📚 Decision Tree
DT는 기본적으로 독립변수 값에 따라서 종속변수를 값이 유사한 여러 개의 그룹으로 분리하고, 각 그룹에 속한 관측치들을 모두 동일한 값으로 예측한다. DT는 종속변수를 그룹으로 나누기 위해서 데이터 포인트를 트리 구조로 분리한다.
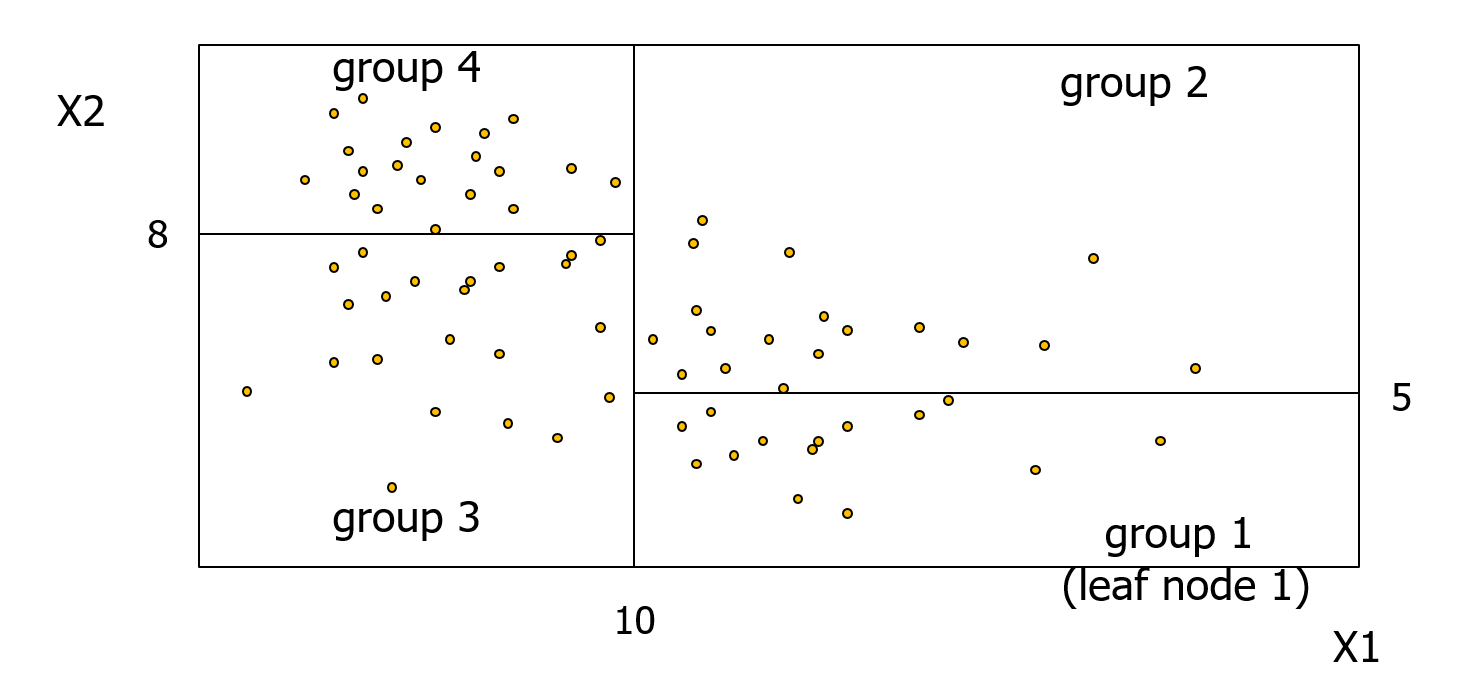
DT는 회귀문제와 분류문제 모두에 사용할 수 있다. DT는 독립변수를 이용해서 각 데이터 포인트를 그룹으로 묶고, 각 그룹에 모두 동일한 값을 할당하여 리턴한다. 회귀문제는 각 그룹 종속변수의 평균값을 사용하고, 분류문제는 각 그룹의 최빈값을 사용한다.
✅ 노드를 분류하는 기준?
기본적으로 각 노드에서 split을 했을 때, 발생하는 error의 정도를 최소화 하는 방향으로 split 한다. 여기서 회귀문제와 분류문제에서는 error의 정도를 계산하는 방법이 다르다.
📌 1. 회귀문제
회귀문제에서는 노드를 나눈 이후에 각 그룹의 RSS(Sum of Residual Squares) 사용한다. RSS는 잔차 제곱의 합을 의미한다.

