◈ 개념
• 작동 방식이나 개념이 상대적으로 이해가 쉬워서, 가장 빈번하게 사용되는 알고리즘 중 하나이다.
• Make no assumptions about data. 즉, data-driven 성격이며 model-driven이 아니다.
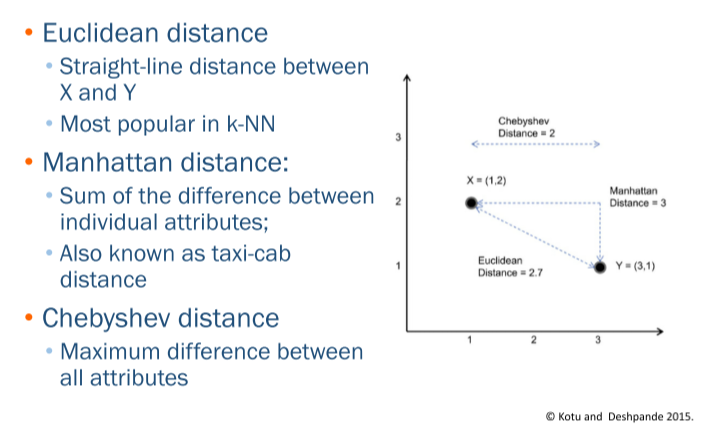
• 거리를 계산하는 방식은 여러가지가 있지만, 주로 Euclidean / Manhattan / Chybyshev distance 를 사용한다.
• 계산에 사용하는 predictor 변수의 스케일 차이가 많이 나면, 거리 계산이 올바로 되지 않을 수 있으므로 정규화(normalize)를 실시하는 것이 적절하다.
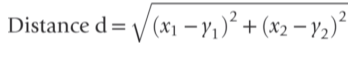
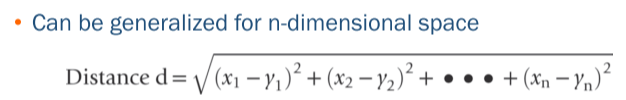
• 아래 예제에서 Manhattan은 2+1=3, Chybyshev은 2로 계산된다.
◈ 장점
• 데이터셋이 크고, 각 클래스가 multiple combinations of predicgtor values를 가지고 있을 때, 성과가 뛰어나다.
• No assumption required, 매우 심플하다
• 특정한 statistical model이 없이도 변수들 간의 complex interaction을 포착할 수 있다.
◈ 단점
• input-output 관계를 정확하게 파악할 수 없다. (변수 중요도에 대한 인사이트 파악 어렵다)
• 신뢰할 수 있는 결과를 확보하기 위해서는, 학습용 데이터의 수가 많이 확보되어야 한다. 그런데, 데이터가 클 경우에 학습하는 데에 시간이 많이 소요된다. 최근에는 모든 데이터 포인트를 계산하지 않고도 거리를 도출하는 기법이 있다고 하니 추가 학습이 필요함
• Predictor가 너무 많으면 → Curse of dimensionality
머신러닝에서 나타나는 전통적인 이슈이며, PCA 등을 이용한 차원 축소가 필요함
◈ 최적의 K 선정하는 기준?
• K : number of neraby neighbors to be used to classify the new record
• KNN 에서는 vadlidation을 사용하여 이를 검증하고, 별도로 test set을 holdout 하는 게 적절하다
• K가 작으면, 데이터의 local structure를 잘 포착할 수 있지만 왜곡이 발생할 수 있다.
반면, K가 크면 보다 smoothing & less noise라는 장점이 있지만 local structure를 포착하지 못할 수도 있다.
◈ 예제 실습 : Lawn Mower Example (Classification)
잔디깍이 기계 예제를 사용하여 간단한 R코드 KNN 실습을 진행하였다.
