, 이 연구는 새로운 시스템을 제안하는 design science method에 해당한다.

크롤러는 구글, 야후와 같은 블로그 플랫폼에서 주어진 키워드의 게시글을 검색하고 수집한다. 그리고 해당 포스트에 대해서 기본적인 텍스트 전처리를 진행한다. 해당 블로그의 포스트가 emotional distress를 드러내는지 판단하기 위해서 SVM model과 rule-based model을 결합한 분류기를 사용한다.

parsing을 완료한 텍스트를 LIWC의 71개 항목에 매칭하고 이것을 feature value(fi)로 사용한다. 위 식을 통해서 각 문서(포스트)의 feature value를 72차원 벡터로 생성한다. 그리고 Generic Algorithm을 사용하여 변수 선정을 진행하였다.

Rule-based 분류기를 만들기 위해서 전문가 의견을 바탕으로 정서적 불안과 관련된 어휘사전을 구축하였다. 해당 어휘사전은 정서적 불안감이 나타난 글을 바탕으로 생성하였기 때문에 보편적으로 사용되는 LIWC와는 차이점이 있다. 룰 기반 분류기는 기본적으로 문장마다 긍정/부정 분류를 진행해서 최종적으로 해당 문서의 감성을 분류한다. 하지만 정서적 불안이 굉장히 복합적인 요소에 의해서 나타난다는 점을 고려하여 단순히 긍/부정 문장을 카운트하는 방식이 아니라 다양한 요소에 가중치와 조건을 부여했다. 예를 들어, 대부분의 글에서는 처음 또는 마지막에 핵심적인 감성이 나타나는데, 이 연구에서는 self-reference 문장이 나타나는 블록의 감성을 최종 예측 스코어로 사용하였다. 또한 한 문서에서 나타나는 감정 변화의 횟수도 변수로 사용하였다.
이 연구에서는 정서적 불안을 보이는 포스트를 탐지하는 것이 중요하기 때문에 두 가지 분류기의 결과를 결합할 때, 하나라도 부정적인 포스트로 분류되면 최종 결과를 정서적인 불안이 있는 게시글로 분류하였다.
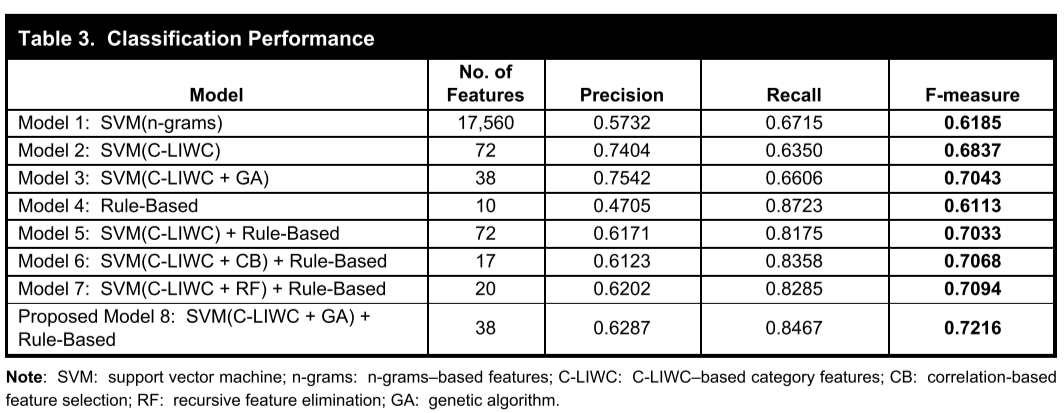
모델 평가는 두 가지 방식으로 진행하였다. 첫 번째는 static data set에 대하여 인간의 개입 없이 모델의 성능을 비교하는 방식이다. 총 804개의 블로그 글을 대상으로 아래와 같이 여러 개의 모델의 성능을 비교하였다. 본 연구에서 제안한 Model 8의 F1 score가 가장 높게 나타났다.
두 번째 성능 평가를 위해서 실제 상황에서 사람이 모델을 사용하는 것의 유용성을 평가하였다. 참여자들은 금전적인 보상을 대가로 정서적 불안이 나타나는 게시글을 탐색한다. 단순 검색 엔진을 사용하는 방식과 KAREN의 결과를 사용하는 방식을 비교하였는데, 후자의 방식이 정서적 불안이 있는 게시글을 더 많이 탐지하는 것으로 나타났다. 또한 참여자들도 KAREN에 대한 유용성을 높게 평가한 것으로 나타났다.
📚 장점 및 의의
• 이 연구는 정보시스템, 컴퓨터 사이언스, 심리학 여러 도메인에 걸친 주제를 다뤘다. 서로 다른 도메인을 융합해서 연구를 진행했다는 점에서 연구 아이디어가 창의적이라는 생각이 들었다. 특히, 다양한 도메인 지식을 반영하는 과정에서 머신러닝 자체로는 한계가 있다는 점을 고려하여 rule-based model을 결합한 것이 인상적이었다. 특히 Rule-Based 모델을 제안하는 과정에서 전문가들이 정서적 불안이 있는 게시글을 검토하여 직접 어휘사전을 구축하였다. 단순히 긍정, 부정 단어의 수를 통해서 sentence score를 계산한 것이 아니라 self-reference 단어에 비중을 두는 등 정서적 불안과 실제로 관련이 있는 단어들을 정교하게 고려하고자 하였다.
• 모델의 성능을 확인하기 위해서 다양한 구조의 모델과 비교를 실시하였고, 다방면으로 robustness check를 진행하였다. 기존 연구처럼 모델 성능 평가 과정에서 데이터에 대한 알고리즘의 정확도 비교만 실시한 것이 아니라, 실제 사용 환경을 고려한 테스트를 진행했다는 점이 인상깊었다. 또한 misclassification 문서에 대해서도 질적인 분석을 진행해서 결과에 대한 설명력도 확보하였다.
📚 한계점 및 추가 연구 아이디어
• 이 연구에서는 aggregation model의 한 부분으로 SVM 알고리즘을 사용해서 게시글을 분류하였다. 본문에서 SVM을 사용한 이유가 기존 텍스트 분석 분야에서 성능이 뛰어났기 때문이라고 설명했지만, 최근에는 Transformer, BERT와 같이 뛰어난 텍스트 처리 성능을 보인 사전학습 모델이 많이 제시되었다. 이러한 모델을 사용했다면 모델의 정확도를 보다 개선시킬 수 있었을 것이다.
• Robustness Check 부분에서 문서의 길이/부정단어의 비율/긍정단어의 비율 등 다양한 조건에 따른 성능 비교한 것은 이 논문의 장점이라고 생각한다. 하지만, 여러 조건에 따라서 Aggregation Model과 SVM Only Model의 성능이 일관되지 않게 나타나서, 모델의 신뢰도, 일반화 가능성에 대한 의문이 들었다.




댓글