📚 Bagging (Bootstrap Aggregating)
일반적으로 단일 weak learner를 사용하면 충분한 성능을 확보하기 어렵다. 따라서 앙상블 기법(Ensemble method)은 여러 개의 weak learner를 결합하여 stronger learner를 생성한다. 앙상블 방법에는 Bagging과 Boosting이 있다. 이 포스트에서는 Bagging 방식에 대해서 정리한다.

배깅은 학습 데이터에서 sub-sampling을 진행해서 여러 개의 하위 샘플을 생성하고, 각 샘플들에 대해서 DT를 만들어서 예측을 진행하고 결과를 종합한다. 여러 개의 모델을 결합하기 때문에 과적합 가능성이 감소하고 모델의 일반화 가능성이 증가한다는 장점이 있다. 대표적으로 Random Forest 기법이 배깅 방식에 속한다.
✅ sub sampling 방식

일반적으로 sub sample의 사이즈와 원본 데이터의 사이즈는 동일하게 설정한다. (subsample size = size of original data)
서브 샘플링 시에는 중복 추출이 허용된다. 예를 들어, 원래 데이터에 10개의 관측치가 있다면 10개 중에서 3분의 2 가량인 6~7개 정도의 샘플을 중복으로 추출해서 하나의 서브 샘플을 구성한다.
✅ 최종 예측값을 산출하는 방법 - Voting
회귀 문제에서 최종 예측값을 결정할 때에는 각 서브 샘플에서 예측된 값의 평균을 사용한다. 분류 문제에서는 최빈값을 사용하거나 확률 값을 사용하는데 이를 voting이라고 부른다. voting 방식은 크게 두 가지가 존재한다.
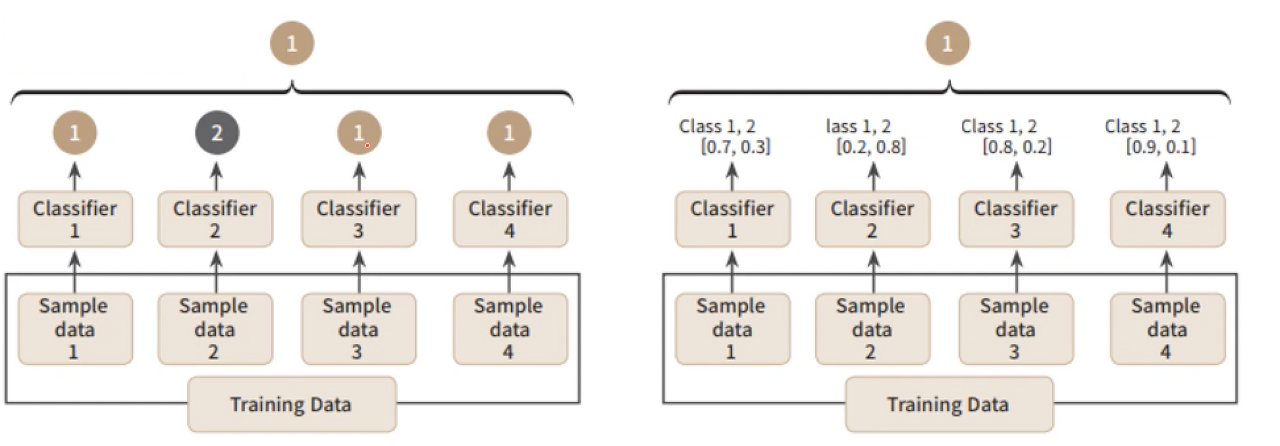
📌Hard Voting
왼쪽 그림처럼 각 서브샘플에서 예측된 값을 종합하고 최빈 값으로 최종 예측값을 결정함
📌Soft Voting
오른쪽 그림처럼 각 서브샘플에서 0,1이 될 확률을 계산하고, 각 확률을 더해서 최종 예측값을 결정함
✅ 예시
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(DecisionTreeClassifier(max_depth=2), n_estimators=1000)
bag_clf.fit(X_train, y_train)
y_preds = bag_clf.predict(X_test)Python에서는 BaggingClassifier라는 객체 안에 weak learner를 넣어서 간단하게 사용할 수 있다. 여기서는 weak learner로 DT를 사용했다. n_estimators는 sub sample의 갯수를 의미한다. 따라서 위의 코드는 1000개 서브 샘플을 생성하고 분류 결과를 종합한다.
✅Bagging의 한계
① 각 서브 샘플을 구성할 때 중복추출을 하기 때문에 샘플의 특징이 유사하다.
② 각 decision node를 분리할 때 모든 feature를 고려해서 에러를 계산한다.
→ 위의 이유로 각 서브 샘플에 대해서 weak learner로 학습했을 때 변수의 중요도가 유사하게 나타난다(=각 서브샘플의 DT의 노드에서 분류 기준이 되는 변수가 유사하다). 중요도가 낮은 변수들은 다수의 서브 샘플을 생성하더라도 학습에 반영되지 않고, 여러 개의 weak learner가 유사한 형태를 가지게 된다. 이는 결과적으로 전체 모델의 일반화 가능성을 저하시키고 과적합을 증가시킨다. 이러한 문제를 보완한 방식이 Random Forest이다.
✅ Random Forest 기법

