◈ 경영학-정보시스템 분야에서 데이터 사이언스
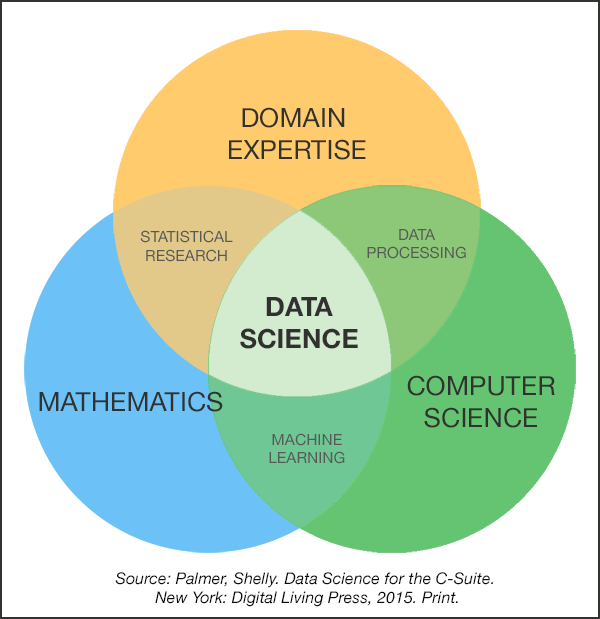
• IS 전공자이자, 데이터 분석가를 목표로 하는 입장에서, 요즘에는 가장 근본적인 질문에 대한 고민을 끊임없이 하고 있다. 데이터사이언스는 분야의 특성 상 여러 영역에 걸쳐있다보니, 사람마다 의견이 다른 경우도 많고 아직 합의된 의견이 도출되지 않은 부분도 있다.
• 이는 데이터 사이언스 전문가가 되기위해서는 그만큼 다방면의 지식이 필요하고, 이 지식을 활용하는 과정에서도 많은 고민이 필요하다는 의미이다. 단순히 기계적인 분석으로는 뛰어난 데이터 분석가가 될 수 없다는 것을 절실하게 느끼고 있다. 학부 때만 해도 IDE에 결과만 잘 출력되면 '내가 데이터 분석을 잘 배워가고 있구나' 생각했었는데, 정말 우물안 개구리 그 자체였다...
• 경영학의 Information system 전공은 크게 세 가지 세부 분야로 분류할 수 있다
→ ① Traditional IS(설문,실험) / ② Econometrix / ③ Techinical
③에서 주로 머신러닝/딥러닝을 다루는데, 이에 대한 의견은 같은 IS 전공 교수님마다 다 다른 것 같다.
머신러닝을 연구에 메인으로 사용하시는 분도 있고, 반대로 머신러닝 자체에 회의적이신 교수님도 있다. 심지어는 같은 IS 저널인데도, 저널마다 성격이 달라서 메인이 되는 세부 분야가 따로 있다.
◈ 머신러닝에 대한 비판 : 설명력 vs 예측력
경영학에서의 머신러닝에 대해서 제기되는 대표적인 비판은 아래와 같다.
비판 ) 머신러닝은 결국 샘플로 예측하느 것이기 때문에, out of sample에 대해서 제대로 예측할 수 없다.
특히 외부 충격이 강한 경우에는 정확도 기반 머신러닝/딥러닝은 의미가 없다. 결국 X,Y의 관계성이 중요하다.
• 학술적으로는 맞는 말이라고 볼 수 있다. 머신러닝은 관계를 모르더라도 결과만 잘 맞으면 되는 경우가 많다. 하지만 학문을 공부하는 과정에서는 why까지 알아내는 것이 중요하다.
• 머신러닝, 딥러닝은 기존 데이터에 패턴이 있다는 것을 가정하고 그것을 발견하는 과정인데, 이 가정 자체를 부정하고 질문하면 의미 있는 비판이라고 하기 어렵다는 주장도 있다. 사실 이 부분은 근본적으로 머신러닝/딥러닝에 대한 의견 차이가 있기 때문에 계속해서 문제가 제기되는 것 같다.
• 경영 데이터를 예측하는 것 자체가 구조적으로 잘못됐다고 볼 수 있다. 주가/유가/GDP 등 aggregated level 데이터는 어느 정도 추세를 파악할 수는 있지만, long-tail에 해당하는 항목을 예측하는 것은 의미가 없다. 예측을 위한 예측인 경우가 많고 이론적 적용도 힘든 경우가 많다. (당연이 이론은 generalization 기반이니까)
• 단순히 '이러이러한 전처리/알고리즘/구조 를 사용해서 모델 성능이 좋다' 로 분석이나 논문을 마무리 하는 것은 굉장히 공허한 주장임. 데이터 분석은 어디까지나 의사결정을 위한 수단이며 절대적인 것이 아니다.
→ 한 분야에 대해서 머신러닝으로 논문을 쓰려면 예측력은 기본이고 이에 대한 설명력이 확보되어야 함.
모두가 강조하지만 역시나 도메인이 중요함.

◈ 데이터 분석 vs 전문가의 인사이트
• 데이터가 충분하고 모든 변수들을 가지고 있다면 데이터 분석이 유의미 할 수 있다. 하지만 대부분의 경우, 데이터 양이 충분하지 않거나, 현상을 설명하는 변수가 부족하다. 이런 경우에는 다수의 노하우로 축적된 전문가의 인사이트가 더 효과적일 수 있다.
• 그래서 데이터 관련 업무도 한국에서는 아직까지 명확한 경계가 정립되지 않은 경우가 많다. 현직자 분들 인터뷰를 살펴보면 업무 내용과 요구되는 능력이 회사마다 다른 경우가 많다.
• 실제 현업에서는 '사람의 지식과 모델 사이의 앙상블이 필요하다'는 말도 있다. 한 쪽에 치우치기 보다는 둘을 적절하게 잘 활용하는게 최선이다. 그런 측면에서 경영학 전공자로서 분석 능력을 가지고 있는 것이 장점이 될 수 있다. 물론 둘 다 잘하기가 매우 어렵다는게 함정. 애초에 대학원을 인공지능대학원/데이터분석 과정이 아니라 경영학과 일반 대학원으로 진학할 때, 지도교수님께서 해주셨던 말씀과도 일치한다. 어떻게든 경계점을 잘 공략해야 한다.
◈ 결론
현재 까지의 결론은 다음과 같다
"경영학 분야에서 머신러닝을 사용하기 위해서는, 예측력은 기본으로 확보해야 하고 설명력까지 추가되어야 한다"
둘 중 어느 것에 중심을 둬야할 지에 대한 고민으로 시작했는데, 결국 둘 다 필요하다는 결론에 도달했다 ㅎㅎㅎ...
데이터 사이언스는 얕게 알면 간단해보이지만, 배우면 배울수록 어렵지만 재미있는 분야라는 생각이 든다.
채워야 할 부분이 많기에 막막하기는 하지만, 오늘도 Keep Going 정신으로 임해야겠다.
'데이터 분석 > 일반' 카테고리의 다른 글
| [2022. 01. 25] 데이터리안 웨비나 (0) | 2022.01.25 |
|---|---|
| .ipynb to .py 변환 방법 (0) | 2022.01.12 |
| 데이터 사이언스 현직자 인터뷰 정리 (0) | 2021.12.31 |
| [데이터분석 사례] 카지노 도박과 데이터 분석 (0) | 2021.12.22 |
| 데이터 사이언스 짤(memes) 모음 (0) | 2021.11.03 |



댓글