✅ 데이터 불러오기 및 train/valid/test 분리
#load data
mower.df <- read.csv("RidingMowers.csv", na.strings = "")
# convert the data type for Ownership
mower.df$Ownership <- factor(mower.df$Ownership)
spl <- sample(c(1:3),
size=nrow(mower.df),
replace=TRUE,
prob=c(0.6,0.2,0.2)) #1,2,3으로 뽑힐 확률을 각각 지정
train.df <- mower.df[spl==1,]
valid.df <- mower.df[spl==2,]
test.df <- mower.df[spl==3,]•데이터를 불러오고 train/validation/test 분리를 실시한다. 정제되어 있는 형태로 배포된 데이터여서, 변수 유형 변환 외에 별도의 전처리가 필요 없다. 최적의 K 수를 탐색하는데 사용하기 위하여 valid 데이터 셋을 별도로 분리한다.
✅ 예시 데이터 생성
# 예측할 예시 데이터 생성
new.df <- data.frame(Income = c(60,80,75), Lot_Size = c(20,25,55))
# 그래프 그리기
plot(Lot_Size ~ Income, data = train.df, pch=ifelse(train.df$Ownership == "Owner", 1, 3))
text(train.df$Income, train.df$Lot_Size, rownames(train.df), pos = 4)
text(60, 20, "X")
legend("topright", c("owner", "non‐owner", "newhousehold"), pch = c(1, 3, 4))
•예측값을 도출할 임의의 데이터를 데이터 프레임 형태로 생성한다. 그리고 이 데이터의 경우 변수가 2개 이기 때문에, 2차원으로 시각화를 하여 전체 분포를 파악하는 것이 가능하다.
✅ 데이터 전처리 : 정규화
## 데이터 정규화
#데이터 복사
train.norm.df <- train.df
valid.norm.df <- valid.df
test.norm.df <- test.df
#caret 패키지의 preprocess 함수 이용
library(caret)
norm.values <- preProcess(train.df[ , 1:2], method=c("center", "scale"))
#복사된 데이터의 값을 정규화된 값으로 대체
train.norm.df[, 1:2] <- predict(norm.values, train.df[, 1:2])
#train 데이터의 center, scale 값으로 정규화 실시
valid.norm.df[, 1:2] <- predict(norm.values, valid.df[, 1:2])
test.norm.df[, 1:2] <- predict(norm.values, test.df[, 1:2])• 각 변수에 대한 정규화를 실시한다. 이때 Train 데이터의 값을 기준으로 valid/test 에서 정규화를 실시한다. KNN 은 거리를 기준으로 계산하기 때문에, 각 변수의 scale이 다를 경우 제대로 된 값을 계산하지 못한다. 따라서 정규화는 필수로 실시
✅ 최적의 K 값 확인
library(FNN)
library(class)
#빈 df 생성
accuracy.df <- data.frame(k = seq(1, 10, 1), accuracy = rep(0, 10))
#k 값 1~10까지 루프로 확인
for(i in 1:10){
knn.pred <- class::knn(train = train.norm.df[, 1:2],
test = valid.norm.df[, 1:2],
cl = train.norm.df[, 3],
k = i)
accuracy.df[i, 2] <- confusionMatrix(as.factor(knn.pred), as.factor(valid.norm.df[,3]))$overall[1] #overall[1] 은 accuracy만 뽑아내는 것
}
accuracy.df• Class 패키지는 예측 클래스만 확인할 수 있지만, FNN 패키지는 예측 결과를 포함하여 여러 정보를 함께 제공한다.
최적의 k 값을 확인하기 위해서 validation set을 사용한다. k 값을 1부터 10까지 사용해서 결과를 확인하고, accuracy.df에 저장한다. 정확도와 이웃수를 고려하여 k=4로 선정했다.
✅ test 데이터 예측
knn.pred.test <- class::knn(train = train.norm.df[, 1:2],
test = test.norm.df[, 1:2],
cl = train.norm.df[, 3],
k = 4)
knn.pred.test
confusionMatrix(as.factor(knn.pred.test), as.factor(test.norm.df[,3]))•test set에 대해서 예측을 실시하고, confusion matrix를 확인한다.