랜덤포레스트는 bagging 방식으로 학습하면서 dicision node 를 분리할 때 모든 feature가 아니라 랜덤하게 일부의 feature만을 사용한다. 따라서 위의 그림처럼 각 subset의 노드에서 사용되는 피쳐가 다르게 나타날 수 있게된다.

사이킷런 공식 문서를 살펴보면 위와 같이 노드를 나눌 때 고려하는 변수의 수를 설정할 수 있다. 일반적으로 전체 피쳐가 P개일 경우에(max_features=auto) 루트 P개의 피쳐를 선택해서 사용한다.
📌oob_score

일반적인 bagging 에서는 전체 데이터에서 3분의 2정도의 샘플을 서브 샘플을 만들 때 사용한다. OOB(Out of Bag)sms 각 sub-sample에 포함되지 않은 관측치를 의미하는데, Random Forest에서는 이를 이용하여 테스트를 진행할 수 있다.
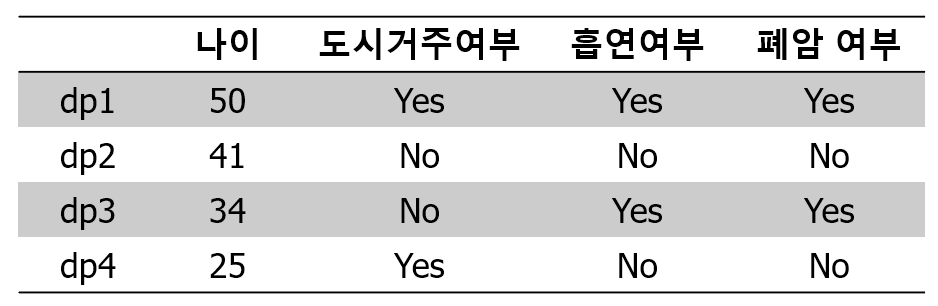
위와 같이 총 4개의 데이터 포인트(dp)가 있는 경우에, sub-sample 1에 dp1, dp1, dp2, dp3이 뽑혔다고 가정하자. 그러면 sub-sample에 대한 oob data point는 dp4가 된다. 마찬가지로 sub-sample 2, 5에 대해서도 dp4가 포함되지 않았다고 하면 dp4는 각 서브 샘플의 oob 포인트가 된다. 랜덤 포레스트에서는 각 서브샘플마다 weak learner를 생성하고 예측하는데, sub-sample 1,2,5의 학습기로 dp4에 대해서 예측한 결과가 아래와 같다고 하자.

분류 문제이기 때문에 dp4의 최종 예측값은 No로 결정된다. dp가 더 많을 경우 이 방식으로 dp4가 아닌 다른 oob data point에 대해서도 동일하게 예측 작업을 수행한다. 모든 oob dp에 대해서 예측을 실시하고 아래와 같이 정확도를 계산하면 oob score를 구할 수 있다.

rnd_clf1 = RandomForestClassifier(n_estimators = 100, oob_score=True)
rnd_clf1.fit(X, y)
rnd_clf1.oob_score_위와 같이 간단하게 oob score를 확인할 수 있다.
📚 Reference
https://velog.io/@jiselectric/Ensemble-Learning-Voting-and-Bagging-at6219ae
https://en.wikipedia.org/wiki/Bootstrap_aggregating
H. Guo et al. (eds.), Manual ofDigital Earth, https://doi.org/10.1007/978-981-32-9915-3_10
https://en.wikipedia.org/wiki/Boosting_(machine_learning)
'머신러닝, 딥러닝 > 머신러닝' 카테고리의 다른 글
| 차원축소 기본 - 고유값, 고유벡터, 고유분해 (0) | 2022.05.29 |
|---|---|
| 앙상블 기법(Ensemble Method) - Boosting (0) | 2022.05.28 |
| 의사결정나무 (Decision Tree) (0) | 2022.05.24 |
| 나이브 베이즈 (Naive Bayes) (0) | 2022.05.15 |
| 영화리뷰 감성분석 (Sentiment Analysis) (0) | 2022.05.15 |



댓글