📚 논문 정보

Kim, J., Lee, Y., & Song, I. (2021). From intuition to intelligence: a text mining–based approach for movies' green-lighting process. Internet Research.
📚 요약
•
본 연구에서는 본격적인 영화 제작 여부를 결정하는 green lighting 단계에서 영화의 흥행 여부를 예측하는 머신러닝 모델을 제시하였다. 이 연구의 기본 아이디어는 영화 스크립트의 텍스트를 이용해서 영화 흥행과 관련된 유용한 정보들을 추출할 수 있다는 것이다. 이를 위해서 영화 스크립트 데이터에서 LDA를 실시해서 잠재 요소들을 추출하였다.
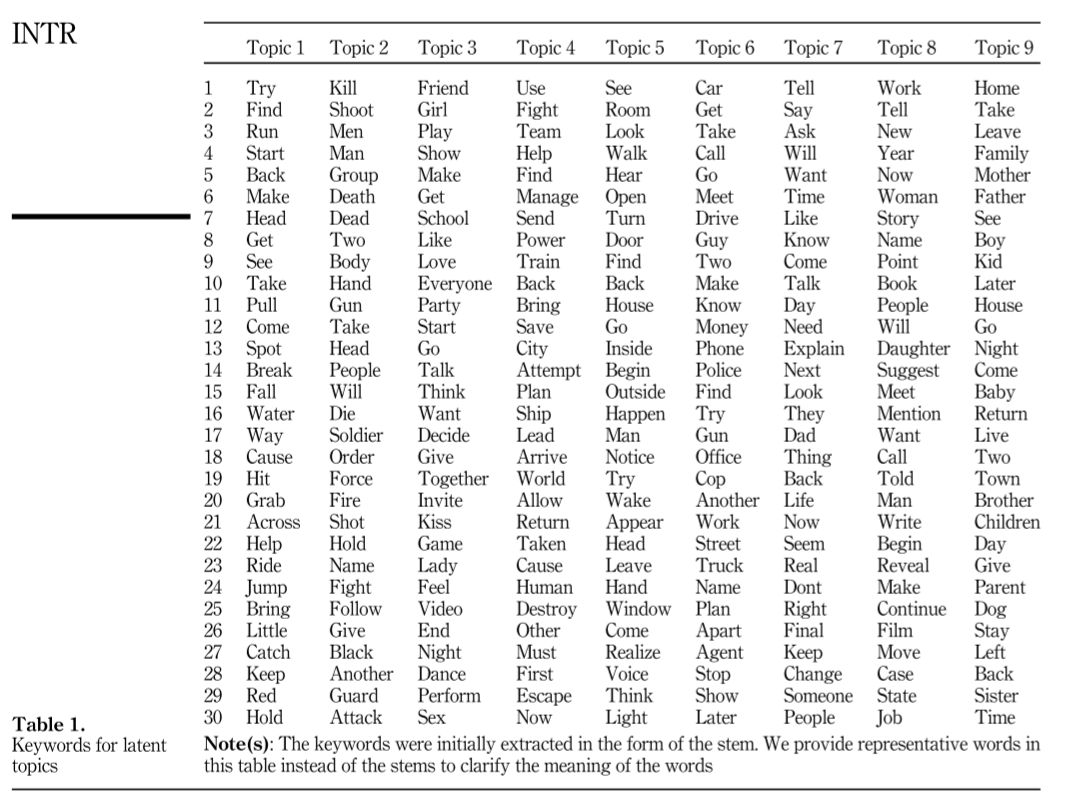