예를 들어 아래와 같이 Xj 노드를 기준으로 split하는 경우에

DT는 group1, group2 각각을 그룹끼리는 모두 동일한 값을 예측한다. 학습 데이터에는 각 데이터 포인트의 실제 종속변수 값이 포함되어 있으므로, 그룹 내에서 예측값과 실제값의 오차를 계산할 수 있다. DT는 아래와 같이 각 그룹의 RSS를 최소화 하는 방향으로 split을 진행한다.
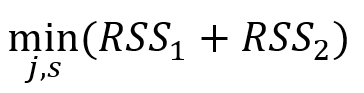
여기서 노드를 나누는 기준이 되는 s 값을 정하는 방식은 연속형/범주형인 경우에 따라서 다르다.
(1) 연속형 변수
연속형 변수인 경우에는 내림 또는 오름차순으로 정렬한 후에, 바로 이웃하는 두 개의 값의 평균을 우선적으로 테스트 해본다.
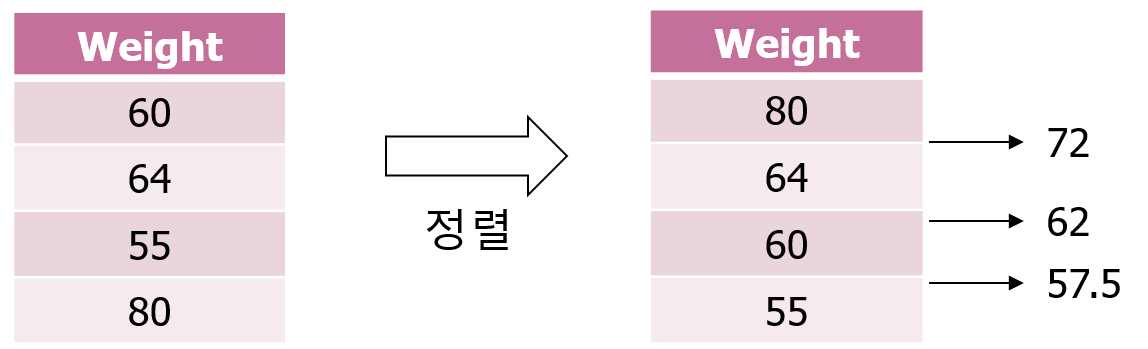
weight라는 변수가 있을 때 이를 우선 정렬한다. 그리고 80과 64의 평균인 72, 64와 60의 평균인 62, 60과 55의 평균인 57.7를 우선 각 노드의 분류값으로 테스트한다. 즉 s=72, 62, 57.5 일때 (RSS1 + RSS2) 값을 모두 계산하고 이를 최소화하는 값을 노드 분류 기준으로 선택한다.
(2) 범주형 변수
범주형 변수의 경우 중간의 값을 그대로 사용한다.
📌 2. 분류문제
분류문제에서는 각 그룹의 오차를 계산하기 위해서 Gini Index / Entropy를 사용한다. 두 지표 모두 특정한 그룹에 대해서 종속변수가 갖는 불확실성을 의미한다.
🏷️Gini Index

k = 종속변수가 취할 수 있는 값의 수

예를 들어 group1에 종속변수가 위와 같이 구성되어 있을 때(k=3)
group1에 대해서 gini index를 계산하면
P^1,0 = 3/10
p^1,1 = 3/10
p^1,2 = 4/10
이므로
G = ( 3/10 * 7/10 ) + ( 3/10 * 7/10 ) + ( 4/10 * 6/10 )
지니 인덱스는 불확실성을 나타내며, G 값이 작을수록 불확실성이 작은 것을 의미한다.
한 그룹의 종속변수 값이 모두 같으면 지니 인덱스는 불확실성이 가장 적은 상태인 0이 된다.
🏷️ Entropy

지니 인덱스와 마찬가지로 불확실성이 커지면 엔트로피 값이 커진다. 가장 불확실성이 낮은 상태의 엔트로피 값은 0이다.
지니인덱스와 엔트로피 두 값 모두 impurity (or heterogeneity / uncertainty) 정도를 의미한다. 즉 각 그룹에서 동일한 class의 points가 많을 수록 값이 작아진다. 둘 중에서 지니 인덱스가 계산이 조금 더 빠르게 때문에 더 많이 사용된다.
✅ 사이킷런에서 DT 주요 파라미터
• criterion : gini or entropy 사용
• max_depth : maximum depth of the tree. 값이 커질수록 모델의 복잡도가 증가해서 과적합 가능성 증가
• min_samples_split : minimum number of data points a decision node must have before it can be split
값이 클수록 해당 노드가 더 이상 분리되지 않을 가능성이 높으며, 값이 작을수록 해당 노드가 더 세부적으로 분리될 수 있어서 값이 작을수록 모형의 복잡도가 커진다.
• min_samples_leaf : minimum number of data points a leaf node must have
한 노드를 나눴을 때 아래에 생기는 두 개의 노드에 포함되어야 하는 최소한의 샘플 수. 값이 작을수록 모델의 복잡도가 증가함
• max_leaf_nodes : maximum number of leaf nodes
하나의 DT가 가질 수 있는 리프 노드의 최대 숫자. 값이 커질수록 모델 복잡도가 증가함
✅ DT 해석하기
📌 분류문제

• 처음 노드 : 전체 데이터의 지니계수는 0.5이고, 샘플은 70개이다. y=0인 샘플이 36개, y=1인 샘플이 34개가 있다.
X[1] 변수가 1.75 일 때를 기준으로 아래 두개의 노드로 분류함. 이렇게 해야 error 정도의 가장 작아지기 때문.
• 2번줄 왼쪽 : X[1] < 1.75인 샘플들만 모여있는 그룹. 샘플 수는 38개이고 이 그룹의 지니 계수는 0.1이다.
y=0인 샘플이 36개로 많기 때문에 이 그룹은 모두 0으로 분류된다.
📌 회귀문제

회귀문제의 경우 각 그룹마다 mse가 표시된다. 회귀 문제에서는 각 그룹에서 샘플들의 원래 종속변수의 값의 평균을 예측치로 사용한다.
📚 Reference
이상엽, 연세대학교 언론홍보영상학부 부교수, 22-1학기 기계학습 이론과 실습
'머신러닝, 딥러닝 > 머신러닝' 카테고리의 다른 글
| 앙상블 기법(Ensemble Method) - Boosting (0) | 2022.05.28 |
|---|---|
| 앙상블 기법(Ensemble Method) - Bagging (0) | 2022.05.24 |
| 나이브 베이즈 (Naive Bayes) (0) | 2022.05.15 |
| 영화리뷰 감성분석 (Sentiment Analysis) (0) | 2022.05.15 |
| TF-IDF (Term Frequency - Inverse Document Frequency) (0) | 2022.05.15 |



댓글