✅ 새로운 데이터 예측
#정규화
new.norm.df <- predict(norm.values, new.df)
nn.reuslt2 <- FNN::knn(train = train.norm.df[, 1:2],
test = new.norm.df,
cl = train.norm.df[, 3],
k = 4)
nn.reuslt2
##이웃 데이터 확인하기
attr(nn.reuslt2, 'nn.index') #k에 해당하는 데이터의 인덱스
name <- row.names(train.df)[attr(nn.reuslt2, 'nn.index')]
matrix(name, nrow=3, ncol=4,byrow=FALSE) #매트릭스로 제시•앞서 임의로 생성한 new.df에 대해서도 정규화 실시 후 예측을 실시한다. FNN 패키지를 이용하면, 주변 이웃이 어떤 데이터인지 확인할 수 있다. attr( , 'nn.index')에서 출력되는 값은, 이웃 데이터의 index이므로 유의.
◈ 실습 예제 : Boston Housing price Prediction
입문 단계에서 많이 사용되는 데이터셋인 Boston House Price 데이터를 사용한다. 보스턴 지역의 주택에 대한 정보가 포함되어 있고, 각 주택의 가격을 예측하는 용도로 사용할 수 있다. 데이터는 506 x 14 로 굉장히 작다.
✅ 데이터 불러오기 및 Train/Test 분리
library(MASS)
data(Boston)
housing.df <- Boston
# train/test 분리
train.index = sample(1:nrow(housing.df), 0.6*nrow(housing.df))
train.df = housing.df[train.index, ]
valid.df = housing.df[-train.index,R의 MASS 패키지를 이용해서 데이터를 불러오고, train/test split을 실시한다.
✅ 전처리 : 정규화
#데이터 복사
train.norm.df <- train.df
valid.norm.df <- valid.df
housing.norm.df <- housing.df
#데이터 정규화 실시
library(caret)
norm.values <- preProcess(train.df[, -14], method=c("center", "scale"))
train.norm.df[, -14] <- predict(norm.values, train.df[, -14])
valid.norm.df[, -14] <- predict(norm.values, valid.df[, -14])Caret 패키지의 preprocess 함수 사용하여 변수 정규화를 실시한다. 이때, train 데이터의 값을 기준으로 정규화를 실시한다는 것을 유의한다.
✅ Test 데이터 예측
#KNN으로 예측 실시
library(FNN)
pred5 = knn.reg(train = train.norm.df, test = valid.norm.df, y = train.norm.df[,14], k = 5)
pred5
#RMSE 계산
RMSE(pred5$pred, valid.df$medv)
분류 문제에서는 knn()을 사용할 때, cl 파라미터를 입력한다. 예측의 경우 knn.reg() 을 사용하고, cl 대신 y 파라미터를 입력한다.
✅ 새로운 값 예측
#새로운 데이터값 생성
new.rec <- data.frame(0.2, 0, 7.2, 0, 0.538, 6.3, 62, 4.7, 4, 307, 21, 10, 31)
new.rec
dim(new.rec)
names(new.rec) <- names(train.norm.df)[-14]
new.norm.rec <- predict(norm.values, new.rec)
knn.pred <- knn.reg(train = train.norm.df[,-14], test = new.norm.rec, y = train.df$medv, k = 3)
knn.pred모델에 새로운 데이터 값을 임의로 생성해서 입력해볼 수 있다. 첫 번째 라인에 변수 순서대로 한 row를 만들고, 정규화를 실시한 후에 동일한 방식으로 예측할 수 있다
◈ 자료 출처
Data Mining for Business Analytics: Concepts, Techniques, and Application in R" by R, Galit Shmueli, Peter C. Bruce, Inbal Yahav, Nitin R. Patel, Kenneth C. Lichtendahl Jr. Wiley. 1st edition. Wiley, 2017.
'머신러닝, 딥러닝 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 선형회귀 (Linear Regression) (0) | 2022.03.14 |
|---|---|
| [머신러닝] 지도학습 / 경사하강법 / 규제화 (0) | 2022.03.07 |
| [머신러닝] 클러스터링(Clustering) (0) | 2021.12.01 |
| [머신러닝] Decision Tree (0) | 2021.10.13 |
| [머신러닝] Naive Bayes 개념 정리 (0) | 2021.10.08 |




댓글