토픽의 개수는 elbow method를 이용하여 9개로 선정하였고, 각 토픽의 주요 키워드를 통해서 토픽을 해석하였다. 토픽모델링은 항상 해석이 애매한 경우가 많은데 이 연구에서는 해당 토픽에 속하는 영화들과 연관지어서 합리적으로 토픽을 설명하였다. 하지만 한편으로는 기존에 영화 장르 구분과 크게 다른 점이 있는가? 하는 의문도 들었다. 일부 토픽들은 결국 기존의 영화 장르인 모험, 액션, 가족 등과 매우 유사하다는 생각이 들었다.
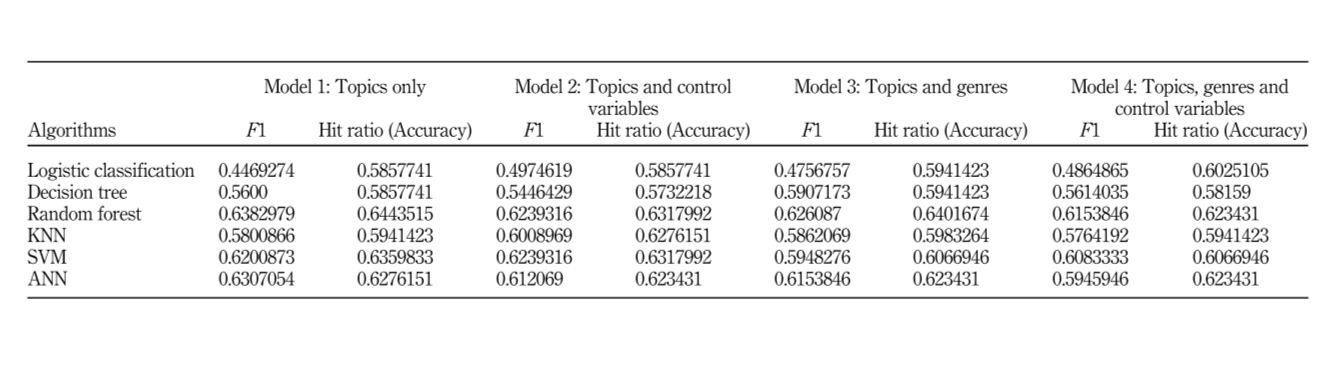
머신러닝 모델 구축 과정에서는 각 영화 스크립트가 잠재 토픽으로 할당될 확률을 topic variables로 사용해서 흥행여부를 예측했다. 모델 학습 시 종속변수는 ROI를 사용하였고, 중위수를 기준으로 성공/실패 변수로 가공해서 분류 문제로 학습했다. 사용한 분류 알고리즘은 Logistic Regression, Decision Tree, Random Forest, KNN, SVM, ANN이고 4가지 모델을 비교하였다.
실험 결과 LDA 변수만을 이용해서 학습한 Model 1에서 Random Forest 알고리즘을 사용했을 때 가장 높은 F1 score와 accuracy를 달성했다. 따라서 영화 흥행 여부를 판단할 때 스크립트의 hidden textual structure information이 유용하게 사용될 수 있다는 것을 확인했다.
📚 장점 및 의의
• 영화의 흥행 예측은 기존 연구 및 분석 사례가 많아서 차별점이 부족할 수도 있다고 생각했는데, 이 연구에서는 pre production 단계에서 성공 여부를 예측했다는 점에서 실무적인 기여점이 아주 크다고 생각한다.
• 실제 영화의 스크립트를 연구에 사용하기에는 데이터 수집의 한계가 있기 때문에 이 연구에서 영화 리뷰 사이트의 줄거리 요약 텍스트를 사용하여 분석을 진행하였다. 실제로 아이디어를 연구로 구체화하는 단계에서 사용가능한 데이터가 없어서 난감한 경우가 많았는데, 이 연구에서 데이터를 사용한 방식처럼 합리적이고 유연하게 데이터를 수집하고 다루는 것이 필요하다는 생각이 들었다.
• Mode 1 ~ Model 4의 성능을 비교하는 과정에서 더 많은 변수를 학습한 Model 4의 성능이 높게 나올 것이라고 생각하였다. 하지만 이 연구에서는 LDA 변수만을 사용한 Model 1의 성능이 뛰어났다는 점에서 의외의 결과가 도출된 점이 흥미로웠다. 또한 Logistic Regression을 이용해서 모델에 대한 추가적인 설명력도 제공하였다.
📚 한계점 및 추가 연구 아이디어
• 이 연구에서는 선행 연구 중에서 유사한 방식으로 영화의 스크립트 데이터를 Bag of words로 분석한 사례(Eliashberg et al. 2007)를 참고하였고 연구 전반에 걸쳐서 비교하였다. 이 연구에서는 LDA를 사용한 것이 차별점이라고 주장하지만, 단순히 사용한 텍스트마이닝 기법이 BoW에서 LDA로 바뀐 것 이외에 차별점이 부족하다는 비판도 가능하다. LDA를 사용해서 예측 성능을 향상시키고 다양한 해석을 제공한 것이 이 연구의 장점인데, 이것이 연구 자체의 아이디어나 구조적 참신성이 아니라 사용한 텍스트 마이닝 기법의 특성 때문이라는 비판이 가능하다.
• 이 연구에서는 종속변수로 해당 영화의 ROI를 사용하였고, 중위수를 기준으로 성공/실패 변수를 생성해서 이진 분류 문제로 모델을 학습했다. 하지만 개별 영화에 대해서 ROI수치를 회귀 문제로 예측하지 않고 분류 문제를 해결한 부분에 대해서 충분한 설명이 제공되지 않았다고 생각한다. 본 연구에서 제시한 LDA 변수들이 충분한 설명력을 가지고 있다면, 회귀 모델로 개별 영화의 구체적인 ROI를 예측할 수 있을 것이고 이를 통해서 보다 효용성 있는 모델을 제시할 수도 있다.
• 분류 모델의 성능 평가 부분에서, LDA에서 추출한 변수만을 사용한 Model 1. 중에서 Random Forest 알고리즘이 F1 score= 0.63, 정확도=0.64로 가장 높은 정확도를 보였다. LDA 변수를 사용한 모델이 효과적이라는 것은 의의가 있지만, 절대적인 정확도 수치가 상당히 낮다는 생각이 들었다. 정확도가 높지 않기 때문에 굳이 이 연구에서 제안한 것처럼 머신러닝을 이용해서 예측을 할 필요가 있는가? 라는 의문이 든다.




댓글